Dette er anden del i en serie om løsninger på nummerseriegeneratorudfordringen. Sidste måned dækkede jeg løsninger, der genererer rækkerne på farten ved hjælp af en tabelværdikonstruktør med rækker baseret på konstanter. Der var ingen I/O-operationer involveret i disse løsninger. I denne måned fokuserer jeg på løsninger, der forespørger på en fysisk basistabel, som du på forhånd udfylder med rækker. Af denne grund vil jeg, ud over at rapportere tidsprofilen for løsningerne, som jeg gjorde i sidste måned, også rapportere I/O-profilen for de nye løsninger. Tak igen til Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 og Ed Wagner for at dele dine ideer og kommentarer.
Hidtil hurtigste løsning
Først, som en hurtig påmindelse, lad os gennemgå den hurtigste løsning fra sidste måneds artikel, implementeret som en inline TVF kaldet dbo.GetNumsAlanCharlieItzikBatch.
Jeg vil lave min test i tempdb, aktivere IO og TIME statistik:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
Den hurtigste løsning fra sidste måned anvender en joinforbindelse med en dummy-tabel, der har et kolonnelagerindeks for at få batchbehandling. Her er koden til at oprette dummy-tabellen:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Og her er koden med definitionen af dbo.GetNumsAlanCharlieItzikBatch-funktionen:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Sidste måned brugte jeg følgende kode til at teste funktionens ydeevne med 100M rækker, efter at have aktiveret Discard-resultaterne efter udførelse i SSMS for at undertrykke returnering af outputrækkerne:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Her er de tidsstatistikker, jeg fik for denne udførelse:
CPU-tid =16031 ms, forløbet tid =17172 ms.Joe Obbish bemærkede korrekt, at denne test kunne mangle i sin afspejling af nogle virkelige scenarier i den forstand, at en stor del af kørselstiden skyldes asynkrone netværks I/O-venter (ASYNC_NETWORK_IO ventetype). Du kan observere de højeste ventetider ved at se på egenskabssiden for rodknudepunktet for den faktiske forespørgselsplan eller køre en udvidet begivenhedssession med venteinfo. Det faktum, at du aktiverer Kassér resultater efter udførelse i SSMS, forhindrer ikke SQL Server i at sende resultatrækkerne til SSMS; det forhindrer bare SSMS i at udskrive dem. Spørgsmålet er, hvor sandsynligt det er, at du returnerer store resultatsæt til klienten i virkelige scenarier, selv når du bruger funktionen til at producere en lang række serier? Måske skriver du oftere forespørgselsresultaterne til en tabel eller bruger resultatet af funktionen som en del af en forespørgsel, der til sidst producerer et lille resultatsæt. Du skal finde ud af dette. Du kan skrive resultatsættet ind i en midlertidig tabel ved hjælp af SELECT INTO-sætningen, eller du kan bruge Alan Bursteins trick med en tildeling SELECT-sætning, som tildeler resultatkolonnens værdi til en variabel.
Sådan ændrer du den sidste test for at bruge muligheden for variabeltildeling:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Her er tidsstatistikken, som jeg fik til denne test:
CPU-tid =8641 ms, forløbet tid =8645 ms.Denne gang har venteoplysningerne ingen async-netværks I/O-venter, og du kan se det betydelige fald i køretid.
Test funktionen igen, denne gang tilføjer bestilling:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Jeg fik følgende præstationsstatistik for denne udførelse:
CPU-tid =9360 ms, forløbet tid =9551 ms.Husk, at der ikke er behov for en sorteringsoperator i planen for denne forespørgsel, da kolonnen n er baseret på et udtryk, der er ordensbevarende i forhold til kolonnens rækkenummer. Det er takket være Charlis konstante foldetrick, som jeg dækkede i sidste måned. Planerne for begge forespørgsler – den uden bestilling og den med bestilling er den samme, så ydeevnen har en tendens til at være ens.
Figur 1 opsummerer de præstationstal, jeg fik for sidste måneds løsninger, kun denne gang ved at bruge variabel tildeling i testene i stedet for at kassere resultater efter udførelse.
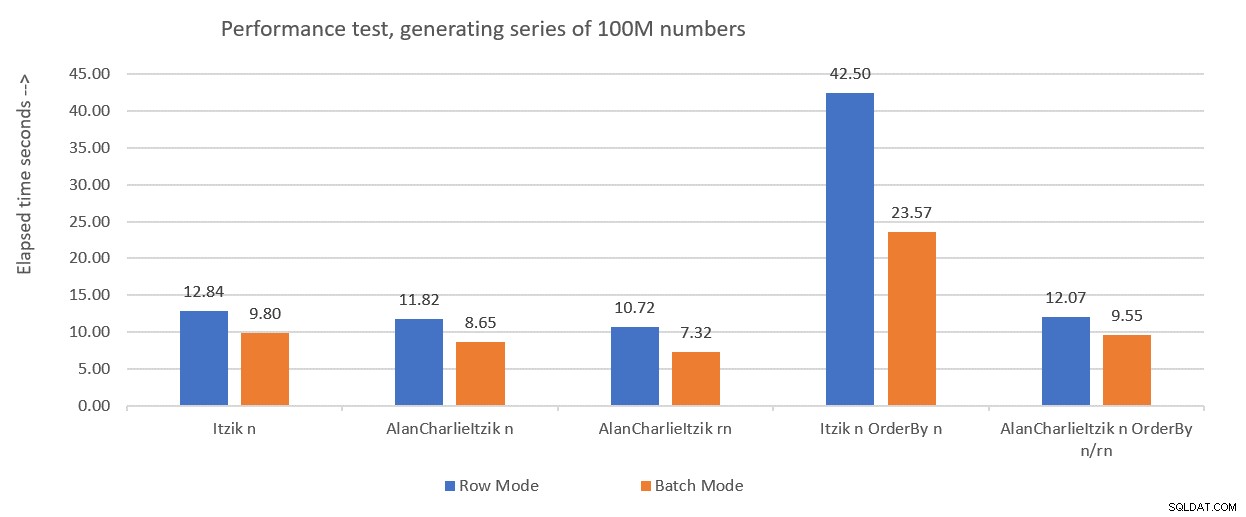 Figur 1:Præstationsoversigt indtil videre med variabeltildeling
Figur 1:Præstationsoversigt indtil videre med variabeltildeling
Jeg vil bruge variabel tildelingsteknikken til at teste resten af løsningerne, som jeg vil præsentere i denne artikel. Sørg for, at du justerer dine tests, så de bedst afspejler din virkelige situation, ved hjælp af variabel tildeling, SELECT INTO, kasser resultater efter udførelse eller enhver anden teknik.
Tip til at tvinge serielle planer uden MAXDOP 1
Inden jeg præsenterer nye løsninger, ville jeg lige komme med et lille tip. Husk, at nogle af løsningerne fungerer bedst, når du bruger en seriel plan. Den indlysende måde at fremtvinge dette på er med et MAXDOP 1-forespørgselstip. Og det er den rigtige vej at gå, hvis du nogle gange vil aktivere parallelitet og nogle gange ikke. Men hvad nu hvis du altid vil gennemtvinge en seriel plan, når du bruger funktionen, omend et mindre sandsynligt scenario?
Der er et trick til at opnå dette. Brug af en ikke-inlinebar skalar UDF i forespørgslen er en parallelismehæmmer. En af de skalære UDF-inlining-hæmmere påkalder en iboende funktion, der er tidsafhængig, såsom SYSDATETIME. Så her er et eksempel på en ikke-inlinebar skalar UDF:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
En anden mulighed er at definere en UDF med kun en konstant som den returnerede værdi og bruge indstillingen INLINE =OFF i dens overskrift. Men denne mulighed er kun tilgængelig fra og med SQL Server 2019, som introducerede skalar UDF-inlining. Med ovenstående foreslåede funktion kan du oprette den som den er med ældre versioner af SQL Server.
Derefter skal du ændre definitionen af dbo.GetNumsAlanCharlieItzikBatch-funktionen for at have et dummy-kald til dbo.MySYSDATETIME (definer en kolonne baseret på det, men referer ikke til kolonnen i den returnerede forespørgsel), som sådan:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Du kan nu køre ydeevnetesten igen uden at angive MAXDOP 1 og stadig få en seriel plan:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Det er dog vigtigt at understrege, at enhver forespørgsel, der bruger denne funktion, nu vil få en seriel plan. Hvis der er nogen chance for, at funktionen vil blive brugt i forespørgsler, der vil drage fordel af parallelle planer, skal du hellere lade være med at bruge dette trick, og når du har brug for en seriel plan, skal du blot bruge MAXDOP 1.
Løsning af Joe Obbish
Joes løsning er ret kreativ. Her er hans egen beskrivelse af løsningen:
"Jeg valgte at oprette et clustered columnstore index (CCI) med 134.217.728 rækker af sekventielle heltal. Funktionen refererer til tabellen op til 32 gange for at få alle de nødvendige rækker til resultatsættet. Jeg valgte en CCI, fordi dataene vil komprimere godt (mindre end 3 bytes pr. række), du får batch-tilstand "gratis", og tidligere erfaringer tyder på, at læsning af sekventielle numre fra en CCI vil være hurtigere end at generere dem gennem en anden metode. ”Som nævnt tidligere bemærkede Joe også, at min oprindelige præstationstest var væsentligt skæv på grund af de asynkrone netværks I/O-venter genereret ved at sende rækkerne til SSMS. Så alle de test, som jeg vil udføre her, vil bruge Alans idé med variabeltildelingen. Sørg for at justere dine tests baseret på det, der bedst afspejler din virkelige situation.
Her er koden Joe brugte til at oprette tabellen dbo.GetNumsObbishTable og udfylde den med 134.217.728 rækker:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Det tog denne kode 1:04 minutter at fuldføre på min maskine.
Du kan kontrollere pladsforbruget af denne tabel ved at køre følgende kode:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Jeg har brugt omkring 350 MB plads. Sammenlignet med de andre løsninger, som jeg vil præsentere i denne artikel, bruger denne væsentlig mere plads.
I SQL Servers columnstore-arkitektur er en rækkegruppe begrænset til 2^20 =1.048.576 rækker. Du kan kontrollere, hvor mange rækkegrupper der blev oprettet for denne tabel ved hjælp af følgende kode:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Jeg har 128 rækkegrupper.
Her er koden med definitionen af dbo.GetNumsObbish-funktionen:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
De 32 individuelle forespørgsler genererer de usammenhængende underområder på 134.217.728 heltal, der, når de er forenet, producerer det komplette uafbrudte område 1 til 4.294.967.296. Det, der virkelig er smart ved denne løsning, er WHERE-filterets prædikater, som de enkelte forespørgsler bruger. Husk, at når SQL Server behandler en inline TVF, anvender den først parameterindlejring og erstatter parametrene med inputkonstanterne. SQL Server kan derefter optimere de forespørgsler, der producerer underområder, der ikke krydser inputområdet. For eksempel, når du anmoder om inputområdet 1 til 100.000.000, er kun den første forespørgsel relevant, og resten bliver optimeret. Planen vil i dette tilfælde kun omfatte en henvisning til én forekomst af tabellen. Det er ret genialt!
Lad os teste funktionens ydeevne med intervallet 1 til 100.000.000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Planen for denne forespørgsel er vist i figur 2.
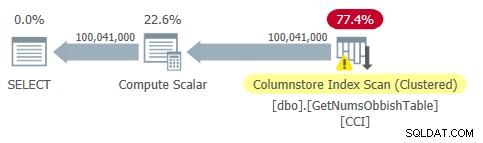 Figur 2:Plan for dbo.GetNumsObbish, 100 mio. rækker, uordnet
Figur 2:Plan for dbo.GetNumsObbish, 100 mio. rækker, uordnet
Bemærk, at der faktisk kun er behov for én reference til tabellens CCI i denne plan.
Jeg fik følgende tidsstatistik for denne udførelse:
Det er ret imponerende og langt hurtigere end noget andet, jeg har testet.
Her er de I/O-statistikker, jeg fik for denne udførelse:
Tabel 'GetNumsObbishTable'. Scanningsantal 1, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 32928 , lob fysisk læser 0, lob sideserver læser 0, lob read-ahead læser 0, lob sideserver read-ahead læser 0.Tabel 'GetNumsObbishTable'. Segment lyder 96 , segment sprunget over 32.
I/O-profilen af denne løsning er en af dens ulemper sammenlignet med de andre, idet den medfører over 30K lob logiske læsninger for denne udførelse.
For at se, at når du krydser flere underområder med 134.217.728 heltal, vil planen involvere flere referencer til tabellen, forespørg funktionen med intervallet 1 til 400.000.000, for eksempel:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Planen for denne udførelse er vist i figur 3.
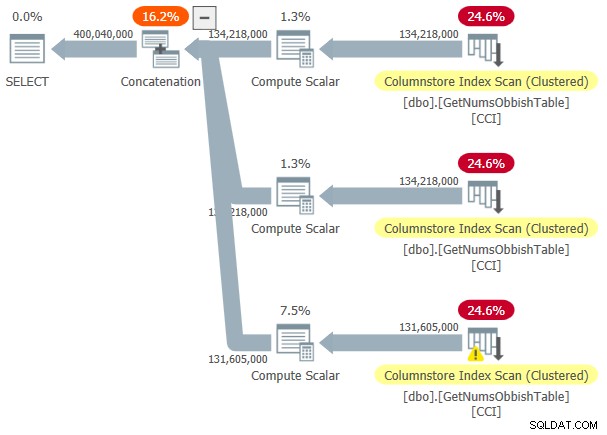 Figur 3:Plan for dbo.GetNumsObbish, 400 mio. rækker, uordnet
Figur 3:Plan for dbo.GetNumsObbish, 400 mio. rækker, uordnet
Det anmodede interval krydsede tre underområder på 134.217.728 heltal, og planen viser derfor tre referencer til tabellens CCI.
Her er de tidsstatistikker, jeg fik for denne udførelse:
CPU-tid =20610 ms, forløbet tid =20628 ms.Og her er dens I/O-statistikker:
Tabel 'GetNumsObbishTable'. Scanningsantal 3, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 131026 , lob fysisk læser 0, lob sideserver læser 0, lob read-ahead læser 0, lob sideserver read-ahead læser 0.Tabel 'GetNumsObbishTable'. Segment lyder 382 , segment sprunget over 2.
Denne gang resulterede forespørgselsudførelsen i over 130.000 lob logiske læsninger.
Hvis du kan tåle I/O-omkostningerne og ikke behøver at behandle nummerserien på en ordnet måde, er dette en god løsning. Men hvis du har brug for at behandle serien i rækkefølge, vil denne løsning resultere i en sorteringsoperatør i planen. Her er en test, der anmoder om det bestilte resultat:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Planen for denne udførelse er vist i figur 4.
 Figur 4:Plan for dbo.GetNumsObbish, 100 mio. rækker, bestilt
Figur 4:Plan for dbo.GetNumsObbish, 100 mio. rækker, bestilt
Her er de tidsstatistikker, jeg fik for denne udførelse:
CPU-tid =44516 ms, forløbet tid =34836 ms.Som du kan se, blev ydeevnen forringet betydeligt med kørselstiden stigende med en størrelsesorden på grund af den eksplicitte sortering.
Her er I/O-statistikken, som jeg fik for denne udførelse:
Tabel 'GetNumsObbishTable'. Scanningsantal 4, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 32928 , lob fysisk læser 0, lob sideserver læser 0, lob read-ahead læser 0, lob sideserver read-ahead læser 0.Tabel 'GetNumsObbishTable'. Segment lyder 96 , segment sprunget over 32.
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob sideserver læser 0, lob læs- ahead læser 0, lob sideserver read-ahead læser 0.
Bemærk, at en arbejdstabel dukkede op i outputtet af STATISTICS IO. Det er fordi en slags potentielt kan spilde til tempdb, i hvilket tilfælde den ville bruge en arbejdsbord. Denne udførelse spildte ikke, derfor er tallene alle nuller i denne post.
Løsning af John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 postede en løsning, der bare er smuk i sin enkelhed. Derudover inkluderer det ideer og forslag fra de andre løsninger af Dave, Joe, Alan, Charlie og mig selv.
Ligesom med Joes løsning besluttede John at bruge en CCI for at få et højt niveau af komprimering og "gratis" batchbehandling. Kun John besluttede at fylde tabellen med 4B rækker med en dummy NULL-markør i en bit-kolonne, og lade ROW_NUMBER-funktionen generere tallene. Da de lagrede værdier alle er ens, har du med komprimering af gentagne værdier brug for betydeligt mindre plads, hvilket resulterer i betydeligt færre I/O'er sammenlignet med Joes løsning. Columnstore-komprimering håndterer gentagne værdier meget godt, da den kun kan repræsentere hver sådan fortløbende sektion i en rækkegruppes kolonnesegment én gang sammen med antallet af fortløbende gentagne forekomster. Da alle rækker har samme værdi (NULL-markøren), behøver du teoretisk set kun én forekomst pr. rækkegruppe. Med 4B rækker bør du ende med 4.096 rækkegrupper. Hver skal have et enkelt kolonnesegment med meget lidt pladsforbrug.
Her er koden til at oprette og udfylde tabellen, implementeret som en CCI med arkivkomprimering:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Den største ulempe ved denne løsning er den tid, det tager at udfylde denne tabel. Det tog denne kode 12:32 minutter at fuldføre på min maskine, når jeg tillod parallelitet, og 15:17 minutter, når jeg fremtvang en seriel plan.
Bemærk, at du kan arbejde på at optimere databelastningen. For eksempel testede John en løsning, der indlæste rækkerne ved hjælp af 32 samtidige forbindelser med OSTRESS.EXE, der hver kørte 128 runder af indsættelser af 2^20 rækker (maks. rækkegruppestørrelse). Denne løsning sænkede Johns indlæsningstid til en tredjedel. Her er koden John brugte:
ostress -S(lokal)\DinSQLInstance -E -dtempdb -n32 -r128 -Q"MED L0 AS (VÆLG CAST(NULL SOM BIT) SOM b FRA (VÆRDIER(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)), L1 AS (VÆLG A.b FRA L0 SOM A CROSS JOIN L0 AS B), L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B), nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"Alligevel er indlæsningstiden i minutter. Den gode nyhed er, at du kun skal udføre denne dataindlæsning én gang.
Den gode nyhed er den lille mængde plads, der kræves af bordet. Brug følgende kode til at kontrollere pladsforbruget:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Jeg fik 1,64 MB. Det er fantastisk i betragtning af, at tabellen har 4B rækker!
Brug følgende kode for at kontrollere, hvor mange rækkegrupper der blev oprettet:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Som forventet er antallet af rækkegrupper 4.096.
Funktionsdefinitionen af dbo.GetNumsJohn2DaveObbishAlanCharlieItzik bliver så ret enkel:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Som du kan se, bruger en simpel forespørgsel mod tabellen ROW_NUMBER-funktionen til at beregne basisrækkenumrene (rownum-kolonnen), og derefter bruger den ydre forespørgsel de samme udtryk som i dbo.GetNumsAlanCharlieItzikBatch til at beregne rn, op og n. Også her er både rn og n ordensbevarende med hensyn til rækkenummer.
Lad os teste funktionens ydeevne:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Jeg fik planen vist i figur 5 for denne udførelse.
 Figur 5:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figur 5:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Her er tidsstatistikken, som jeg fik til denne test:
CPU-tid =7593 ms, forløbet tid =7590 ms.
Som du kan se, er udførelsestiden ikke så hurtig som med Joes løsning, men den er stadig hurtigere end alle andre løsninger, som jeg har testet.
Her er I/O-statistikken, som jeg fik til denne test:
Tabel 'NullBits4B'. Segment lyder 96 , segment sprunget over 0
Bemærk, at I/O-kravene er væsentligt lavere end med Joes løsning.
Den anden gode ting ved denne løsning er, at når du skal behandle den bestilte nummerserie, betaler du ikke noget ekstra. Det er fordi det ikke vil resultere i en eksplicit sorteringsoperation i planen, uanset om du bestiller resultatet efter rn eller n.
Her er en test, der viser dette:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Du får samme plan som vist tidligere i figur 5.
Her er tidsstatistikken, som jeg fik til denne test;
CPU-tid =7578 ms, forløbet tid =7582 ms.Og her er I/O-statistikken:
Tabel 'NullBits4B'. Scanningsantal 1, logisk læser 0, fysisk læser 0, sideserver læser 0, read-ahead læser 0, sideserver read-ahead læser 0, lob logisk læser 194 , lob fysisk læser 0, lob sideserver læser 0, lob read-ahead læser 0, lob sideserver read-ahead læser 0.Tabel 'NullBits4B'. Segment lyder 96 , segment sprunget over 0.
De er stort set de samme som i testen uden bestilling.
Løsning 2 af John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
Johns løsning er hurtig og enkel. Det er fantastisk. Den ene ulempe er indlæsningstiden. Nogle gange vil dette ikke være et problem, da indlæsningen kun sker én gang. Men hvis det er et problem, kan du udfylde tabellen med 102.400 rækker i stedet for 4B rækker og bruge en krydsforbindelse mellem to forekomster af tabellen og et TOP-filter til at generere det ønskede maksimum på 4B rækker. Bemærk, at for at få 4B rækker ville det være tilstrækkeligt at udfylde tabellen med 65.536 rækker og derefter anvende en krydssammenføjning; Men for at få dataene til at blive komprimeret med det samme – i modsætning til at blive indlæst i et rækkelagerbaseret deltalager – skal du indlæse tabellen med minimum 102.400 rækker.
Her er koden til at oprette og udfylde tabellen:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Indlæsningstiden er ubetydelig — 43 ms på min maskine.
Tjek størrelsen af tabellen på disken:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Jeg har brug for 56 KB plads til dataene.
Tjek antallet af rækkegrupper, deres tilstand (komprimeret eller åben) og deres størrelse:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Jeg fik følgende output:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Her behøves kun én rækkegruppe; det er komprimeret, og størrelsen er ubetydelige 293 bytes.
Hvis du udfylder tabellen med en række mindre (102.399), får du et rækkelager-baseret ukomprimeret åbent deltalager. I et sådant tilfælde rapporterer sp_spaceused datastørrelse på disk på over 1 MB, og sys.column_store_row_groups rapporterer følgende information:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Så sørg for at udfylde tabellen med 102.400 rækker!
Her er definitionen af funktionen dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
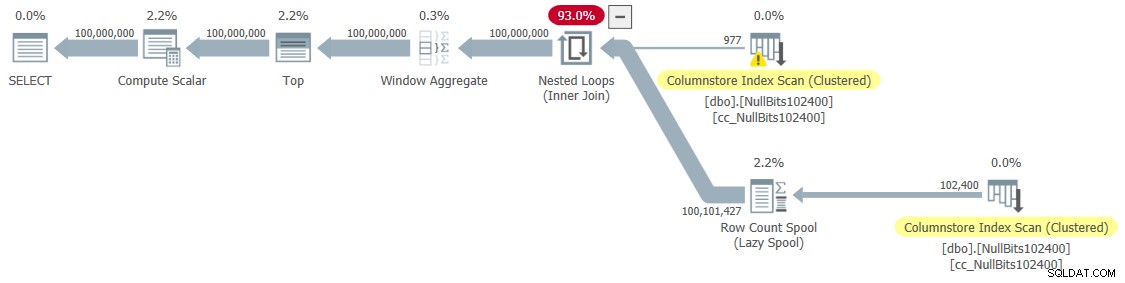 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
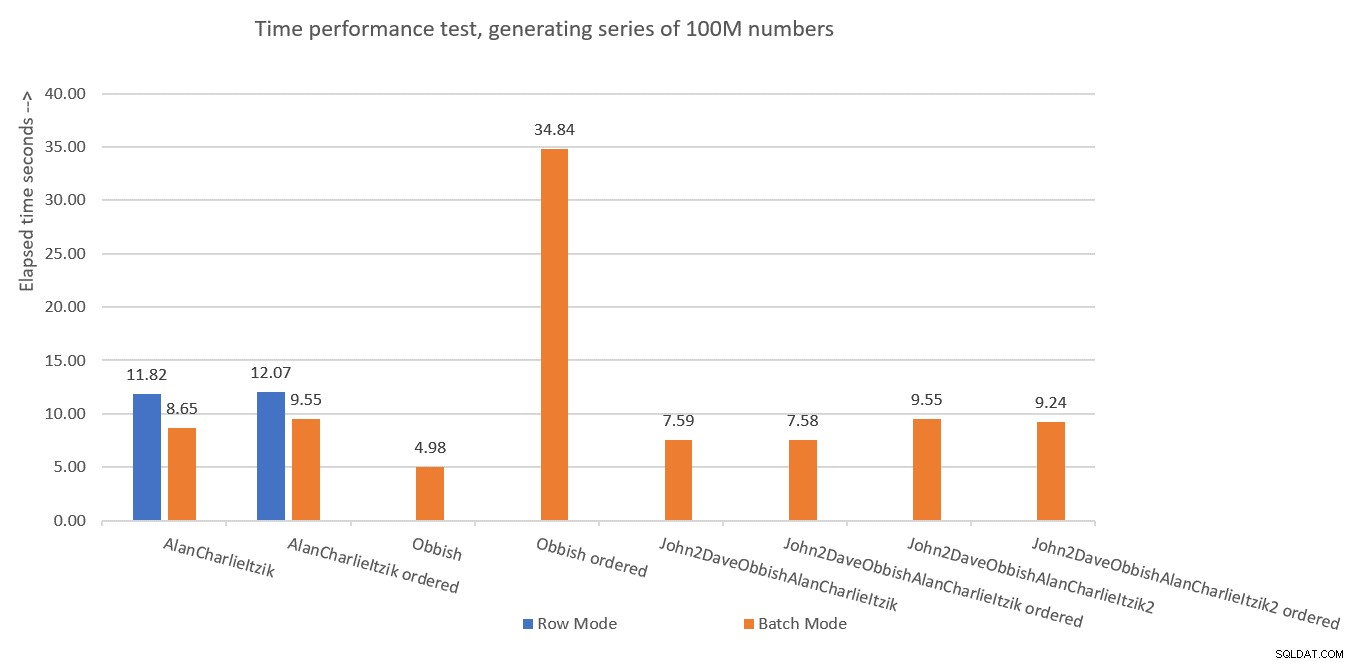 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
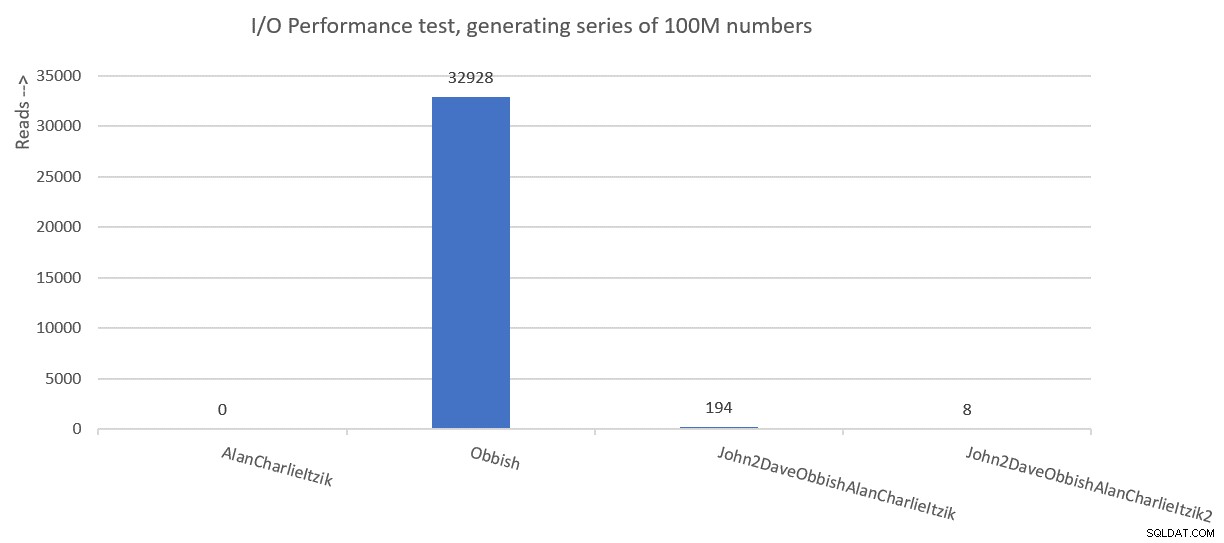 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.