Denne artikel er den tredje i en serie om optimeringstærskler for gruppering og aggregering af data. I del 1 dækkede jeg den forudbestilte Stream Aggregate-algoritme. I del 2 dækkede jeg den ikke-forudbestilte Sort + Stream Aggregate-algoritme. I denne del dækker jeg Hash Match (Aggregate) algoritmen, som jeg blot vil referere til som Hash Aggregate. Jeg giver også et resumé og en sammenligning mellem de algoritmer, jeg dækker i del 1, del 2 og del 3.
Jeg vil bruge den samme prøvedatabase kaldet PerformanceV3, som jeg brugte i de tidligere artikler i serien. Bare sørg for, at før du kører eksemplerne i artiklen, skal du først køre følgende kode for at slippe et par unødvendige indekser:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
De eneste to indekser, der skal være tilbage i denne tabel, er idx_cl_od (grupperet med ordredato som nøglen) og PK_Orders (ikke-klynget med ordre-id som nøglen).
Hash Aggregate
Hash Aggregate-algoritmen organiserer grupperne i en hash-tabel baseret på en internt valgt hash-funktion. I modsætning til Stream Aggregate-algoritmen behøver den ikke at forbruge rækkerne i grupperækkefølge. Overvej følgende forespørgsel (vi kalder den forespørgsel 1) som et eksempel (tvinger en hash-aggregat og en seriel plan):
VÆLG empid, COUNT(*) SOM tal FRA dbo.Ordrer GRUPPER EFTER empid OPTION (HASH GROUP, MAXDOP 1);
Figur 1 viser planen for forespørgsel 1.
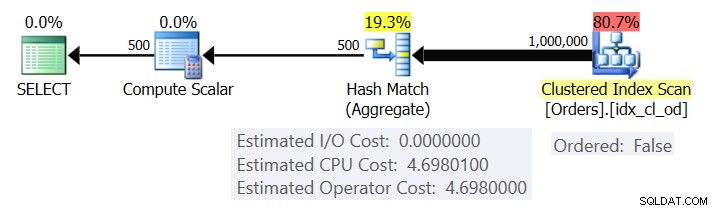
Figur 1:Plan for forespørgsel 1
Planen scanner rækkerne fra det klyngede indeks ved hjælp af en Ordret:Falsk egenskab (scanning er ikke påkrævet for at levere rækkerne, der er bestilt af indeksnøglen). Typisk vil optimeringsværktøjet foretrække at scanne det smalleste dækkende indeks, som i vores tilfælde tilfældigvis er det klyngede indeks. Planen bygger en hash-tabel med de grupperede kolonner og aggregaterne. Vores forespørgsel anmoder om en INT-type COUNT aggregat. Planen beregner den faktisk som en BIGINT-type værdi, deraf Compute Scalar-operatoren, der anvender implicit konvertering til INT.
Microsoft deler ikke offentligt de hash-algoritmer, som de bruger. Dette er meget proprietær teknologi. Alligevel, for at illustrere konceptet, lad os antage, at SQL Server bruger % 250 (modulo 250) hash-funktionen til vores forespørgsel ovenfor. Før vi behandler nogen rækker, har vores hash-tabel 250 buckets, der repræsenterer de 250 mulige udfald af hash-funktionen (0 til 249). Når SQL Server behandler hver række, anvender den hash-funktionen
orderid empid ------- ----- 320 330 5660 253820 3850 11000 255700 31240 253350 4400 255
Figur 2 viser tre tilstande af hash-tabellen:før nogen rækker er behandlet, efter de første 5 rækker er behandlet, og efter de første 10 rækker er behandlet. Hvert element på den linkede liste indeholder tuple (empid, COUNT(*)).
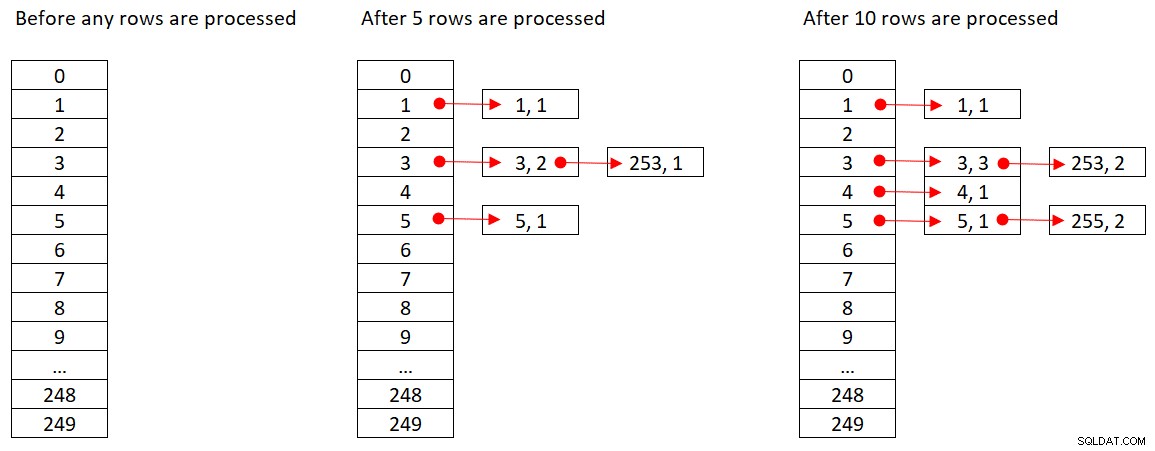
Figur 2:Hash-tabeltilstande
Når Hash Aggregate-operatoren er færdig med at forbruge alle inputrækker, har hashtabellen alle grupper med den endelige tilstand af aggregatet.
Ligesom Sort-operatoren kræver Hash Aggregate-operatoren en hukommelsesbevilling, og hvis den løber tør for hukommelse, skal den spildes til tempdb; hvorimod sortering kræver en hukommelsesbevilling, der er proportional med antallet af rækker, der skal sorteres, kræver hashing en hukommelsesbevilling, der er proportional med antallet af grupper. Så især når grupperingssættet har høj tæthed (lille antal grupper), kræver denne algoritme betydeligt mindre hukommelse, end når eksplicit sortering er påkrævet.
Overvej følgende to forespørgsler (kald dem forespørgsel 1 og forespørgsel 2):
SELECT empid, COUNT(*) AS nummorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); VÆLG empid, COUNT(*) SOM tal FRA dbo.Ordrer GRUPPER EFTER empid OPTION (ORDER GROUP, MAXDOP 1);
Figur 3 sammenligner hukommelsesbevillingerne for disse forespørgsler.

Figur 3:Planer for forespørgsel 1 og forespørgsel 2
Læg mærke til den store forskel mellem hukommelsesbevillingerne i de to sager.
Hvad angår Hash Aggregate-operatørens omkostninger, skal du gå tilbage til figur 1 og bemærke, at der ikke er nogen I/O-omkostninger, snarere kun en CPU-omkostning. Prøv derefter at omdanne CPU-omkostningsformlen ved at bruge lignende teknikker som dem, jeg dækkede i de foregående dele i serien. De faktorer, der potentielt kan påvirke operatørens omkostninger, er antallet af inputrækker, antallet af outputgrupper, den anvendte aggregerede funktion, og hvad du grupperer efter (kardinalitet af grupperingssæt, anvendte datatyper).
Du ville forvente, at denne operatør har en opstartsomkostning som forberedelse til at bygge hashtabellen. Du ville også forvente, at det skal skaleres lineært med hensyn til antallet af rækker og grupper. Det er faktisk hvad jeg fandt. Men mens omkostningerne for både Stream Aggregate- og Sort-operatørerne ikke påvirkes af, hvad du grupperer efter, ser det ud til, at prisen for Hash Aggregate-operatøren er - både hvad angår kardinalitet af grupperingssættet og de anvendte datatyper.
For at observere, at grupperingssættets kardinalitet påvirker operatørens omkostninger, skal du kontrollere CPU-omkostningerne for Hash Aggregate-operatørerne i planerne for følgende forespørgsler (kald dem Query 3 og Query 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1 );
Selvfølgelig vil du sikre dig, at det estimerede antal inputrækker og outputgrupper er det samme i begge tilfælde. De estimerede planer for disse forespørgsler er vist i figur 4.
Figur 4:Planer for forespørgsel 3 og forespørgsel 4
Som du kan se, er CPU-omkostningerne for Hash Aggregate-operatoren 0,16903 ved gruppering efter en heltalskolonne og 0,174016 ved gruppering efter to heltalskolonner, alt andet lige. Dette betyder, at grupperingssættets kardinalitet faktisk påvirker omkostningerne.
Med hensyn til om datatypen for det grupperede element påvirker prisen, brugte jeg følgende forespørgsler til at kontrollere dette (kald dem forespørgsel 5, forespørgsel 6 og forespørgsel 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FRA dbo.Orders) AS D GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 SOM SMALLINT) OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); VÆLG CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FRA dbo.Orders) AS D GROUP BY CAST(orderid AS BIGINT) % CAST(1000) AS BIGINT) OPTION(HASH GROUP, MAXDOP 1);
Planerne for alle tre forespørgsler har det samme estimerede antal inputrækker og outputgrupper, men alligevel får de alle forskellige estimerede CPU-omkostninger (0,121766, 0,16903 og 0,171716), og derfor påvirker den anvendte datatype omkostningerne.
Typen af aggregeret funktion ser også ud til at have indflydelse på omkostningerne. Overvej f.eks. følgende to forespørgsler (kald dem forespørgsel 8 og forespørgsel 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS nummorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Den estimerede CPU-omkostning for Hash Aggregate i planen for Query 8 er 0,166344, og i Query 9 er 0,16903.
Det kunne være en interessant øvelse at prøve at finde ud af præcis, på hvilken måde grupperingssættets kardinalitet, datatyperne og den anvendte aggregerede funktion påvirker omkostningerne; Jeg forfulgte bare ikke dette aspekt af omkostningsberegningen. Så efter at have truffet et valg af grupperingssættet og aggregeringsfunktionen for din forespørgsel, kan du omvendt manipulere kalkulationsformlen. Lad os f.eks. ændre CPU-omkostningsformlen for Hash Aggregate-operatoren, når vi grupperer efter en enkelt heltalskolonne og returnerer MAX(orderdate)-aggregatet. Formlen skal være:
Operatør CPU-omkostning =Ved at bruge de teknikker, som jeg demonstrerede i de tidligere artikler i serien, fik jeg følgende omvendt konstruerede formel:
Operatør CPU-pris =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Du kan kontrollere nøjagtigheden af formlen ved at bruge følgende forespørgsler:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Jeg får følgende resultater:
numrows numgroups forudsagte omkostninger estimerede omkostninger------------------------------------------------------------------- ------- 100000 1000 0,703315 0,703316100000 2000 0,721023 0,721024200000 3000 1.40659 1.40659200000 6000 1.45972 1.45972500000 5000 3.44558 3.44555500000 10000 3,53412 3,53412 <- <- <(Pre>Formlen ser ud til at være i orden.
Omkostningsoversigt og sammenligning
Nu har vi omkostningsformlerne for de tre tilgængelige strategier:forudbestilt Stream Aggregate, Sort + Stream Aggregate og Hash Aggregate. Følgende tabel opsummerer og sammenligner omkostningsegenskaberne for de tre algoritmer:
| Forudbestilt streamaggregat | Sortér + Stream Samlet | Hash Aggregate | |
| Formel | @numrows * 0,0000006 + @numrows * 0,0000005 | 0,0112613 + Lille antal rækker: 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 Stort antal rækker: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0,0000006 + @antalgrupper * 0,0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
* Gruppering efter enkelt heltalskolonne, returnerer MAX( |
| Skalering | lineær | n log n | lineær |
| Start I/O-omkostninger | ingen | 0,0112613 | ingen |
| Start-CPU-omkostninger | ingen | ~ 0,0001 | 0,017749 |
Ifølge disse formler viser figur 5 måden, hvorpå hver af strategierne skalerer for forskellige antal inputrækker, ved at bruge et fast antal grupper på 500 som eksempel.
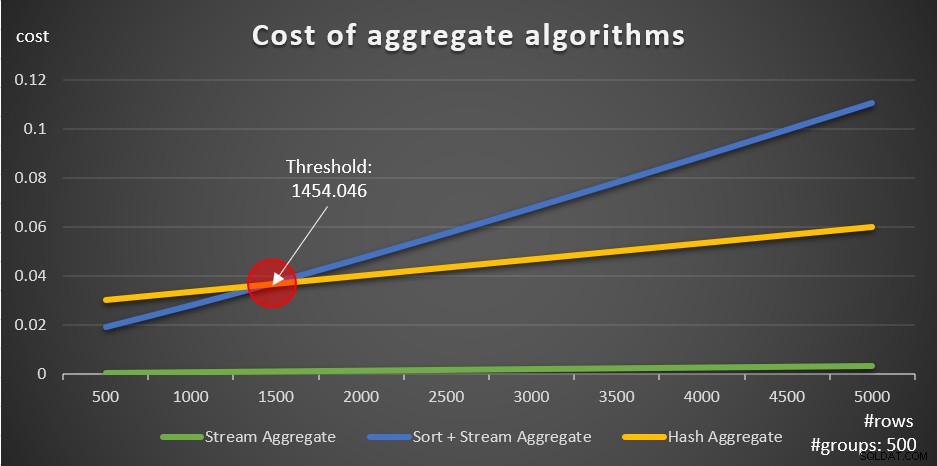
Figur 5:Omkostninger til aggregerede algoritmer
Du kan tydeligt se, at hvis dataene er forudbestilt, f.eks. i et dækkende indeks, er den forudbestilte Stream Aggregate-strategi den bedste mulighed, uanset hvor mange rækker der er involveret. Antag for eksempel, at du skal forespørge i ordretabellen og beregne den maksimale ordredato for hver medarbejder. Du opretter følgende dækkende indeks:
OPRET INDEX idx_eid_od PÅ dbo.Orders(empid, orderdate);
Her er fem forespørgsler, der emulerer en ordretabel med forskellige antal rækker (10.000, 20.000, 30.000, 40.000 og 50.000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Figur 6 viser planerne for disse forespørgsler.
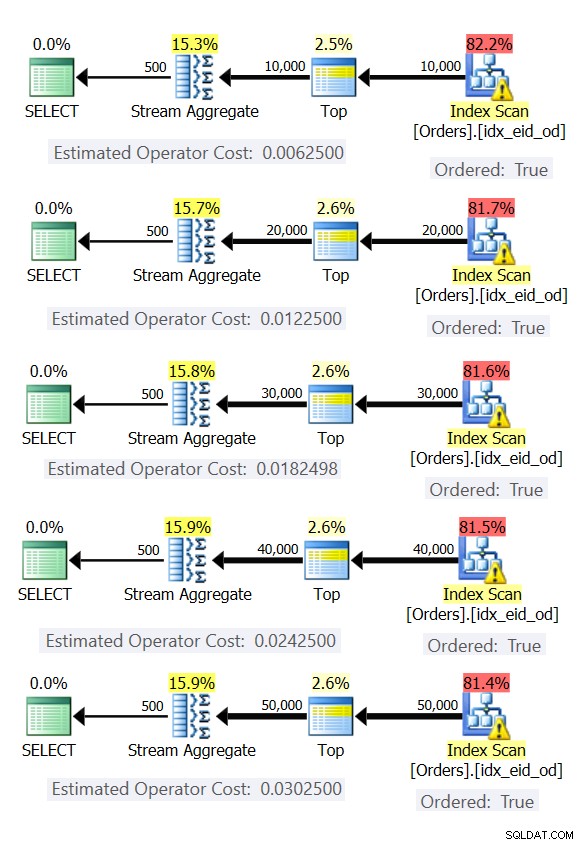
Figur 6:Planer med forudbestilt Stream Aggregate-strategi
I alle tilfælde udfører planerne en bestilt scanning af det dækkende indeks og anvender Stream Aggregate-operatoren uden behov for eksplicit sortering.
Brug følgende kode til at slette det indeks, du oprettede til dette eksempel:
DROP INDEX idx_eid_od ON dbo.Orders;
Den anden vigtige ting at bemærke om graferne i figur 5 er, hvad der sker, når dataene ikke er forudbestilt. Dette sker, når der ikke er noget dækkende indeks på plads, såvel som når du grupperer efter manipulerede udtryk i modsætning til basiskolonner. Der er en optimeringstærskel - i vores tilfælde på 1454.046 rækker - under hvilken Sort + Stream Aggregate-strategien har en lavere pris, og på eller over hvilken Hash Aggregate-strategien har en lavere pris. Dette har at gøre med, at førstnævnte hash en lavere opstartsomkostning, men skalerer på en n log n måde, hvorimod sidstnævnte har en højere opstartsomkostning, men skalerer lineært. Dette gør førstnævnte foretrukket med et lille antal inputrækker. Hvis vores omvendt manipulerede formler er nøjagtige, bør følgende to forespørgsler (kald dem forespørgsel 10 og forespørgsel 11) have forskellige planer:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FRA dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FRA dbo.Orders) AS D GROUP BY orderid % 500;
Planerne for disse forespørgsler er vist i figur 7.
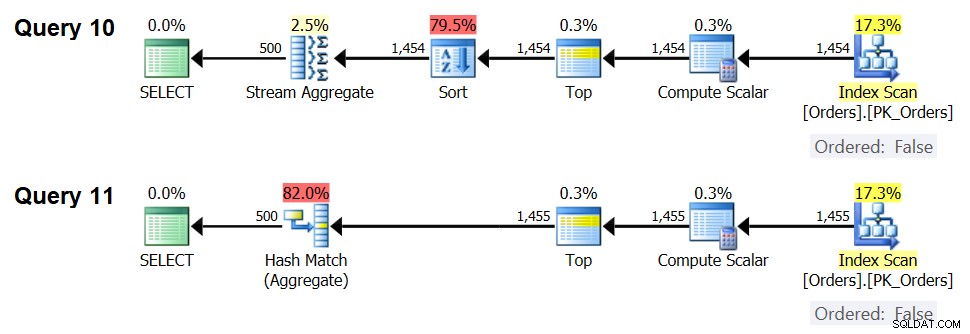
Figur 7:Planer for forespørgsel 10 og forespørgsel 11
Med 1.454 inputrækker (under optimeringstærsklen) foretrækker optimeringsværktøjet naturligvis Sort + Stream Aggregate-algoritmen til forespørgsel 10, og med 1.455 inputrækker (over optimeringstærsklen) foretrækker optimizeren naturligvis Hash Aggregate-algoritmen for Query. .
Potentiale for Adaptive Aggregate-operatør
Et af de vanskelige aspekter af optimeringstærskler er parameter-sniffing-problemer, når der bruges parameterfølsomme forespørgsler i lagrede procedurer. Betragt følgende lagrede procedure som et eksempel:
OPRET ELLER ÆNDRING PROC dbo.EmpOrders @initialorderid AS INTAS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid>=@initialorderid GROUP BY empid;GO
Du opretter følgende optimale indeks til at understøtte forespørgslen om lagret procedure:
OPRET INDEX idx_oid_i_eid PÅ dbo.Orders(orderid) INCLUDE(empid);
Du oprettede indekset med orderid som nøglen til at understøtte forespørgslens områdefilter og inkluderede empid til dækning. Dette er en situation, hvor du ikke rigtig kan oprette et indeks, der både understøtter områdefilteret og har de filtrerede rækker forudbestilt af grupperingssættet. Dette betyder, at optimeringsværktøjet bliver nødt til at vælge mellem Sort + stream Aggregate og Hash Aggregate algoritmerne. Baseret på vores omkostningsformler er optimeringstærsklen mellem 937 og 938 inputrækker (lad os sige 937,5 rækker).
Antag, at du udfører den lagrede procedure første gang med et indledende ordre-id, der giver dig et lille antal matches (under tærsklen):
EXEC dbo.EmpOrders @initialorderid =999991;
SQL Server producerer en plan, der bruger Sort + Stream Aggregate-algoritmen og cacher planen. Efterfølgende eksekveringer genbruger den cachelagrede plan, uanset hvor mange rækker der er involveret. For eksempel har følgende udførelse et antal matches over optimeringstærsklen:
EXEC dbo.EmpOrders @initialorderid =990001;
Alligevel genbruger den den cachelagrede plan på trods af, at den ikke er optimal til denne udførelse. Det er et klassisk parametersniffningsproblem.
SQL Server 2017 introducerer adaptive forespørgselsbehandlingsfunktioner, som er designet til at klare sådanne situationer ved at bestemme under udførelse af forespørgsler, hvilken strategi der skal anvendes. Blandt disse forbedringer er en Adaptive Join-operatør, som under udførelsen bestemmer, om en Loop- eller Hash-algoritme skal aktiveres baseret på en beregnet optimeringstærskel. Vores samlede historie beder om en lignende Adaptive Aggregate-operatør, som under udførelsen ville træffe et valg mellem en Sort + Stream Aggregate-strategi og en Hash Aggregate-strategi baseret på en beregnet optimeringstærskel. Figur 8 illustrerer en pseudoplan baseret på denne idé.
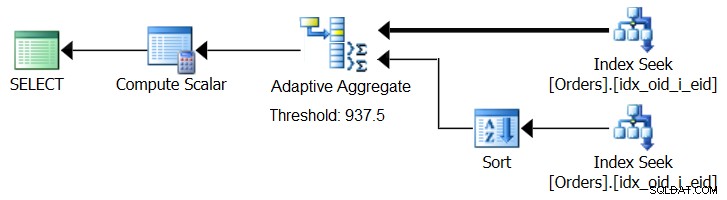
Figur 8:Pseudoplan med Adaptive Aggregate-operatør
For nu, for at få en sådan plan, skal du bruge Microsoft Paint. Men da konceptet med adaptiv forespørgselsbehandling er så smart og fungerer så godt, er det kun rimeligt at forvente at se yderligere forbedringer på dette område i fremtiden.
Kør følgende kode for at slette det indeks, du oprettede til dette eksempel:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Konklusion
I denne artikel dækkede jeg omkostningerne og skaleringen af Hash Aggregate-algoritmen og sammenlignede den med Stream Aggregate og Sort + Stream Aggregate-strategierne. Jeg beskrev den optimeringstærskel, der eksisterer mellem strategierne Sort + Stream Aggregate og Hash Aggregate. Med et lille antal inputrækker foretrækkes førstnævnte og med store tal sidstnævnte. Jeg beskrev også potentialet for at tilføje en Adaptive Aggregate-operator, svarende til den allerede implementerede Adaptive Join-operator, for at hjælpe med at håndtere parameter-sniffing-problemer ved brug af parameterfølsomme forespørgsler. Næste måned vil jeg fortsætte diskussionen ved at dække parallelle overvejelser og sager, der kræver omskrivninger af forespørgsler.