Når folk hører, hvad jeg laver, har folk en tendens til at stille mig det samme spørgsmål:Kan du udvikle et system, der forudsiger resultater fra fodboldkampe? Eller OL-medaljeresultater? Personligt tror jeg ikke meget på forudsigelser. Alligevel, hvis vi havde en stor mængde historiske data og relevante indikatorer, kunne vi bestemt designe et system til at hjælpe os med at komme med mere præcise antagelser. I denne artikel vil vi overveje en model, der kan gemme resultaterne af kampe og turneringer.
Denne model er primært fokuseret på europæisk fodbold (fodbold) kampe, statistikker og resultater, men den kunne nemt tilpasses til at rumme mange andre sportsgrene. Min primære motivation for denne artikel var dette års to store fodboldbegivenheder:UEFA Euro 2016 Championship, der lige fandt sted, og de Olympiske Sommerlege 2016, der finder sted lige nu.
Hvad ved vi, før turneringen starter?
Inden turneringen starter, ved vi næsten alt om den - undtagen det vigtigste:hvem der vinder. Lad os kort angive præcis, hvad vi allerede ved:
- Datoerne turneringen starter og slutter
- De steder, hvor kampene finder sted
- De nøjagtige tidspunkter, hvor kampene starter
- Hvilke hold har kvalificeret sig til turneringen
- Spillerne på hvert af disse hold
- Hver spillers tidligere præstationer og deres nuværende form
Hvilke matchdetaljer ønsker vi at gemme?
Turneringer består af flere kampe. Før vi gemmer kampdetaljer, skal vi:
- Relatere hver kamp med turneringen
- Optag turneringsfasen, da kampen blev spillet (f.eks. gruppespil, semifinaler)
Vi er også nødt til at gemme detaljer for enkelte kampe, herunder:
- De hold involveret i kampen
- Startopstillinger og udskiftninger
- Kampbegivenheder (i fodbold er disse:mål, straffe, overtrædelse, gult kort osv.)
- Slutresultat
- Spillernes handlinger under kampen
Vi bruger disse data til at fange alle vigtige kampbegivenheder. Sammenligning af en spillers præstation før og under kampen kan føre til visse konklusioner. Måske ville vi ikke være i stand til at forudsige de endelige resultater af deres præstationer (dvs. en sejr eller et tab), men statistikker kunne bestemt hjælpe os med at foretage antagelser med en vis grad af pålidelighed.
Introduktion af modellen
Modellen er opdelt i fire hovedområder:
TurneringsdetaljerMatchdetaljerBegivenhederIndikatorer og ydeevne
Tabellerne uden for disse områder er ordbøger (sport , fase , position ), kataloger (sport_event , team , afspiller ) og en enkelt mange-til-mange-relation (plays ).
Vi vil først beskrive de ukategoriserede tabeller og derefter se nærmere på hvert område.
De ukategoriserede tabeller
Disse tabeller er vigtige, fordi tabeller fra alle fire områder bruger dem som ordbøger eller kataloger.

sporten tabel viser alle de sportsgrene, vi gemmer i vores database. Vi vil sandsynligvis kun have én sport her, herrefodbold, men denne tabel giver os fleksibiliteten til at tilføje lignende sportsgrene (f.eks. kvindefodbold), hvis det er nødvendigt.

I sport_event bord, gemmer vi begivenhederne forbundet med vores sport(er). Et eksempel kunne være "Olympiske Lege 2016".
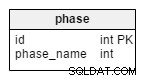
fasen table er en ordbog, der rummer alle mulige turneringsfaser. Den indeholder værdier som "gruppestadie" , "16. runde" , "kvartfinaler" , "semifinaler" , "endelig" .
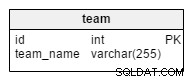
teamet tabellen er, som du ville gætte, en simpel liste over alle hold. Mulige værdier er "Kroatien" , “Polen” , “USA” osv. Hvis vi bruger databasen til at gemme information om klub- eller ligakonkurrence, ville vi også have værdier som “Barcelona” , "Real Madrid" , "Bayern" , “Manchester United” osv.
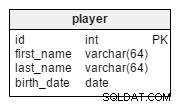
I afspilleren tabel, gemmer vi optegnelser for alle spillere, der tilhører de relevante hold.
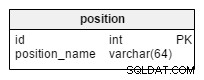
Endelig har vi positionen bord. Denne enkle ordbog gemmer en liste over alle de nødvendige positioner. I fodbold omfatter disse målmand, center-half, angriber osv.
Turneringsdetaljer
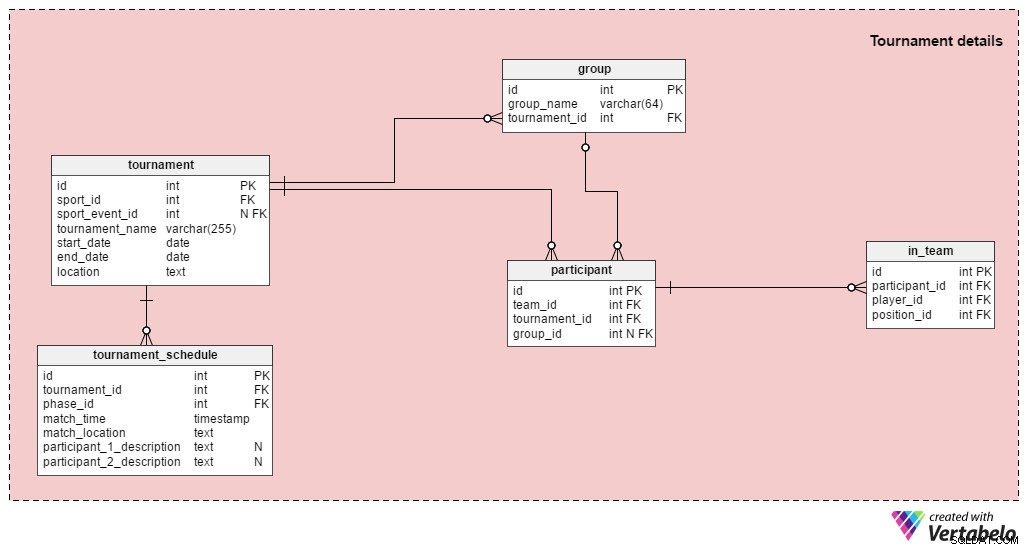
Bemærk: Hvis du blot ønsker at gemme resultaterne af enkelte kampe, behøver du ikke bruge denne sektion.
En turnering består af mere end én kamp; både UEFA Euro 2016 og fodboldbegivenhederne i sommer-OL 2016 er turneringer. Som vi sagde før, kan vi gemme en enkelt kamp i vores database, men vi kan også relatere kampe til deres relevante turneringer. Tabellerne i turneringssektionen er:
turnering– Dette indeholder alle de grundlæggende turneringsdata:sporten, startdatoen, slutdatoen osv. Vi skal også gemme turneringens navn og en beskrivelse af, hvor den finder sted.sport_event_idattribut er valgfri, fordi en turnering ikke behøver at være forbundet med en større begivenhed (såsom OL).gruppe– Dette viser alle grupperne i den turnering. UEFA Euro 2016 havde seks grupper, A til F.deltager– Det er de hold, der spiller i turneringen; hver deltager kan tildeles en gruppe. De fleste turneringer begynder med en gruppefase og fortsætter derefter til en knockout-fase (f.eks. UEFA Euro, UEFA World Cup, olympisk fodbold). Nogle turneringer vil kun have en gruppefase (f.eks. nationale ligaer), mens andre kun vil have en knockout-fase (f.eks. nationale cupper).in_team– Denne tabel giver en mange-til-mange-relation, der gemmer oplysninger om de spillere, der er registreret til den turnering og deres forventede positioner.turneringsplan– Efter min mening er dette den mest interessante tabel i dette afsnit. Listen over alle spil spillet under denne turnering er gemt her.turnerings-idattribut angiver, hvilken turnering hver kamp tilhører, ogphase_idattribut definerer den fase, hvor kampen vil finde sted. Vi gemmer også kampens placering og tidspunktet for, hvornår den begynder. Begge deltagere vil blive beskrevet med tekstfelter. Når gruppespillet er færdigt, kender vi alle matchups for eliminationsrunden. For eksempel vidste vi i begyndelsen af UEFA Euro 2016, at vinderen af gruppe E (1E) vil spille mod andenpladsen i gruppe D (2D). Efter at alle tre runder i gruppefasen var spillet, var dette par Italien vs. Spanien.
Matchdetaljer
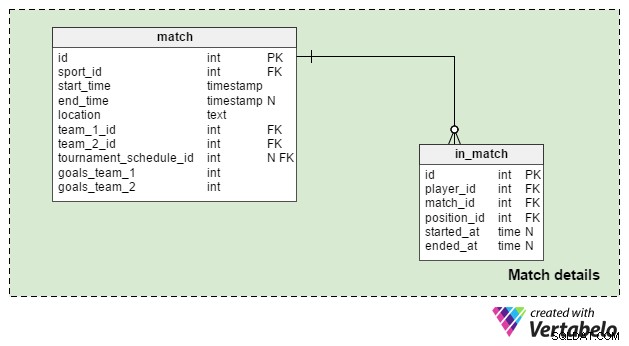
Matchdetaljer område bruges til at gemme data for enkelte kampe. Vi bruger to tabeller:
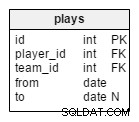
match– Dette indeholder alle detaljer om et enkelt match; denne kamp kan relateres til en turnering, men det kan også være et enkelt spil. Såtournament_schedule_idattribut er valgfri, og vi gemmersport_id,starttidogplaceringegenskaber igen her. Hvis kampen er en del af en turnering, såtournament_schedule_idvil blive tildelt en værdi.team_1_idogteam_2_idattributter er referencer til de hold, der er involveret i kampen.goals_team_1oggoals_team_2attributter indeholder resultatet af kampen. De er obligatoriske og bør have "0" som standardværdi for begge.i_match– Denne tabel er en liste over alle de spillere, der er tilmeldt den kamp; spillere, der ikke deltager, vil have en NULL istarted_atattribut, mens spillere, der kom ind som udskiftninger, vil havestartet_at> 0 . Hvis en spiller blev udskiftet, har de enended_atattribut, der matcherstarted_ategenskaben for den spiller, der erstattede dem. Hvis spilleren blev inde i hele kampen, er deresended_atattribut vil have samme værdi somsluttidspunktattribut.
Matchbegivenheder
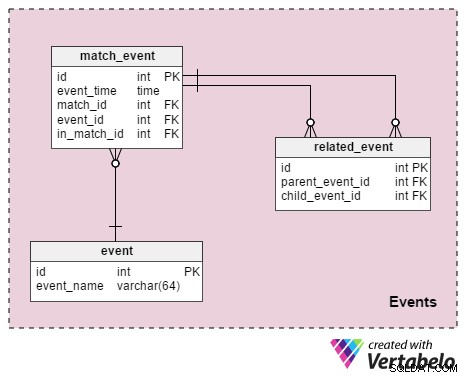
Dette afsnit er beregnet til at gemme alle detaljer eller begivenheder, der skete under spillet. Og tabellerne er:
begivenhed– Dette er en ordbog, der viser alle de begivenheder, vi ønsker at gemme. I fodbold er disse værdier som "foul begået" , "lidt dårligt" , "gult kort" , "rødt kort" , "frispark" , "straf" , "mål" , "offside" , “substitution” , "spiller udstødt fra kamp" .match_event– Dette relaterer begivenheder til kampen. Vi gemmerevent_timesamt spilleroplysninger relateret til den begivenhed (in_match_id).relateret_begivenhed- Det er det, der samler information om begivenheder. For at forklare, lad os se på et eksempel, når spiller A begår overtrædelse af spiller B. Vi indsætter en rekord imatch_eventtabel, der angiver, at spiller A har begået en fejl og en anden, der indikerer, at spiller B har begået en fejl. Vi tilføjer også en registrering tilrelated_eventtabel, hvor den 'begåede overtrædelse' vil være forælderen, og den 'lidte overtrædelse' vil være barnet. Vi registrerer også resultaterne af overtrædelsen:et gult kort, et frispark eller et straffespark og måske et mål.
Indikatorer og ydeevne
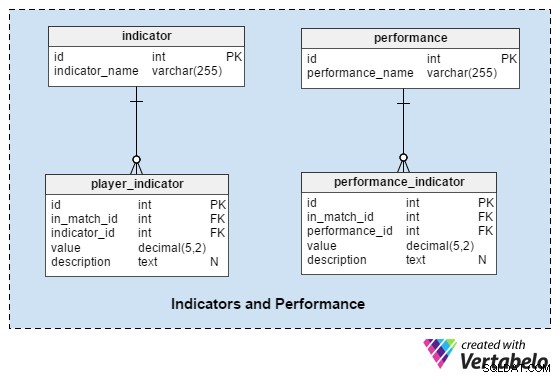
Dette afsnit skal hjælpe os med at analysere spillere og hold før og efter kampen.
indikatoren tabel er en ordbog med et foruddefineret sæt indikatorer for hver spiller før hver kamp. Disse indikatorer skal beskrive spillerens aktuelle form. Denne liste kan indeholde værdier som:"antal mål i de seneste 10 kampe" , "gennemsnitlig distance tilbagelagt i de seneste 10 kampe" , "antal redninger for GK i de seneste 10 kampe" .
ydelsen ordbog ligner meget indikator , men vi bruger det kun til at gemme værdier, der er relateret til det enkelte match:"dækket afstand" , "præcise afleveringer" osv.
player_indicator og performance_indicator tabeller deler en næsten identisk struktur:
in_match_id– henviser til, at spilleren deltager i en bestemt kampindikator_id/performance_id– henviser tilindikatoreneller ”performance-ordbøgerværdi– gemmer værdien for denne indikator (f.eks. en spiller tilbagelagt 10,72 km distance)beskrivelse– indeholder en yderligere beskrivelse, hvis det er nødvendigt
Hvad skete der under kampen?
Med alle disse data indtastet kunne vi nemt få kampdetaljer, begivenheder og statistik for hver kamp i vores database.
Denne enkle forespørgsel ville returnere grundlæggende detaljer for en kommende kamp:
SELECT team_1.`team_name`, team_2.`team_name`, `match`.`start_time`, `match`.`location` FROM `match`, `team` AS team_1, `team` AS team_2 WHERE `match`.`team_1_id` = team_1.`id` AND `match`.`team_2_id` = team_2.`id`
For at få en liste over alle in-play begivenheder under en bestemt kamp, ville vi bruge forespørgslen nedenfor:
SELECT `event`.`event_name`, `match_event`.`event_time`, `player`.`first_name`, `player`.`last_name` FROM `match`, `match_event`, `event`, `in_match`, `player` WHERE `match_event`.`match_id` = `match`.`id` AND `event`.`id` = `match_event`.`event_id` AND `in_match`.`id` = `match_event`.`in_match_id` AND `player`.`id` = `in_match`.`player_id` AND `match`.`id` = @match ORDER BY `match_event`.`event_time` ASC
Der er adskillige yderligere forespørgsler, som jeg kan komme i tanke om; det er nemt at lave en analyse, når du har dataene. Hvis du har målt og gemt et stort antal indikatorer og spillerpræstationsdata, kan du muligvis relatere disse parametre med et endeligt resultat. Jeg tror personligt ikke på sådanne forudsigelser; der er held-faktoren under kampe, plus adskillige andre faktorer, du ikke kan vide, før spillet starter. Alligevel, hvis du har et stort datasæt og mange parametre, øges din chance for at lave mere præcise forudsigelser.
Modellen præsenteret i denne artikel giver os mulighed for at gemme kampe, kampdetaljer og en historie om hver spillers præstation. Vi kan også indstille formindikatorer for hver spiller før kampen. Lagring af nok detaljer burde give os flere parametre, som vi kan basere vores antagelser på. Jeg siger ikke, at vi kunne forudsige resultatet af spillet, men vi kunne have det sjovt med det.
Vi kunne også nemt tilpasse denne model til at gemme data til andre sportsgrene. Disse ændringer bør ikke være for komplekse. Tilføjelse af et sport_id attribut til ordbøgerne burde gøre tricket. Alligevel tror jeg, det ville være klogt at have en ny instans for hver anden sport.