Databaser er designet på forskellige måder. Det meste af tiden kan vi bruge "skoleeksempler":normaliser databasen, og alt vil fungere fint. Men der er situationer, der kræver en anden tilgang. Vi kan fjerne referencer for at opnå mere fleksibilitet. Men hvad nu hvis vi skal forbedre ydeevnen, når alt blev gjort efter bogen? I så fald er denormalisering en teknik, som vi bør overveje. I denne artikel vil vi diskutere fordele og ulemper ved denormalisering, og hvilke situationer der kan berettige det.
Hvad er denormalisering?
Denormalisering er en strategi, der bruges på en tidligere normaliseret database for at øge ydeevnen. Tanken bag det er at tilføje overflødige data, hvor vi tror, det vil hjælpe os mest. Vi kan bruge ekstra attributter i en eksisterende tabel, tilføje nye tabeller eller endda oprette forekomster af eksisterende tabeller. Det sædvanlige mål er at reducere køretiden for udvalgte forespørgsler ved at gøre data mere tilgængelige for forespørgslerne eller ved at generere opsummerede rapporter i separate tabeller. Denne proces kan give nogle nye problemer, og vi vil diskutere dem senere.
En normaliseret database er udgangspunktet for denormaliseringsprocessen. Det er vigtigt at skelne fra databasen, der ikke er blevet normaliseret, og databasen, der først blev normaliseret og derefter denormaliseret senere. Den anden er okay; den første er ofte resultatet af dårligt databasedesign eller mangel på viden.
Eksempel:En normaliseret model til en meget simpel CRM
Modellen nedenfor vil tjene som vores eksempel:
Lad os tage et hurtigt kig på tabellerne:
user_accounttabel gemmer data om brugere, der logger ind på vores applikation (forenkling af modellen, roller og brugerrettigheder er udelukket fra den).kliententabel indeholder nogle grundlæggende data om vores kunder.produktettabel viser produkter, der tilbydes til vores kunder.opgaventabel indeholder alle de opgaver, vi har oprettet. Du kan tænke på hver opgave som et sæt af relaterede handlinger over for kunder. Hver opgave har sine relaterede opkald, møder og lister over tilbudte og solgte produkter.opkaldetogmødetabeller gemmer data om alle opkald og møder og relaterer dem til opgaver og brugere.- Ordbøgerne
task_outcome,meeting_outcomeogcall_outcomeindeholde alle mulige muligheder for den endelige tilstand af en opgave, møde eller opkald. - Det
produkt_tilbudtegemmer en liste over alle produkter, der blev tilbudt kunder på bestemte opgaver, mensprodukt_solgtindeholder en liste over alle de produkter, som kunden faktisk har købt. supply_ordertabel gemmer data om alle ordrer, vi har afgivet, ogproducts_on_ordertabel viser produkter og deres antal for specifikke ordrer.afskrivningen tabel er en liste over produkter, der er afskrevet på grund af ulykker eller lignende (f.eks. ødelagte spejle).
Databasen er forenklet, men den er perfekt normaliseret. Du vil ikke finde nogen afskedigelser, og det burde gøre arbejdet. Vi bør under alle omstændigheder ikke opleve problemer med ydeevnen, så længe vi arbejder med en relativt lille mængde data.
Hvornår og hvorfor skal man bruge denormalisering
Som med næsten alt, skal du være sikker på, hvorfor du vil anvende denormalisering. Du skal også være sikker på, at fortjenesten ved at bruge det opvejer enhver skade. Der er et par situationer, hvor du helt sikkert bør tænke på denormalisering:
- Vedligeholdelse af historik: Data kan ændre sig over tid, og vi skal gemme værdier, der var gyldige, da en post blev oprettet. Hvilken slags ændringer mener vi? Nå, en persons for- og efternavn kan ændre sig; en klient kan også ændre deres virksomhedsnavn eller andre data. Opgavedetaljer bør indeholde værdier, der var aktuelle i det øjeblik, en opgave blev genereret. Vi ville ikke være i stand til at genskabe tidligere data korrekt, hvis dette ikke skete. Vi kunne løse dette problem ved at tilføje en tabel, der indeholder historikken for disse ændringer. I så fald ville en udvalgt forespørgsel, der returnerer opgaven og et gyldigt klientnavn, blive mere kompliceret. Måske er et ekstra bord ikke den bedste løsning.
- Forbedring af forespørgselsydeevne: Nogle af forespørgslerne kan bruge flere tabeller til at få adgang til data, som vi ofte har brug for. Tænk på en situation, hvor vi skulle slutte os til 10 borde for at returnere kundens navn og de produkter, der blev solgt til dem. Nogle tabeller langs stien kan også indeholde store mængder data. I så fald ville det måske være klogt at tilføje et
client_idattribut direkte tilproducts_soldtabel. - Fremskyndelse af rapporteringen: Vi har meget ofte brug for visse statistikker. Det er ret tidskrævende at oprette dem fra live-data og kan påvirke systemets overordnede ydeevne. Lad os sige, at vi ønsker at spore kundesalg over bestemte år for nogle eller alle kunder. At generere sådanne rapporter ud fra live-data ville "grave" næsten gennem hele databasen og bremse den meget. Og hvad sker der, hvis vi bruger den statistik ofte?
- Beregning af almindeligt nødvendige værdier på forhånd: Vi ønsker at have nogle værdier færdigberegnet, så vi ikke behøver at generere dem i realtid.
Det er vigtigt at påpege, at du ikke behøver at bruge denormalisering, hvis der ikke er problemer med ydeevnen i ansøgningen. Men hvis du bemærker, at systemet er ved at sænke farten - eller hvis du er klar over, at dette kan ske - så bør du overveje at anvende denne teknik. Inden du går med det, skal du dog overveje andre muligheder, såsom forespørgselsoptimering og korrekt indeksering. Du kan også bruge denormalisering, hvis du allerede er i produktion, men det er bedre at løse problemer i udviklingsfasen.
Hvad er ulemperne ved denormalisering?
Den største fordel ved denormaliseringsprocessen er naturligvis øget ydeevne. Men vi skal betale en pris for det, og den pris kan bestå af:
- Diskplads: Dette forventes, da vi har dublerede data.
- Datanomalier: Vi skal være meget opmærksomme på, at data nu kan ændres mere end ét sted. Vi skal justere hvert stykke duplikerede data i overensstemmelse hermed. Det gælder også beregnede værdier og rapporter. Vi kan opnå dette ved at bruge triggere, transaktioner og/eller procedurer for alle operationer, der skal gennemføres sammen.
- Dokumentation: Vi skal korrekt dokumentere enhver denormaliseringsregel, som vi har anvendt. Hvis vi ændrer databasedesign senere, bliver vi nødt til at se på alle vores undtagelser og tage dem i betragtning igen. Måske har vi ikke brug for dem længere, fordi vi har løst problemet. Eller måske skal vi tilføje til eksisterende denormaliseringsregler. (For eksempel:Vi har tilføjet en ny attribut til klienttabellen, og vi ønsker at gemme dens historieværdi sammen med alt, hvad vi allerede gemmer. Vi bliver nødt til at ændre eksisterende denormaliseringsregler for at opnå det).
- Sænkning af andre handlinger: Vi kan forvente, at vi vil bremse dataindsættelse, ændring og sletning. Hvis disse operationer sker relativt sjældent, kan dette være en fordel. Grundlæggende ville vi opdele en langsom udvælgelse i et større antal langsommere indsæt/opdater/slet-forespørgsler. Selvom en meget kompleks udvælgelsesforespørgsel teknisk set kunne sænke hele systemet mærkbart, bør nedsættelse af flere "mindre" operationer ikke skade anvendeligheden af vores applikation.
- Mere kodning: Regel 2 og 3 vil kræve yderligere kodning, men samtidig vil de forenkle nogle udvalgte forespørgsler meget. Hvis vi denormaliserer en eksisterende database, bliver vi nødt til at ændre disse udvalgte forespørgsler for at få fordelene ved vores arbejde. Vi bliver også nødt til at opdatere værdier i nyligt tilføjede attributter for eksisterende poster. Dette vil også kræve lidt mere kodning.
Eksempelmodellen, denormaliseret
I modellen nedenfor anvendte jeg nogle af de førnævnte denormaliseringsregler. De lyserøde borde er blevet ændret, mens det lyseblå bord er helt nyt.
Hvilke ændringer anvendes og hvorfor?

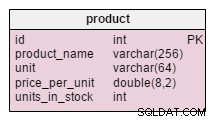
Den eneste ændring i produktet tabel er tilføjelsen af enheder_på_lager attribut. I en normaliseret model kunne vi beregne disse data som ordrede enheder – solgte enheder – (udbudte enheder) – enheder afskrevet . Vi ville gentage beregningen hver gang en kunde beder om det pågældende produkt, hvilket ville være ekstremt tidskrævende. I stedet beregner vi værdien på forhånd; når en kunde spørger os, har vi den klar. Dette forenkler naturligvis valgforespørgslen meget. På den anden side er enheder_på_lager attribut skal justeres efter hver indsættelse, opdatering eller sletning i products_on_order , afskrivning , product_offered og product_sold tabeller.
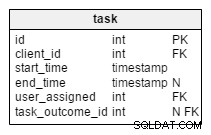
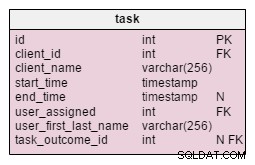
I den ændrede opgave tabel, finder vi to nye attributter:client_name og user_first_last_name . Begge lagrer værdier, da opgaven blev oprettet. Årsagen er, at begge disse værdier kan ændre sig over tid. Vi beholder også en fremmednøgle, der relaterer dem til den originale klient og bruger-id. Der er flere værdier, som vi gerne vil gemme, som kundeadresse, moms-id osv.




Det denormaliserede product_offered tabellen har to nye attributter, price_per_unit og pris . price_per_unit attribut gemmes, fordi vi skal gemme den faktiske pris da produktet blev tilbudt . Den normaliserede model ville kun vise sin nuværende tilstand, så når produktprisen ændrer sig, vil vores 'historie' priser også ændre sig. Vores ændring får ikke bare databasen til at køre hurtigere:den får den også til at fungere bedre. prisen attribut er den beregnede værdi enheder_solgte * price_per_unit . Jeg tilføjede det her for at undgå at lave den beregning, hver gang vi vil se på en liste over tilbudte produkter. Det er en lille omkostning, men det forbedrer ydeevnen.
Ændringerne foretaget på product_sold tabellen er meget ens. Tabellstrukturen er den samme, men den gemmer en liste over solgte varer.
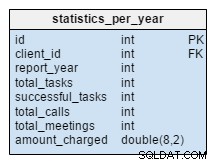
statistics_per_year bord er helt nyt for vores model. Vi bør se på det som en denormaliseret tabel, fordi alle dens data kan beregnes fra de andre tabeller. Ideen bag denne tabel er at gemme antallet af opgaver, vellykkede opgaver, møder og opkald relateret til en given klient. Det håndterer også den samlede sum opkrævet pr. år. Efter at have indsat, opdateret eller slettet noget i opgaven , møde , opkald og product_sold tabeller, bør vi genberegne denne tabels data for den pågældende kunde og det tilsvarende år. Vi kan forvente, at vi stort set kun vil have ændringer for indeværende år. Rapporter for tidligere år skulle ikke skulle ændres.
Værdierne i denne tabel er beregnet på forhånd, så vi bruger mindre tid og ressourcer i det øjeblik, vi har brug for beregningsresultatet. Tænk over de værdier, du ofte har brug for. Måske får du ikke regelmæssigt brug for dem alle og kan risikere at regne nogle af dem live.
Denormalisering er et meget interessant og kraftfuldt koncept. Selvom det ikke er den første, du bør have i tankerne for at forbedre ydeevnen, kan det i nogle situationer være den bedste eller endda den eneste løsning.
Før du vælger at bruge denormalisering, skal du være sikker på, at du ønsker det. Lav nogle analyser og spor ydeevne. Du vil sandsynligvis beslutte dig for at gå med denormalisering, efter at du allerede er gået live. Vær ikke bange for at bruge det, men følg ændringer, og du bør ikke opleve nogen problemer (dvs. de frygtede dataanomalier).