Der er en række måder at kontakte nogen på i disse dage, ikke?
Vi har forskellige telefoner:mobil og fastnet, privat og arbejde. Vi har forskellige adresser – bolig, post, fakturering, forretning osv. – og sandsynligvis også flere e-mailadresser. Glem ikke Skype og forskellige beskedapps. Tilføj nu LinkedIn og Facebook – som i øvrigt begge har deres egne beskedelementer.
For ikke så længe siden eksisterede mange af disse ikke. Så du kan stort set garantere, at vi om nogle år vil have en ny måde at kontakte mennesker og organisationer på.
Kan vi modellere alle disse kontaktoplysninger på en sådan måde, at vi ikke behøver at ændre vores databasedesign, når 'det seneste' kommer? Læs videre for at finde ud af...
Partykontaktpunktmodellen
Med et ord, ja. Databaser kan designes til at rumme oplysninger, vi ikke engang har endnu.
Jeg vil springe direkte ind og vise dig løsningen, så vil jeg beskrive, hvordan brikkerne fungerer sammen. Jeg vil kalde de forskellige måder at kontakte parter på for kontaktpunkter , selvom jeg har set kontaktmetoder og endda kontaktsteder brugt.
Fysisk vil alle disse kontaktpunkter blive gemt i en enkelt tabelkolonne, contact_point.contact_value . Tænk på et telefonnummer, en e-mailadresse eller en webadresse (URL), og du vil forstå, hvorfor vi kan gemme dem alle her; de er bare strenge (varchars) på dette niveau. Differentieringen er i metadataene. Den eneste undtagelse herfra er postadressen, som vil blive beskrevet mere detaljeret senere.
De gule tabeller til venstre indeholder metadata, og de blå tabeller til højre indeholder forretningsdata.
De vigtigste kategorier
Selvom vi har mange måder at kontakte nogen på, falder disse måder faktisk ind i et lille antal kategorier eller typer. Du vil se, hvad jeg mener, når du ser på listen nedenfor:
| Kontaktpunkttype |
|---|
| Telefonnummer (fastnet) |
| Mobilnummer |
| Faxnummer |
| E-mail-adresse |
| Postadresse |
| Webadresse |
| Pager |
I en vis forstand er disse fysisk adskilte. Du kan selvfølgelig bruge en mobiltelefon til at ringe til en fastnettelefon eller en anden mobil. Når det kommer til taleopkald mellem fastnet og mobiler, er skelnen ikke så vigtig. Alligevel er det mere sandsynligt, at vi sender en tekst (SMS) til en mobil end en fastnettelefon.
Men du vil sandsynligvis ikke bevidst taleopkald til et faxnummer. Når alt kommer til alt, hvad skal du sige til den, når du hører den, bortset fra 'Ups, forkert nummer'? Du er naturligvis meget mere tilbøjelig til at ringe med en anden faxmaskine, uanset om den er fysisk eller emuleret. Du ville heller ikke sende et brev til fastnet eller forsøge at foretage et taleopkald til en postadresse.
Det er vigtigt, at vi skelner mellem disse typer, fordi vi interagerer forskelligt med dem. Dette vil især være tilfældet, hvis din applikation har nogen form for integration med kommunikationstjenester. Den skal vide, hvilken type den skal interagere med.
Sådan bruger parterne kontaktpunkter
Dette er nok lidt mere intuitivt, lidt mere i tråd med, hvordan vi tænker om kontakttyper. Her er en længere liste (men ikke en udtømmende!), som vil hjælpe dig med at få en fornemmelse for disse typer:
| Partistkontakttype (kontaktpunkttype) |
|---|
| Konferencelinje (telefonnummer) |
| Faktureringsadresse (Postadresse) |
| Leveringsadresse (Postadresse) |
| Direkte linje (telefonnummer) |
| Ferie-/ferieadresse (Postadresse) |
| Ferie-/ferietelefon (telefonnummer) |
| Hjemmeadresse (Postadresse) |
| Hjemmetelefon (telefonnummer) |
| Hjemmetelefon/fax (telefonnummer) |
| LinkedIn-profil (webadresse) |
| Hovedadresse (Postadresse) |
| Hovedmail (e-mail-adresse) |
| Hovedfax (faxnummer) |
| Hovedtelefon (telefonnummer) |
| Hovedwebsted (webadresse) |
| Personlig e-mail (e-mail-adresse) |
| Personlig fax (faxnummer) |
| Personlig mobil (mobilnummer) |
| Personlig personsøger (Pager) |
| Personligt websted (webadresse) |
| Sekundær adresse (Postadresse) |
| Sekundær telefon (telefonnummer) |
| Profil på sociale medier (webadresse) |
| Arbejdsadresse (Postadresse) |
| Arbejds-e-mail (e-mail-adresse) |
| Arbejdsfax (faxnummer) |
| Arbejdsmobil (mobilnummer) |
| Arbejdstelefon (telefonnummer) |
Postadressen – et særligt tilfælde
Alle disse kontaktpunkttyper er gemt i et enkelt felt, med undtagelse af en postadresse. Dette kræver normalt et antal linjer (eller felter).
Der er en blogartikel her, der foreslår en enkel, sprogagnostisk måde at gemme postadresser på. Hvis dine krav er ret basale – f.eks. at udskrive adresselabels stort set efterhånden som de indtastes i systemet - denne tilgang vil sandsynligvis være tilstrækkelig. Hvis dine behov er mere sofistikerede, bliver du sandsynligvis nødt til at udvikle en anden løsning.
For at få en idé om, hvor kompleks adressering kan være, skal du tage et hurtigt kig på dette skema for British Standard BS7666-adressetyper. Standarden omfatter et antal dele, der dækker Gazetteers, Land and Property Gazetteers og leveringssteder. Den skelner ikke mellem erhvervsejendomme eller boligejendomme; mellem besat, udviklet eller ledigt land; mellem by- eller landområder; eller mellem postadresserbare enheder og ikke-postadresserbare entiteter s såsom kommunikationsmaster (tårne). For at opnå dette introducerer den termer, som de fleste af os sandsynligvis ikke kender, såsom Primary Addressable Object (PAO), som er navnet på et adresserbart objekt, der kan adresseres uden reference til et andet adresserbart objekt. Kendte eksempler på PAO'er omfatter et bygningsnavn eller et vejnummer. Et sekundært adresserbart objekt (SAO) gives til ethvert adresserbart objekt, der er adresseret ved reference til en PAO. Dette kan være første sal i en navngivet bygning.
For at give os en visualisering af dette, reverse-manipulerede jeg det hurtigt til et UML-modelleringsværktøj. Her er, hvad vi får:
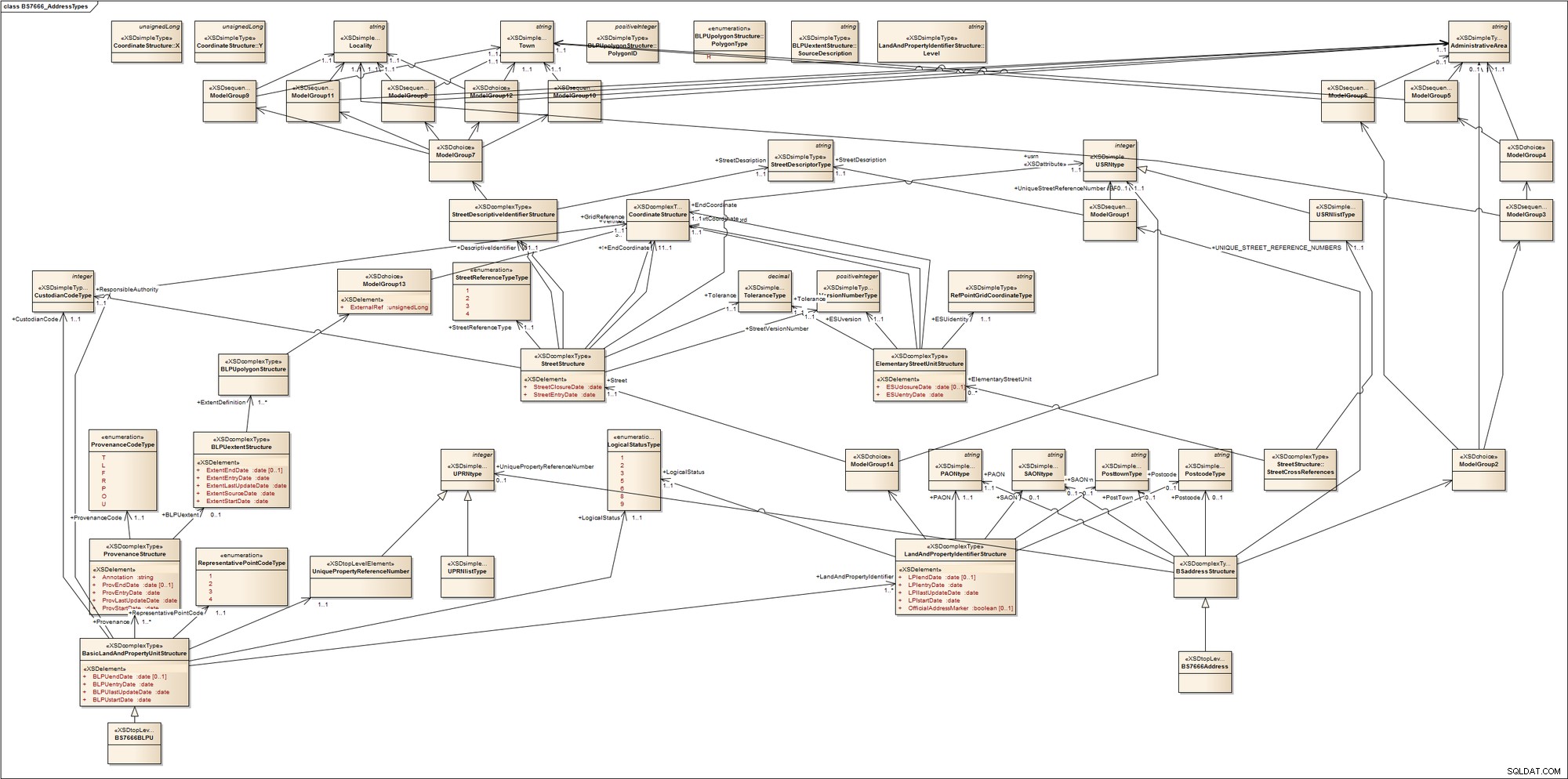
Min pointe er, at det kan blive ret kompliceret og rodet; adressering i nogle domæner kan være meget kompleks.
Hvis du skulle flad dette ud til en enkelt relationstabel, ville du få noget i stil med følgende:
Selvom dette fanger BS7666-adressekomponenter, fortæller det dig ikke, hvordan modellen fungerer. Al den relationelle logik i XML-skemaet bliver gemt væk i applikationslogikken.
Disse to diagrammer repræsenterer to datamodellering ekstremer . Men er der en middelvej til at modellere adresser?
Det er faktisk muligt at have en relativt simpel adressemodel, der er fleksibel og konfigurerbar.
Adressekomponenter
En adressekomponent er typisk en linje på en adresseetiket, eller rettere en type linje på en adresselabel. Den slags komponenter, vi typisk vil bruge til adresser i Storbritannien, er angivet i følgende tabel:
| Adressekomponenttype |
|---|
| Adressat |
| Område |
| Bygningsnavn |
| Bygningsnummer |
| Land |
| Amt |
| Afdelingsnavn |
| Afhængig lokalitet |
| Afhængig færdselsårenavn |
| Dobbelt afhængig lokalitet |
| International postnummer |
| Niveau |
| Lokalitet |
| Mailsort SSC |
| Organisationens navn |
| PAO-slutnummer |
| PAO-slutsuffiks |
| PAO-startnummer |
| PAO-startsuffiks |
| PAO-tekst |
| Postboks |
| Postnummer |
| Postby |
| Postnummer |
| Postnummertype |
| SAO-slutnummer |
| SAO-slutsuffiks |
| SAO-startnummer |
| SAO Start Suffiks |
| SAO-tekst |
| Gade |
| Gadebeskrivelse |
| Underbygningsnavn |
| Grundvejsnavn |
| By |
Du kunne have tre eller fire adresselinjer plus postby og postnummer. Men den vanskelighed, du vil støde på, er at identificere hvad disse linjer faktisk indeholder når det gælder – f.eks. ved kortlægning af data mellem systemer. Når du foretager dataprofilering, vil du opleve, at Adresselinje 3 nogle gange indeholder en afhængig lokalitet, men andre gange indeholder den et amt eller en lokalitet. Nu er du til naturlig sprogbehandling (NLP); du skal erkende forskellen mellem by og amt. Og permutationerne bliver flere, efterhånden som du tilføjer flere lande.
Så vi skal definere alle adressekomponenter for alle de lande, vi opererer i.
Adresseformater
Adresseformater består af to dele:en overskrift og dens detaljer. Overskriften er dybest set navnet eller titlen i adresseformatet er kendt af. Eksempler kunne omfatte:
| Adresseformattype |
|---|
| Generisk 3-linje |
| Generisk 5-linjers |
| British Forces Post Office (BFPO) |
| International |
| Postkontoradresse (PAF) |
| USA Adresse |
| Fransk adresse |
Tager vi UK's Full Post Office Address Format (PAF) som eksempel, definerer vi følgende adresseformatkomponenter:
| Format | Komponent | Sekvens | Er obligatorisk? |
|---|---|---|---|
| PAF | Adressat | 1 | N |
| PAF | Organisationens navn | 2 | N |
| PAF | Afdelingsnavn | 3 | N |
| PAF | Postboks | 4 | N |
| PAF | Bygningsnavn | 5 | N |
| PAF | Underbygningsnavn | 6 | N |
| PAF | Bygningsnummer | 7 | N |
| PAF | Gennemvej | 8 | N |
| PAF | Gade | 9 | N |
| PAF | Dobbelt afhængig lokalitet | 10 | N |
| PAF | Afhængig lokalitet | 11 | N |
| PAF | Postby | 12 | Y |
| PAF | Postnummer | 13 | Y |
Vores applikation læser disse metadata og viser adressekomponenterne i den rigtige rækkefølge. Når adresseregistrering er påkrævet, fortæller metadataene os, om adressekomponenten er obligatorisk eller ej.
Oftere anmoder vores applikation om postnummeret fra slutbrugeren og slår de tilsvarende værdier op og udfylder adressekomponenterne automatisk. Nogle applikationer tillader brugeren at redigere adressen; andre [irriterende] gør det ikke!
Det vises ikke i PDM, men hvis din organisation opererer internationalt, kan du definere et mange-til-mange forhold mellem address_format_type og country så det korrekte adresseformat (baseret på brugerens land) præsenteres for slutbrugeren (party ).
Hvornår og kun når contact_point er en postadresse contact_point_type , skal den have en relation til en adresseformattype. Omvendt følger det, at ikke-postadressetyper aldrig har en relation til en address_format_type . Desuden skal formatet forblive fast i hele contact_points levetid , ellers introducerer du muligheden for problemer med dataintegritet. (For at dette ikke skal være tilfældet , målet address_format_components skal være en delmængde af kilden address_format_components ).
Kolonnen contact_value har ingen betydning for en postadresse, fordi værdierne er gemt i enddress_line.line_content . Omvendt, contact_value er obligatorisk for alle andre contact_point_types . Grundlæggende contact_point.contact_value og address_line.line_content udelukker hinanden.
Mange-til-mange forholdet mellem part og kontaktpunkt
Du kan tænke på contact_point (plus address_line ) som indeholder værdierne og party_contact som definerer brugen. Dette tillader et enkelt contact_point at have flere anvendelser . Vores hjemmeadresse kan også være vores faktureringsadresse og leveringsadresse, afhængigt af konteksten.
Hidtil har fortællingen antaget, at en part ejer et bestemt contact_point . Men datamodellen pålægger ikke denne ejerskabsregel! Det giver ingen sådan begrænsning overhovedet. Der er en anden mulighed, der eksisterer med dette design:flere parter for de samme kontaktpunkter.
Du skal overveje konsekvenserne nøje, før du begiver dig ned ad denne rute.
Her er et eksempel. I Storbritannien beskæftiger Awarding Organizations (AO'er) generelt lærere som eksaminatorer. En lærer har to relationer:en til den skole, hvor han eller hun arbejder, og en anden til AO som eksaminator. Skolen vil have en bank med contact_points med forskellige telefonnumre og eventuelt en eller flere postadresser. Disse vil være ting som skolens hovedadresse (postadresse), hoved-e-mail (e-mailadresse), hovedfax (faxnummer) og hovedtelefon (telefonnummer).
Det er fuldt ud muligt, at vores eksaminator kan bruge de samme contact_points som hans eller hendes skole, men han eller hun vil bruge party_contact at definere dem som arbejdsrelaterede. Hvis skolens hovedtelefonnummer ændres, vil lærerens arbejdsnummer automatisk blive opdateret, hvilket er ret pænt.
Hvis du går denne vej, skal du definere på applikationsniveau hvilken eller hvilke parter der har tilladelse til at opdatere contact_points .
Et hurtigt ord om ydeevne
De gule metadatatabeller vil konstant blive brugt af forespørgsler. Derfor vil de sandsynligvis forblive i hukommelsen. På de fleste RDBMS'er kan du fastgøre tabeller til hukommelsen for at sikre dette. I Oracle ville jeg oprette disse som indeksorganiserede tabeller, som er små og fungerer godt. Gør hvad der svarer til dit RDBMS.
Du vil også sikre dig, at party_contact rækker er samplaceret i den samme blok (eller side) ved hjælp af et klynget indeks på party_id . Gør det samme med address_line.contact_point_id . Dette skærer ned på mængden af IO.
Der findes en anden mulighed, hvis du ønsker en party udelukkende at eje et contact_point . Du kan derefter flette contact_point ind i party_contact for at oprette party_contact_point (stadig klynget på party_id ). Dette forenkler modellen og kan hjælpe med ydeevnen.
Ændring af kontakter betyder ikke ændring af databaser
Vi lever i en tid, hvor man kan sige, at forandring er den eneste konstante.
Det betyder ikke, at hver gang noget ændres, skal det påvirke din database. Med lidt omtanke kan vi fremtidssikre vores designs – måske mere, end vi har gjort til dato. Det hjælper os med at reagere hurtigt på den uundgåelige ændring.
Hvis du går i gang med et green-field projekt, vil jeg anbefale at bruge Party Model (som Contact Point er en del af) til organisationer og mennesker. Hvorfor ikke åbne modellen og tilpasse den til dine behov? Du er velkommen til at snuppe en kopi og gøre den til din egen.
Men hvis din database eller dine databaser allerede er fastlagt, kan det skema, jeg har præsenteret her, stadig bruges i XML-form til at definere din nyttelast, når du integrerer data mellem systemer.