Folk spekulerer på, om de skal gøre deres bedste for at forhindre undtagelser eller bare lade systemet håndtere dem. Jeg har set flere diskussioner, hvor folk diskuterer, om de skal gøre, hvad de kan for at forhindre en undtagelse, fordi fejlhåndtering er "dyrt". Der er ingen tvivl om, at fejlhåndtering ikke er gratis, men jeg vil forudsige, at en overtrædelse af begrænsninger er mindst lige så effektiv som at tjekke for en potentiel overtrædelse først. Dette kan være anderledes for en nøgleovertrædelse end en overtrædelse af statisk begrænsning, for eksempel, men i dette indlæg vil jeg fokusere på førstnævnte.
De primære tilgange, folk bruger til at håndtere undtagelser, er:
- Lad bare motoren klare det, og send enhver undtagelse tilbage til den, der ringer.
- Brug
BEGIN TRANSACTIONogROLLBACKhvis@@ERROR <> 0. - Brug
TRY/CATCHmedROLLBACKiCATCHblokere (SQL Server 2005+).
Og mange har den tilgang, at de skal tjekke, om de vil pådrage sig overtrædelsen først, da det virker renere at håndtere duplikatet selv end at tvinge motoren til at gøre det. Min teori er, at du skal stole på, men verificere; overveje for eksempel denne tilgang (for det meste pseudo-kode):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Vi ved, at IF NOT EXISTS check garanterer ikke, at en anden ikke har indsat rækken, når vi kommer til INSERT (medmindre vi placerer aggressive låse på bordet og/eller bruger SERIALIZABLE ), men den ydre kontrol forhindrer os i at forsøge at begå en fejl og derefter at skulle rulle tilbage. Vi holder os uden for hele TRY/CATCH struktur, hvis vi allerede ved, at INSERT vil mislykkes, og det ville være logisk at antage, at dette – i det mindste i nogle tilfælde – vil være mere effektivt end at indtaste TRY/CATCH struktur ubetinget. Dette giver ikke meget mening i en enkelt INSERT scenarie, men forestil dig et tilfælde, hvor der sker mere i den TRY blokering (og flere potentielle overtrædelser, som du kan tjekke for på forhånd, hvilket betyder endnu mere arbejde, som du ellers skulle udføre og derefter rulle tilbage, hvis der skulle opstå en senere overtrædelse).
Nu ville det være interessant at se, hvad der ville ske, hvis du brugte et ikke-standard isolationsniveau (noget jeg vil behandle i et fremtidigt indlæg), især med samtidighed. Til dette indlæg ville jeg dog starte langsomt og teste disse aspekter med en enkelt bruger. Jeg oprettede en tabel kaldet dbo.[Objects] , en meget forenklet tabel:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Jeg ønskede at udfylde denne tabel med 100.000 rækker af eksempeldata. For at gøre værdierne i navnekolonnen unikke (da PK er den begrænsning, jeg ønskede at overtræde), lavede jeg en hjælpefunktion, der tager et antal rækker og en minimumsstreng. Minimumsstrengen ville blive brugt til at sikre, at enten (a) sættet startede ud over maksimumværdien i objekttabellen, eller (b) sættet startede ved minimumværdien i objekttabellen. (Jeg vil specificere disse manuelt under testene, verificeret ved blot at inspicere dataene, selvom jeg sandsynligvis kunne have indbygget den check i funktionen.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Dette gælder en CROSS JOIN af sys.all_objects på sig selv ved at tilføje et unikt rækkenummer til hvert navn, så de første 10 resultater ville se sådan ud:
At udfylde tabellen med 100.000 rækker var enkelt:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Nu, da vi skal indsætte nye unikke værdier i tabellen, har jeg oprettet en procedure til at udføre noget oprydning i begyndelsen og slutningen af hver test – udover at slette eventuelle nye rækker, vi har tilføjet, vil den også rydde op cachen og bufferne. Ikke noget, du vil kode ind i en procedure på dit produktionssystem, selvfølgelig, men ganske fint til lokal præstationstest.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Jeg oprettede også en logtabel for at holde styr på start- og sluttidspunkter for hver test:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Endelig håndterer den lagrede testprocedure en række ting. Vi har tre forskellige fejlhåndteringsmetoder, som beskrevet i punkterne ovenfor:"JustInsert", "Rollback" og "TryCatch"; vi har også tre forskellige indsætningstyper:(1) alle indsættelser lykkes (alle rækker er unikke), (2) alle indsættelser mislykkes (alle rækker er dubletter), og (3) halve indsættelser lykkes (halvdelen af rækkerne er unikke, og halvdelen rækkerne er dubletter). Sammen med dette er to forskellige tilgange:Kontroller for overtrædelsen, før du forsøger at indsætte, eller bare gå videre og lad motoren afgøre, om den er gyldig. Jeg troede, at dette ville give en god sammenligning af de forskellige fejlhåndteringsteknikker kombineret med forskellige sandsynligheder for kollisioner for at se, om en høj eller lav kollisionsprocent ville påvirke resultaterne væsentligt.
Til disse tests valgte jeg 40.000 rækker som mit samlede antal indsættelsesforsøg, og i proceduren udfører jeg en forening af 20.000 unikke eller ikke-unikke rækker med 20.000 andre unikke eller ikke-unikke rækker. Du kan se, at jeg hårdkodede cutoff-strengene i proceduren; Bemærk venligst, at på dit system vil disse afskæringer næsten helt sikkert forekomme et andet sted.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Nu kan vi kalde denne procedure med forskellige argumenter for at få den anderledes adfærd, vi leder efter, idet vi forsøger at indsætte 40.000 værdier (og ved selvfølgelig, hvor mange der skal lykkes eller mislykkes i hvert enkelt tilfælde). For hver 'fejlhåndteringsmetode' (bare prøv indsættelsen, brug start tran/rollback eller prøv/fang) og hver indsætningstype (alle lykkes, halvdelen lykkes og ingen lykkes), kombineret med hvorvidt der skal kontrolleres for overtrædelsen for det første giver dette os 18 kombinationer:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;000;
Efter vi har kørt dette (det tager omkring 8 minutter på mit system), har vi nogle resultater i vores log. Jeg kørte hele partiet fem gange for at sikre, at vi fik anstændige gennemsnit og for at udjævne eventuelle uregelmæssigheder. Her er resultaterne:
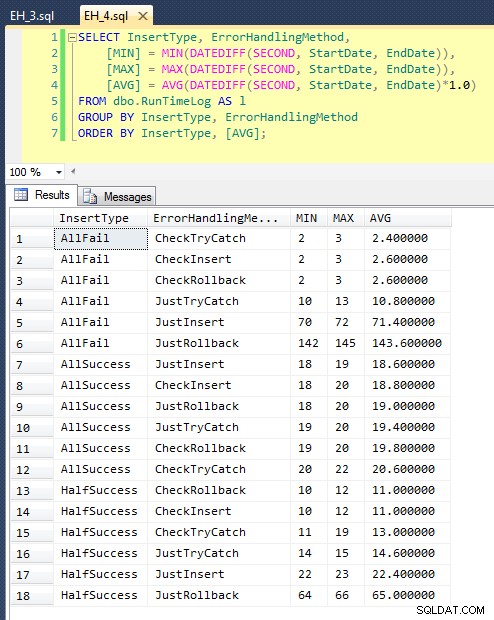
Grafen, der plotter alle varighederne på én gang, viser et par alvorlige outliers:
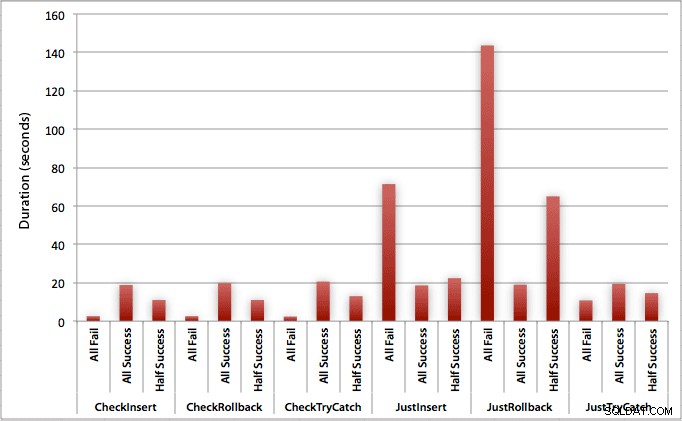
Du kan se, at i tilfælde, hvor vi forventer en høj fejlrate (i denne test, 100 %), er det at starte en transaktion og rulle tilbage langt den mindst attraktive tilgang (3,59 millisekunder pr. forsøg), mens du bare lader motoren hæve en fejl er cirka halvt så slem (1,785 millisekunder pr. forsøg). Den næstdårligste performer var tilfældet, hvor vi begynder en transaktion og derefter ruller den tilbage, i et scenarie, hvor vi forventer, at omkring halvdelen af forsøgene mislykkes (i gennemsnit 1,625 millisekunder pr. forsøg). De 9 tilfælde i venstre side af grafen, hvor vi først tjekker for overtrædelsen, vovede sig ikke over 0,515 millisekunder pr. forsøg.
Når det er sagt, giver de individuelle grafer for hvert scenarie (høj % af succes, høj % af fiasko og 50-50) virkelig virkningen af hver metode.
Hvor alle indsættelserne lykkes
I dette tilfælde ser vi, at omkostningerne ved at tjekke for overtrædelsen først er ubetydelige, med en gennemsnitlig forskel på 0,7 sekunder på tværs af batchen (eller 125 mikrosekunder pr. indsættelsesforsøg):
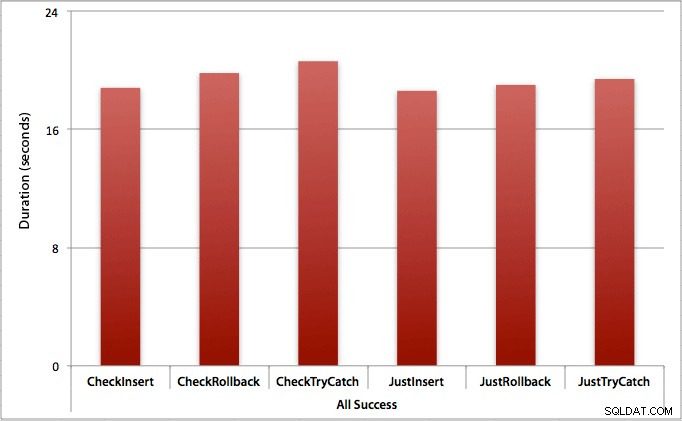
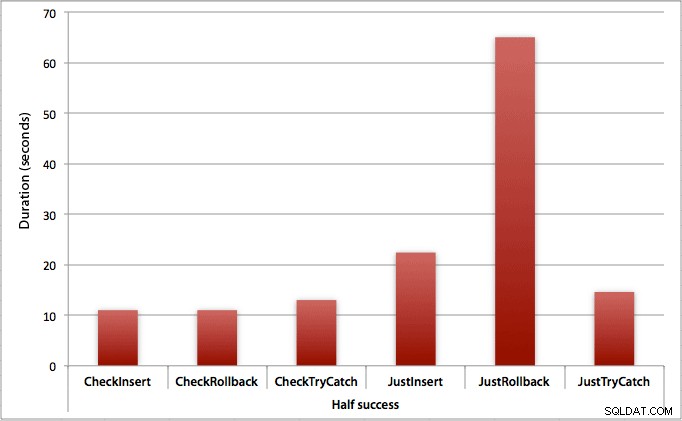
Hvor kun halvdelen af indsatserne lykkes
Når halvdelen af indsatserne fejler, ser vi et stort spring i varigheden for insert/rollback-metoderne. Scenariet, hvor vi starter en transaktion og ruller den tilbage, er omkring 6 gange langsommere over hele batchen sammenlignet med at tjekke først (1,625 millisekunder pr. forsøg vs. 0,275 millisekunder pr. forsøg). Selv TRY/CATCH-metoden er 11 % hurtigere, når vi tjekker først:
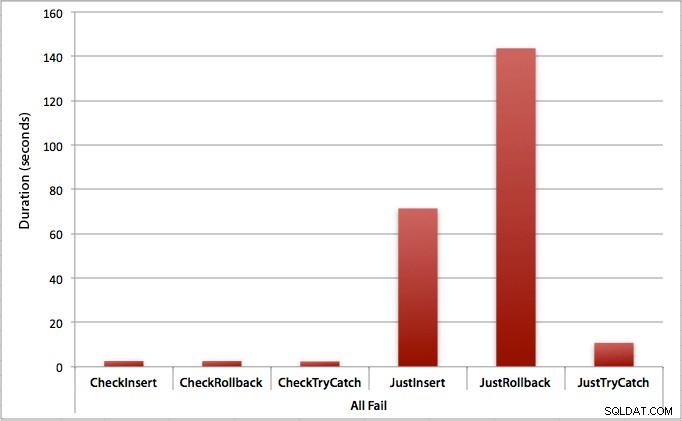
Hvor alle inserts fejler
Som du kunne forvente, viser dette den mest udtalte effekt af fejlhåndtering og de mest åbenlyse fordele ved at tjekke først. Tilbageføringsmetoden er næsten 70 gange langsommere i dette tilfælde, når vi ikke tjekker, sammenlignet med når vi gør det (3,59 millisekunder pr. forsøg vs. 0,065 millisekunder pr. forsøg):
Hvad fortæller dette os? Hvis vi tror, at vi vil have en høj fejlrate, eller ikke har nogen idé om, hvad vores potentielle fejlrate vil være, så vil det være enormt værd at tjekke først for at undgå overtrædelser i motoren. Selv i det tilfælde, hvor vi har et vellykket indstik hver gang, er omkostningerne ved at tjekke først marginale og let retfærdiggjorte af de potentielle omkostninger ved at håndtere fejl senere (medmindre din forventede fejlrate er præcis 0%).
Så indtil videre tror jeg, at jeg vil holde fast i min teori om, at det i simple tilfælde giver mening at tjekke for en potentiel overtrædelse, før du fortæller SQL Server om at gå videre og indsætte alligevel. I et fremtidigt indlæg vil jeg se på ydeevnepåvirkningen af forskellige isolationsniveauer, samtidighed og måske endda et par andre fejlhåndteringsteknikker.
[Som en sidebemærkning skrev jeg en komprimeret version af dette indlæg som et tip til mssqltips.com tilbage i februar.]