Først introduceret i SQL Server 2017 Enterprise Edition, et tilpasset join aktiverer en kørselsovergang fra en hash-sammenføjning i batchtilstand til en korreleret indlejret sløjfe med en rækketilstand, der indekseres (anvend) under kørsel. For kortheds skyld vil jeg henvise til en "korreleret indlejret sløjfer indekseret joinforbindelse" som en anvend gennem resten af denne artikel. Hvis du har brug for en genopfriskning af forskellen mellem indlejrede løkker og anvende, kan du se min tidligere artikel.
Hvorvidt en adaptiv joinforbindelse overgår fra en hash-join til at anvende ved kørsel afhænger af en værdi mærket Adaptive Threshold Rows på Adaptive Join operatør af udførelsesplan. Denne artikel viser, hvordan en adaptiv joinforbindelse fungerer, inkluderer detaljer om tærskelberegningen og dækker implikationerne af nogle af de designvalg, der er foretaget.
Introduktion
En ting, jeg vil have dig til at huske på i hele dette stykke, er en adaptiv joinforbindelse altid begynder at udføre som en batch mode hash join. Dette er sandt, selvom udførelsesplanen angiver, at den adaptive join forventer at køre som en rækketilstand.
Som enhver hash-join læser en adaptiv join alle rækker, der er tilgængelige på dens build-input, og kopierer de nødvendige data til en hash-tabel. Batch-tilstanden af hash join gemmer disse rækker i et optimeret format og opdeler dem ved hjælp af en eller flere hash-funktioner. Når build-inputtet er blevet brugt, er hash-tabellen fuldt udfyldt og opdelt, klar til hash-joinet for at begynde at tjekke probe-side rækker for matches.
Dette er det punkt, hvor en adaptiv joinforbindelse gør beslutningen om at fortsætte med batch-tilstand hash join eller overgang til en rækketilstand gældende. Hvis antallet af rækker i hashtabellen er mindre end tærsklen værdi, joinforbindelsen skifter til en anvende; ellers fortsætter joinforbindelsen som en hash-join ved at begynde at læse rækker fra sondeinputtet.
Hvis der sker en overgang til en anvende-sammenføjning, genlæser eksekveringsplanen ikke de rækker, der bruges til at udfylde hash-tabellen for at drive anvendelseshandlingen. I stedet en intern komponent kendt som en adaptiv bufferlæser udvider rækkerne, der allerede er gemt i hash-tabellen, og gør dem tilgængelige on-demand for den ydre input fra anvende-operatøren. Der er en omkostning forbundet med den adaptive bufferlæser, men den er meget lavere end omkostningerne ved at spole fuldstændigt tilbage i build-inputtet.
Valg af en Adaptive Join
Forespørgselsoptimering involverer en eller flere stadier af logisk udforskning og fysisk implementering af alternativer. På hvert trin, når optimeringsværktøjet udforsker de fysiske muligheder for en logisk join, kan det overveje at både batch-tilstand hash join og rækketilstand anvender alternativer.
Hvis en af disse fysiske tilslutningsmuligheder er en del af den billigste løsning, der findes i den nuværende fase—og den anden type joinforbindelse kan levere de samme nødvendige logiske egenskaber – optimeringsværktøjet markerer den logiske join-gruppe som potentielt velegnet til en adaptiv sammenføjning. Hvis ikke, slutter overvejelse af en adaptiv joinforbindelse her (og ingen adaptiv join-forlænget begivenhed udløses).
Den normale drift af optimeringsværktøjet betyder, at den billigste løsning, der findes, kun vil inkludere en af de fysiske joinmuligheder - enten hash eller anvende, alt efter hvad der havde den laveste estimerede pris. Den næste ting, optimizeren gør, er at bygge og koste en ny implementering af den type join, der ikke var valgt som billigste.
Da den nuværende optimeringsfase allerede er afsluttet med den billigste løsning, der er fundet, udføres en særlig enkelt-gruppe udforskning og implementeringsrunde for den adaptive join. Til sidst beregner optimeringsværktøjet den adaptive tærskel .
Hvis noget af det foregående arbejde mislykkes, udløses den udvidede begivenhed adaptive_join_skipped med en årsag.
Hvis den adaptive sammenføjningsbehandling er vellykket, vises en Concat operatør føjes til den interne plan over hashen og anvender alternativer med den adaptive bufferlæser og eventuelle nødvendige batch-/rækketilstandsadaptere. Husk, at kun et af join-alternativerne vil køre under kørsel, afhængigt af antallet af rækker, der faktisk stødes på sammenlignet med den adaptive tærskel.
Den Concat operatør og individuelle hash-/anvend-alternativer vises normalt ikke i den endelige udførelsesplan. Vi bliver i stedet præsenteret for en enkelt Adaptive Join operatør. Dette er kun en præsentationsbeslutning – Concat og joins er stadig til stede i koden, der køres af SQL Server-udførelsesmotoren. Du kan finde flere detaljer om dette i appendiks og relateret læsning i denne artikel.
Den adaptive tærskel
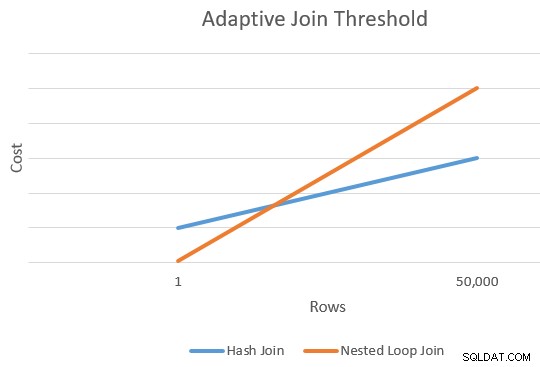
En application er generelt billigere end en hash join for et mindre antal kørerækker. Hash-join har en ekstra opstartsomkostning til at bygge sin hash-tabel, men en lavere pris pr. række, når den begynder at søge efter kampe.
Der er generelt et punkt, hvor de anslåede omkostninger ved en application og hash join vil være ens. Denne idé blev godt illustreret af Joe Sack i hans artikel, Introducing Batch Mode Adaptive Joins:
Beregning af tærskelværdien
På dette tidspunkt har optimeringsværktøjet et enkelt estimat for antallet af rækker, der indtaster build-input af hash-sammenføjningen og anvender alternativer. Det har også de estimerede omkostninger for hash og anvende operatører som helhed.
Dette giver os et enkelt punkt på den yderste højre kant af de orange og blå linjer i diagrammet ovenfor. Optimeringsværktøjet har brug for et andet referencepunkt for hver forbindelsestype, så den kan "tegne linjerne" og finde skæringspunktet (den tegner ikke bogstaveligt talt linjer, men du forstår ideen).
For at finde et andet punkt for linjerne beder optimeringsværktøjet de to sammenføjninger om at producere et nyt omkostningsestimat baseret på en anden (og hypotetisk) inputkardinalitet. Hvis det første kardinalitetsestimat var mere end 100 rækker, beder det joins om at estimere nye omkostninger for én række. Hvis den oprindelige kardinalitet var mindre end eller lig med 100 rækker, er det andet punkt baseret på en inputkardinalitet på 10.000 rækker (så der er et anstændigt nok interval til at ekstrapolere).
Under alle omstændigheder er resultatet to forskellige omkostninger og rækkeantal for hver sammenføjningstype, hvilket gør det muligt at "trække linjerne".
Krydsningsformlen
At finde skæringspunktet mellem to linjer ud fra to punkter for hver linje er et problem med flere velkendte løsninger. SQL Server bruger en baseret på determinanter som beskrevet på Wikipedia:
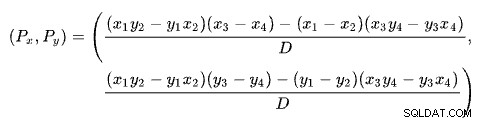
hvor:
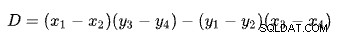
Den første linje er defineret af punkterne (x1 , y1 ) og (x2 , y2 ). Den anden linje er givet af punkterne (x3 , y3 ) og (x4 , y4 ). Krydset er ved (Px , Py ).
Vores skema har antallet af rækker på x-aksen og de anslåede omkostninger på y-aksen. Vi er interesserede i antallet af rækker, hvor linjerne skærer hinanden. Dette er givet af formlen for Px . Hvis vi ville kende den estimerede omkostning ved krydset, ville det være Py .
For Px rækker, ville de estimerede omkostninger ved application og hash join-løsningerne være lige store. Dette er den adaptive tærskel, vi har brug for.
Et udført eksempel
Her er et eksempel, der bruger AdventureWorks2017 eksempeldatabasen og følgende indekseringstrick af Itzik Ben-Gan for at få ubetinget overvejelse af udførelse af batch-tilstand:
-- Itziks trick OPRET IKKE-KLUSTERET KOLUMNEBUTIKINDEKS BatchModeON Sales.SalesOrderHeader (SalesOrderID)WHERE SalesOrderID =-1AND SalesOrderID =-2; -- TestforespørgselSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123;
Udførelsesplanen viser en adaptiv joinforbindelse med en tærskel på 1502.07 rækker:
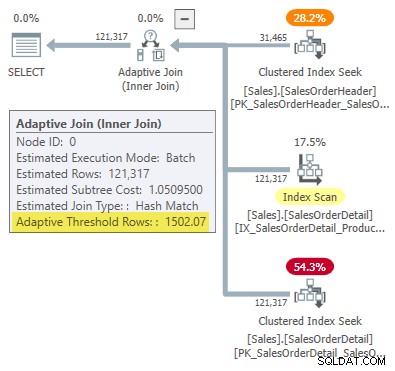
Det estimerede antal rækker, der driver den adaptive joinforbindelse, er 31.465 .
Deltagelsesomkostninger
I dette forenklede tilfælde kan vi finde estimerede undertræsomkostninger for hashen og anvende join-alternativer ved hjælp af tip:
-- HashSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION (HASH JOIN, MAXDOP );

-- ApplySELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION (LOOP JOIN, MAXDOP );
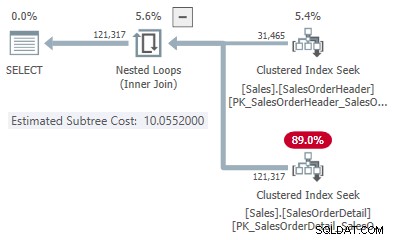
Dette giver os et punkt på linjen for hver jointype:
- 31.465 rækker
- Hash-pris 1,05083
- Anvend pris 10,0552
Det andet punkt på linjen
Da det estimerede antal rækker er mere end 100, kommer de andre referencepunkter fra specielle interne estimater baseret på én join-input-række. Desværre er der ingen nem måde at få de nøjagtige omkostningstal for denne interne beregning (jeg vil fortælle mere om dette kort).
Indtil videre vil jeg bare vise dig omkostningstallene (ved at bruge den fulde interne præcision i stedet for de seks væsentlige tal præsenteret i udførelsesplaner):
- En række (intern beregning)
- Hash-pris 0,999027422729
- Anvend pris 0,547927305023
- 31.465 rækker
- Hash-pris 1,05082787359
- Anvend pris 10,0552890166
Som forventet er appliceringsforbindelsen billigere end hashen for en lille inputkardinalitet, men meget dyrere for den forventede kardinalitet på 31.465 rækker.
Skæringsberegningen
Hvis du tilslutter disse kardinalitets- og omkostningstal i linjekrydsformlen, får du følgende:
-- Hash-point (x =kardinalitet; y =pris) DEKLARE @x1 float =1, @y1 float =0,999027422729, @x2 float =31465, @y2 float =1,05082787359; -- Anvend point (x =kardinalitet; y =pris) DECLARE @x3 float =1, @y3 float =0,547927305023, @x4 float =31465, @y4 float =10,0552890166; -- Formel:SELECT Threshold =( (@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) - (@x1 - @x2) * (@x3 * @y4 - @y3 * @x4) ) ) / ( (@x1 - @x2) * (@y3 - @y4) - (@y1 - @y2) * (@x3 - @x4) ); -- Returnerer 1502.06521571273
Afrundet til seks signifikante cifre svarer dette resultat til 1502.07 rækker vist i den adaptive join-udførelsesplan:
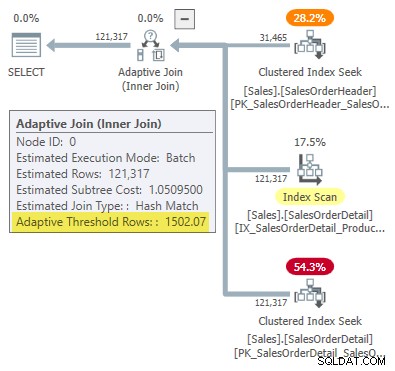
Defekt eller design?
Husk, at SQL Server skal bruge fire punkter for at "tegne" rækkeantallet i forhold til omkostningerne for at finde den adaptive join-tærskel. I det foreliggende tilfælde betyder det, at man skal finde omkostningsestimater for kardinaliteterne med én række og 31.465 rækker for både applicerings- og hash join-implementeringer.
Optimizeren kalder en rutine ved navn sqllang!CuNewJoinEstimate at beregne disse fire omkostninger for en adaptiv sammenføjning. Desværre er der ingen sporingsflag eller udvidede begivenheder til at give et praktisk overblik over denne aktivitet. De normale sporingsflag, der bruges til at undersøge optimeringsadfærd og visningsomkostninger, fungerer ikke her (se appendiks, hvis du er interesseret i flere detaljer).
Den eneste måde at opnå omkostningsestimaterne på én række er at vedhæfte en debugger og indstille et brudpunkt efter det fjerde kald til CuNewJoinEstimate i koden for sqllang!CardSolveForSwitch . Jeg brugte WinDbg til at få denne opkaldsstak på SQL Server 2019 CU12:

På dette tidspunkt i koden gemmes omkostninger til flydende point med dobbelt præcision i fire hukommelsesplaceringer, der peges på af adresser på rsp+b0 , rsp+d0 , rsp+30 , og rsp+28 (hvor rsp er et CPU-register og forskydninger er i hexadecimal):

De viste omkostningsnumre for operatørundertræet matcher dem, der bruges i den adaptive join-tærskelberegningsformel.
Om disse omkostningsestimater på én række
Du har måske bemærket, at de estimerede undertræsomkostninger for sammenføjninger på én række virker ret høje i forhold til den mængde arbejde, der er involveret i at sammenføje en række:
- En række
- Hash-pris 0,999027422729
- Anvend pris 0,547927305023
Hvis du forsøger at lave en række input-udførelsesplaner for hash-joint og anvende eksempler, vil du se meget lavere estimerede undertræsomkostninger ved sammenføjningen end dem, der er vist ovenfor. Ligeledes vil kørsel af den oprindelige forespørgsel med et rækkemål på én (eller antallet af sammenføjningsoutputrækker, der forventes for et input på én række), også give en estimeret pris måde lavere end vist.
Årsagen er CuNewJoinEstimate rutine estimerer en-rækken tilfælde på en måde, som jeg tror, de fleste mennesker ikke ville finde intuitive.
De endelige omkostninger består af tre hovedkomponenter:
- Udgiften til byggeinput-undertræet
- De lokale omkostninger ved sammenføjningen
- Omkostningerne til undertræet for sondeinput
Punkt 2 og 3 afhænger af typen af sammenføjning. For en hash-join står de for omkostningerne ved at læse alle rækkerne fra sonde-inputtet, matche dem (eller ej) med den ene række i hash-tabellen og sende resultaterne videre til den næste operatør. For en ansøgning dækker omkostningerne én søgning på det lavere input til joinforbindelsen, de interne omkostninger ved selve joinforbindelsen og returnering af de matchede rækker til den overordnede operatør.
Intet af dette er usædvanligt eller overraskende.
Omkostningsoverraskelsen
Overraskelsen kommer på byggesiden af sammenføjningen (punkt 1 i listen). Man kunne forvente, at optimeringsværktøjet laver en fancy beregning for at skalere de allerede beregnede undertræomkostninger for 31.465 rækker ned til en gennemsnitlig række eller noget i den stil.
Faktisk bruger både hash- og appliceringsestimater for en række joinforbindelser blot hele undertræets omkostninger for original kardinalitetsestimat på 31.465 rækker. I vores kørende eksempel er dette "undertræ" 0,54456 omkostningerne ved batch-tilstanden klynget indekssøgning på overskriftstabellen:
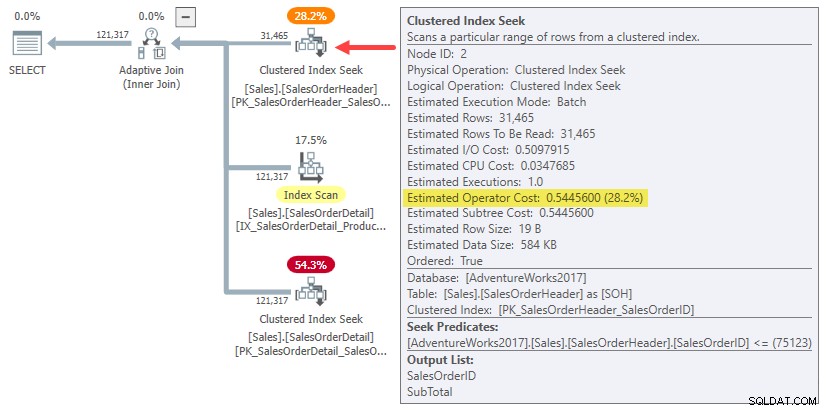
For at være klar:De estimerede omkostninger på byggesiden for alternativerne med én række sammenføjning bruger en inputomkostning beregnet for 31.465 rækker. Det burde virke lidt underligt.
Som en påmindelse er omkostningerne på én række beregnet af CuNewJoinEstimate var som følger:
- En række
- Hash-pris 0,999027422729
- Anvend pris 0,547927305023
Du kan se, at de samlede ansøgningsomkostninger (~0,54793) er domineret af 0,54456 build-side subtree-omkostninger, med et lille ekstra beløb for den enkelte inderside-søgning, behandling af det lille antal resulterende rækker i join-forbindelsen og videregivelse af dem til den overordnede operatør.
De estimerede en-rækkes hash joinomkostninger er højere, fordi probesiden af planen består af en fuld indeksscanning, hvor alle resulterende rækker skal passere gennem sammenføjningen. Den samlede pris for hash-sammenføjningen på én række er lidt lavere end den oprindelige pris på 1,05095 for eksemplet med 31.465 rækker, fordi der nu kun er én række i hashtabellen.
Konsekvenser
Man ville forvente, at et estimat med én række tilslutning til dels er baseret på omkostningerne ved at levere én række til input til køresammenføjningen. Som vi har set, er dette ikke tilfældet for en adaptiv joinforbindelse:både applicerings- og hash-alternativer er belemret med de fulde estimerede omkostninger for 31.465 rækker. Resten af sammenføjningen koster stort set, som man ville forvente for et input på én række.
Dette intuitivt mærkelige arrangement er grunden til, at det er svært (måske umuligt) at vise en udførelsesplan, der afspejler de beregnede omkostninger. Vi bliver nødt til at konstruere en plan, der leverer 31.465 rækker til det øverste join-input, men som koster selve join-en og dets indre input, som om kun én række var til stede. Et svært spørgsmål.
Effekten af alt dette er at hæve punktet længst til venstre på vores skærende linjediagram op ad y-aksen. Dette påvirker linjens hældning og dermed skæringspunktet.
En anden praktisk effekt er, at den beregnede adaptive join-tærskel nu afhænger af det oprindelige kardinalitetsestimat ved hash-building-inputtet, som bemærket af Joe Obbish i sit blogindlæg fra 2017. For eksempel, hvis vi ændrer WHERE klausul i testforespørgslen til SOH.SalesOrderID <= 55000 , den adaptive tærskel reducerer fra 1502.07 til 1259.8 uden at ændre forespørgselsplanens hash. Samme plan, anden tærskel.
Dette opstår, fordi det interne omkostningsestimat på én række, som vi har set, afhænger af byggeinputomkostningerne for det oprindelige kardinalitetsestimat. Dette betyder, at forskellige initiale estimater på byggesiden vil give et andet "boost" på y-aksen til estimatet på én række. Til gengæld vil linjen have en anden hældning og et andet skæringspunkt.
Intuitionen vil foreslå, at one-row estimatet for den samme join altid skal give den samme værdi uanset den anden kardinalitetsestimat på linjen (givet nøjagtig samme join med de samme egenskaber og rækkestørrelser har en tæt-til-lineær sammenhæng mellem kørsel rækker og pris). Dette er ikke tilfældet for en adaptiv joinforbindelse.
Ved design?
Jeg kan med en vis tillid fortælle dig, hvad SQL Server gør ved beregning af den adaptive join-tærskel. Jeg har ikke nogen særlig indsigt i hvorfor det gør det på denne måde.
Alligevel er der nogle grunde til at tro, at dette arrangement er bevidst og opstod efter behørig overvejelse og feedback fra test. Resten af dette afsnit dækker nogle af mine tanker om dette aspekt.
En adaptiv joinforbindelse er ikke et lige valg mellem en normal anvendelses- og batch-mode hash joinforbindelse. En adaptiv join starter altid med at udfylde hashtabellen fuldt ud. Først når dette arbejde er afsluttet, træffes beslutningen om at skifte til en anvendelsesimplementering eller ej.
På dette tidspunkt har vi allerede afholdt potentielt betydelige omkostninger ved at udfylde og opdele hash-joinet i hukommelsen. Dette betyder måske ikke meget for en række tilfælde, men det bliver gradvist vigtigere, efterhånden som kardinaliteten øges. Det uventede "boost" kan være en måde at inkorporere disse realiteter i beregningen og samtidig bevare en rimelig beregningsomkostning.
SQL Server-omkostningsmodellen har længe været en smule forudindtaget i forhold til indlejrede loops join, velsagtens med en vis begrundelse. Selv den ideelle indekserede ansøgning kan være langsom i praksis, hvis de nødvendige data ikke allerede er i hukommelsen, og I/O-undersystemet ikke blinker, især med et noget tilfældig adgangsmønster. Begrænsede mængder hukommelse og træg I/O vil for eksempel ikke være helt ukendt for brugere af lavere cloud-baserede databasemotorer.
Det er muligt, at praktiske tests i sådanne miljøer afslørede, at en intuitivt prissat adaptiv joinforbindelse var for hurtig til at gå over til en ansøgning. Teori er nogle gange kun fantastisk i teorien.
Alligevel er den nuværende situation ikke ideel; cachelagring af en plan baseret på et usædvanligt lavt kardinalitetsestimat vil producere en adaptiv joinforbindelse, der er meget mere tilbageholdende med at skifte til en ansøgning, end den ville have været med et større indledende estimat. Dette er en række af parameterfølsomhedsproblemet, men det vil være en ny overvejelse af denne type for mange af os.
Nu er det også muligt at bruge den fulde opbygning af input-undertræets omkostninger for det punkt længst til venstre på de skærende omkostningslinjer er simpelthen en ukorrigeret fejl eller forglemmelse. Min fornemmelse er, at den nuværende implementering sandsynligvis er et bevidst praktisk kompromis, men du skal have nogen med adgang til designdokumenterne og kildekoden for at vide det med sikkerhed.
Oversigt
En adaptiv joinforbindelse tillader SQL Server at skifte fra en batch-tilstand hash join til en application, efter at hash tabellen er blevet fuldt udfyldt. Den træffer denne beslutning ved at sammenligne antallet af rækker i hash-tabellen med en forudberegnet adaptiv tærskel.
Tærsklen beregnes ved at forudsige, hvor applicerings- og hash join-omkostningerne er ens. For at finde dette punkt producerer SQL Server endnu et internt joinomkostningsestimat for en anden build-input-kardinalitet – normalt én række.
Overraskende nok inkluderer den estimerede omkostning for en-række-estimatet den fulde build-side subtree-omkostning for det oprindelige kardinalitetsestimat (ikke skaleret til én række). Dette betyder, at tærskelværdien afhænger af det oprindelige kardinalitetsestimat ved build-inputtet.
Som følge heraf kan en adaptiv joinforbindelse have en uventet lav tærskelværdi, hvilket betyder, at den adaptive join er meget mindre tilbøjelig til at gå væk fra en hash-join. Det er uklart, om denne adfærd er ved design.
Relateret læsning
- Vi introducerer Batch Mode Adaptive Joins af Joe Sack
- Forstå Adaptive Joins i produktdokumentationen
- Adaptive Join Internals af Dima Pilugin
- Hvordan fungerer Batch Mode Adaptive Joins? om Database Administrators Stack Exchange af Erik Darling
- An Adaptive Join Regression af Joe Obbish
- Hvis du vil have adaptive joinforbindelser, har du brug for bredere indekser og er større bedre? af Erik Darling
- Parameter Sniffing:Adaptive Joins af Brent Ozar
- Intelligent Query Processing Q&A af Joe Sack
Bilag
Dette afsnit dækker et par adaptive join-aspekter, som var svære at inkludere i hovedteksten på en naturlig måde.
Den udvidede adaptive plan
Du kan prøve at se på en visuel repræsentation af den interne plan ved hjælp af udokumenteret sporingsflag 9415, som leveret af Dima Pilugin i hans fremragende adaptive join internals-artikel, der er linket ovenfor. Med dette flag aktivt bliver den adaptive joinplan for vores løbeeksempel følgende:
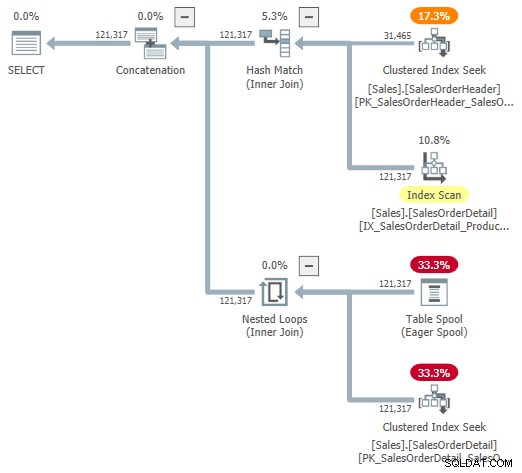
Dette er en nyttig repræsentation for at hjælpe forståelsen, men den er ikke helt nøjagtig, fuldstændig eller konsekvent. For eksempel eksisterer Table Spool ikke – det er en standardrepræsentation for den adaptive bufferlæser læse rækker direkte fra batch-tilstand hash-tabellen.
Operatøregenskaberne og kardinalitetsestimaterne er også lidt over det hele. Outputtet fra den adaptive bufferlæser ("spool") skal være 31.465 rækker, ikke 121.317. Undertræets omkostninger for ansøgningen er forkert begrænset af den overordnede operatørs omkostninger. Dette er normalt for showplan, men det giver ingen mening i en adaptiv join-kontekst.
Der er også andre uoverensstemmelser - for mange til at kunne nævnes - men det kan ske med udokumenterede sporingsflag. Den udvidede plan vist ovenfor er ikke beregnet til brug af slutbrugere, så måske er det ikke helt overraskende. Budskabet her er ikke at stole for meget på de tal og egenskaber, der vises i denne udokumenterede form.
Jeg skal også nævne i forbifarten, at den færdige standard adaptive join plan-operatør ikke er helt uden sine egne konsistensproblemer. Disse stammer stort set udelukkende fra de skjulte detaljer.
For eksempel kommer de viste adaptive joinegenskaber fra en blanding af de underliggende Concat , Hash Join , og Ansøg operatører. Du kan se en adaptiv joinrapportering af batch-tilstand for indlejrede loops join (hvilket er umuligt), og den viste forløbne tid kopieres faktisk fra den skjulte Concat , ikke den særlige join, der blev udført under kørsel.
De sædvanlige mistænkte
Vi kan få nogle nyttige oplysninger fra den slags udokumenterede sporingsflag, der normalt bruges til at se på optimeringsoutput. For eksempel:
SELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION ( QUERYTRACEON 3604, QUERYPRÆR, 8620704, QUERYON, 86207704, QUERYON);Output (stærkt redigeret for at kunne læses):
*** Outputtræ:***
PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Pris=1,05095
- PhyOp_Concat (batch) Card=121317 Pris=1,05325
- PhyOp_HashJoinx_jtInner (batch) Card=121317 Cost=1,05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0,54456
- PhyOp_Filter(batch) Card=121317 Cost=0,397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Cost=0,338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Cost=10,0798
- PhyOp_Apply Card=121317 Cost=10,0553
- PhyOp_ExecutionModeAdapter(BatchTRow) Card=31465 Cost=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0,54456 [** 3 **]
- PhyOp_Filter Card=3,85562 Cost=9,00356
- PhyOp_Range Sales.SalesOrderDetail Card=3,85562 Cost=8,94533
- PhyOp_ExecutionModeAdapter(BatchTRow) Card=31465 Cost=0,544623
- PhyOp_Apply Card=121317 Cost=10,0553
Dette giver et vist indblik i de estimerede omkostninger for fuld-kardinalitetssagen med hash og anvende alternativer uden at skrive separate forespørgsler og bruge tip. Som nævnt i hovedteksten er disse sporingsflag ikke effektive i CuNewJoinEstimate , så vi kan ikke direkte se gentagne beregninger for sagen med 31.465 rækker eller nogen af detaljerne for estimaterne på én række på denne måde.
Flet Join og Row Mode Hash Join
Adaptive joins tilbyder kun en overgang fra batch-tilstand hash join til rækketilstand gælder. For årsagerne til, at rækketilstands-hash join ikke understøttes, se Intelligent Query Processing Q&A i afsnittet Relateret læsning. Kort sagt, menes det, at rækketilstands-hash-sammenføjninger ville være for tilbøjelige til præstationsregressioner.
At skifte til en rækketilstand flet sammenføjning ville være en anden mulighed, men optimeringsværktøjet overvejer ikke dette i øjeblikket. Som jeg forstår det, er det usandsynligt, at det vil blive udvidet i denne retning i fremtiden.
Nogle af overvejelserne er de samme, som de er for row mode hash join. Derudover har merge join-planer en tendens til at være mindre let at udskifte med hash join, selvom vi begrænser os til indekseret sammenføjning (ingen eksplicit sortering).
Der er også en meget større forskel mellem hash og applicering, end der er mellem hash og merge. Både hash og merge er velegnet til større input, og applicer er bedre egnet til en mindre køreinput. Merge join er ikke så let paralleliseret som hash join og skaleres ikke så godt med stigende trådantal.
Givet motivationen for adaptive joinforbindelser er at klare sig bedre med betydeligt varierende inputstørrelser – og kun hash join understøtter batch mode behandling – valget af batch hash versus række anvende er det mere naturlige. Endelig ville det at have tre adaptive join-valg komplicere tærskelberegningen betydeligt for potentielt lille gevinst.