I denne tid med hård konkurrence er jobportaler ikke kun platforme til at publicere og finde job. De udnytter avancerede tjenester og funktioner til at holde deres kunder engageret. Lad os dykke ned i nogle avancerede funktioner og bygge en datamodel, der kan håndtere dem.
Jeg forklarede de grundlæggende funktioner, der er nødvendige for et jobportalwebsted i en tidligere artikel. Modellen er vist nedenfor. Vi vil betragte denne model som en base, som vi vil ændre for at opfylde de nye krav. Lad os først overveje, hvad disse krav (eller forbedringer) skal være.
Hvad tilføjer vi til onlinejobportalens datamodel?
Kort fortalt vil vi tilføje fire forbedringer til vores tidligere datamodel:
- Et personligt dashboard for jobsøgende. Dette holder styr på alle deres jobansøgninger og giver opdateringer i realtid om eventuelle statusændringer (dvs. en ansøgning ændres fra at blive modtaget til at blive gennemgået).
- Et profilkontrolpanel. Dette viser, hvem der besøger en jobsøgendes profil, og hvor mange gange deres CV blev downloadet inden for den sidste dag, uge eller måned.
- Betalt servicestyring. Jobportaler tilbyder ofte tjenester som ekspert-cv-forberedelse, social profilstyring, karriererådgivning osv. Vores nye funktionaliteter vil være i stand til at understøtte tilbud mod betaling.
- Administration af forudgående ansøgningsformular. Når ansøgere indsender en jobansøgning, kan de blive bedt om at udfylde et kort spørgeskema relateret til arbejdstider, lokationer og baggrundstjek. Vi vil opbygge måder, så denne formular kan tilpasses af rekrutterere, og så spørgsmål og svar kan fanges af systemet.
Forbedring # 1:Personal Dashboard
Spørgsmål, der skal besvares: Hvad er den aktuelle status for en indsendt ansøgning? Er den nomineret til et interview? Er den overhovedet blevet set endnu?
Vi kan holde styr på jobansøgninger ved at indsætte job_application_status_id kolonnen i job_post_activity bord. Denne kolonne indeholder den aktuelle status for en jobansøgning. Vi skal oprette en anden tabel, job_application_status , for at holde alle mulige ansøgningsstatusser. Nogle statusser kan være 'indsendt', 'under gennemgang', 'arkiveret', 'afvist', 'shortlistet til interview', 'under rekrutteringsproces' og så videre.
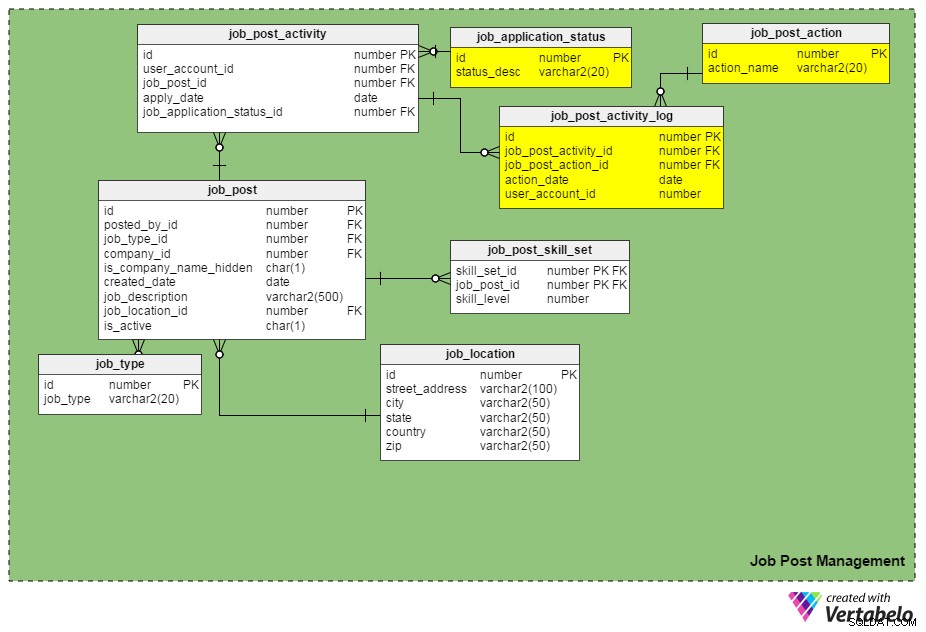
Endnu en ny tabel, job_post_activity_log , gemmer information om alle handlinger udført på jobansøgninger, hvem der udførte handlingen, og hvornår den blev udført. Denne tabel indeholder følgende kolonner:
id– Tabellens primære nøgle.job_post_activity_id– Applikations-id'et, som handlingen udføres på.job_post_action_id– ID'et for den udførte handling. Dette er en fremmednøgle, der linker tiljob_post_actionbord. De typer handlinger, vi kan gemme her, omfatter "indsendt", "set", "interviewet", "skrevet test taget", "tilbud under behandling", "tilbud afsendt", "tilbud accepteret" osv.action_date– Datoen, hvor en handling blev udført.user_account_id– ID'et på den person, der udførte handlingen.
Er "job_post_action" identisk med "job_application_status"? Hvordan er de forskellige?
De virker identiske i starten, men de er faktisk forskellige. Der er gyldige grunde til, at vi har brug for to lignende felter:
- En kandidat bliver interviewet af to eller flere personer hver for sig. I dette tilfælde forbliver jobansøgningsstatus den samme (dvs. 'undergår rekrutteringsproces'), indtil alle samtalerunder er afsluttet. Optegnelser for hver enkelt interviewer indsættes dog i
job_post_activity_logtabel, og de får handlingen 'interviewet'. - En ansøgning kan ses af mere end én rekrutterer i samme virksomhed. Ved at bruge disse to attributter mister du ikke en ansøgers oplysninger.
- At give et tilbud til en udvalgt kandidat er betinget af flere godkendelser (dvs. godkendelse fra økonomiteam, godkendelse fra ansættelsesafdelingsleder og så videre). I dette tilfælde forbliver en jobansøgnings status "tilbud under gennemgang", men databasen kan logge, hvilke godkendelser der er kommet igennem, og hvilke der ikke er, ved hjælp af
job_post_activity_logtabel.
Forbedring # 2:Et profilkontrolpanel
Spørgsmål, der skal besvares: Hvem har fundet min profil for nylig? Hvor mange gange blev det set af rekrutterere inden for den sidste måned, uge eller dag? Har rekrutterere fra topvirksomheder kigget på min profil?
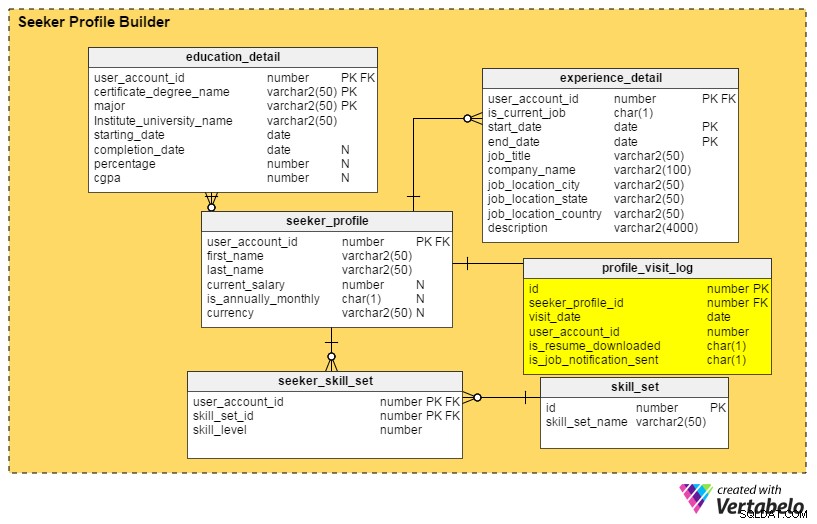
Svarene på alle disse spørgsmål findes i profile_visit_log bord. Denne tabel fanger alle profilbesøgsdata, inklusive hvem der har besøgt en profil, hvornår den blev set og så videre. Kolonnerne i denne tabel er:
id– Tabellens primære nøgle.seeker_profile_id– Hvilken profil blev besøgt.visit_date– Når profilen blev tilgået.user_account_id– Hvem så profilen.is_resume_downloaded– En flagkolonne, der angiver, om det relaterede CV blev downloadet under besøget. Denne kolonne hjælper os med at udlede, hvor mange gange et CV downloades af rekrutterere.is_job_notification_sent– Endnu en flagkolonne, denne angiver, om der er sendt en jobmeddelelse til profilens ejer.
Forbedring # 3:Betalservicestyring
Spørgsmål til svar: Hvordan kan onlineportaler udnytte yderligere tjenester mod betaling?
Udover en platform til at slå op og søge job, tilbyder mange onlineportaler andre tjenester, såsom ekspert-cv-opbygning, karriererådgivning osv. De tilbyder også produkter, der hjælper jobsøgende med at finde deres drømmejob i deres drømmeby. For eksempel tilbyder en af de førende jobsider et produkt, der holder din profil øverst på rekrutteringslister, så du kan få flere samtaletilbud. De fleste af disse produkter eller tjenester er tilgængelige på abonnementsbasis. Når en bruger køber en tjeneste eller et produkt, betaler de over en bestemt tidsperiode (dvs. en måned, tre måneder, et år) for brugen af det pågældende produkt eller tjeneste.
Da jeg så på disse jobportaler, bemærkede jeg, at næsten ingen produkter eller tjenester tilbydes enkeltvis. For det meste er flere produkter og tjenester bundtet sammen til en pakke, og denne pakke tilbydes til enten jobsøgende eller rekruttører.
Under hensyntagen til alle disse punkter kom jeg frem til følgende datamodel til at inkorporere betalte tjenester og produkter på vores eksisterende online jobside:
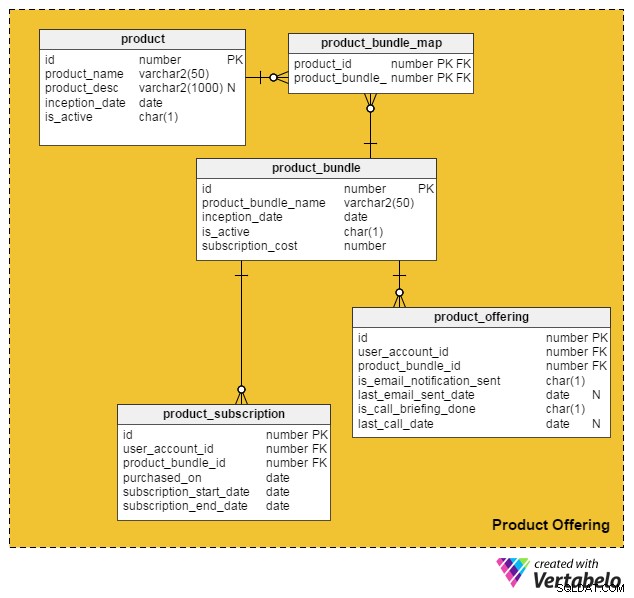
product tabel indeholder detaljer om individuelle produkter. (Vi omtaler både produkter og tjenester som "produkter"). Kolonnerne i denne tabel er:
id– Den primære nøgle i denne tabel, som giver et unikt ID til hvert produkt, der tilbydes på vores portal.product_name– Indeholder produktets navn.product_desc– Gemmer en kort beskrivelse af produktet.inception_date– Datoen, hvor et produkt blev introduceret.is_active– Om et produkt er aktivt eller ej.
Da produkter og tjenester kan slås sammen i en pakke og tilbydes kunder, har jeg oprettet product_bundle tabel til at gemme registreringer af alle sådanne bundter. Attributterne er:
id– Tabellens primære nøgle, som giver et unikt ID for hver produktpakke.product_bundle_name– Gemmer pakkens navn.inception_date– Datoen, hvor pakken blev introduceret.is_active– Angiver, om en bundt er aktiv eller ej.subscription_cost– Gemmer den ønskede pris for pakken.
Kan et enkelt produkt tilbydes kunder?
Ja. I denne datamodel kan et enkelt produkt være sit eget "bundt". Følgende tabeller håndterer dette og nogle andre vigtige funktioner.
product_bundle_map tabel gemmer en liste over alle produkter, der er en del af et bundt. Dens egenskaber er selvforklarende.
Den næste tabel, product_subscription , kommer i spil, når kunder abonnerer på produktpakker. Det registrerer detaljerne om, hvilke kunder der har skrevet til hvilke bundter. Kolonnerne i denne tabel er:
id– Tabellens primære nøgle.user_account_id– Brugeren, der købte pakken.product_bundle_id– Produktpakken købt af brugeren.purchased_on– Købsdatoen.subscription_start_date– Datoen for hvornår abonnementet starter. Bemærk, at produktkøbsdatoen og abonnementets startdato kan variere. Vi har således to forskellige kolonner til disse.subscription_end_date– Hvornår abonnementet slutter.
Slutbordet, product_offering , bruges hovedsageligt til markedsføring. Normalt analyserer jobportaler brugernes seneste aktiviteter (både jobsøgende og rekrutterere) og beslutter derefter, hvilke produkter der vil være gavnlige for hvilke brugere. De bruger derefter e-mails eller telefonopkald til at kontakte kunder med udvalgte tilbud. Kolonnerne for denne tabel er:
id– Tabellens primære nøgle.user_account_id– Brugeren, som jobportalen er målrettet mod.product_bundle_id– Den produktpakke, som portalmarketingerne har matchet til brugeren.is_email_notification_sent– Om der er sendt en e-mail vedrørende produkttilbuddet.last_email_sent_date– Hvornår brugeren sidst modtog en produkt-e-mail fra marketingteamet. Det er almindeligt, at marketingfolk sender flere meddelelser til en bruger og sender andre meddelelser med jævne mellemrum. Denne kolonne gemmer datoen, hvor den sidste meddelelse blev sendt.is_call_briefing_done– Om kunden modtog et telefonopkald, der orienterede dem om et produkt.last_call_date– Datoen for det seneste telefonopkald. Der kan foretages flere opkald (opfølgende opkald) til kunder.
Forbedring # 4:Administration af forudgående ansøgningsformular
Spørgsmål til svar: Hvordan kan en rekrutterer få en tilpasset samtykkeformular udfyldt af alle potentielle jobkandidater?
Mange gange, jobsøgende til at besvare specifikke spørgsmål, som de ansøger om en stilling. Dette omfatter ofte ting som at give samtykke til et kriminelt baggrundstjek. Der er dog forskellige andre typer samtykker, der kan være nødvendige. For eksempel kan et job inden for marketing kræve mange rejser; job i business process outsourcing (BPO) kan kræve, at medarbejdere arbejder på kirkegårdshold (dvs. sent om natten). Disse behandles i forhåndsansøgningsskemaer.
Det er altid bedst at få samtykke, når jobansøgningen indsendes. På denne måde vil kandidater, der ikke er villige til at opfylde disse krav, ikke søge jobbet.
Før jeg hopper til datamodellen, lad mig først fremhæve nogle grundlæggende fakta om samtykkeformularer:
- Et jobopslag kan have mere end én samtykkeerklæring.
- Hver samtykkeformular har forskellige spørgsmål knyttet til forskellige sektioner.
- Et spørgsmål kan indstilles som obligatorisk eller valgfrit, afhængigt af hvordan spørgsmålet er tagget i formularen. Et spørgsmål kan være valgfrit i én form og obligatorisk i en anden.
- Hvert spørgsmål kan besvares som enten (1) ja, (2) nej eller (3) ikke relevant.
- Alle svar vil blive registreret.
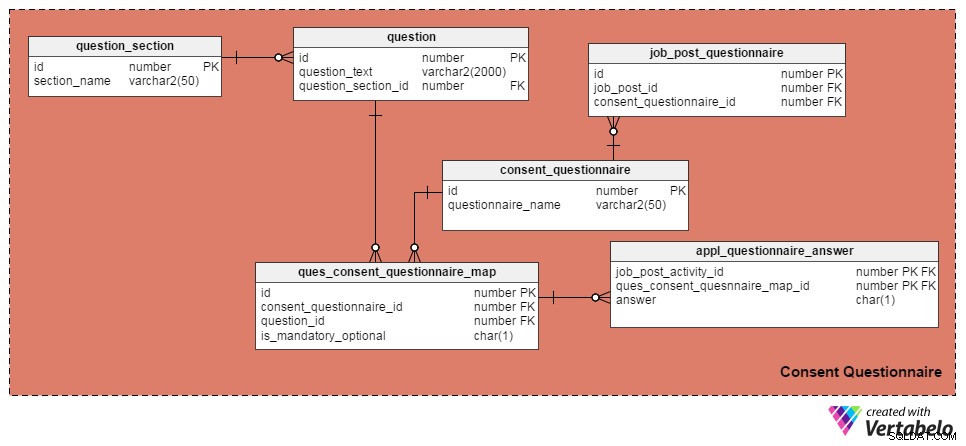
Jeg har brugt de følgende fire tabeller til at administrere spørgsmål og samtykkeformularer. Det første, question tabel, indeholder en liste med spørgsmål. Den har disse attributter:
id– Tabellens primære nøgle, som giver et unikt ID-nummer til hvert spørgsmål.question_text– Gemmer den faktiske spørgsmålstekst.question_section_id– Det afsnit, hvor spørgsmålet vises. (F.eks. "Har du arbejdet med softwareudvikling i mindst fem år?" vil blive vist i afsnittet "Arbejdserfaring".) Dette er en fremmednøglekolonne, der henvises til fraquestion_sectiontabel.
question_section tabel gemmer sektionsoplysninger. Det er en måde at gruppere spørgsmål relateret til det samme emne. Bortset fra id attribut, som er den primære nøgle for tabellen, er den eneste attribut section_name , hvilket er selvforklarende.
consent_questionnaire tabel indeholder navne på samtykkeerklæringer. Dens to egenskaber er også selvforklarende.
ques_consent_questionnaire_map tabel er kernen i dette fagområde. Alle andre tabeller i dette emneområde er direkte eller indirekte forbundet med det. Dens formål er at føre en liste over spørgsmål mærket til samtykkeformularer. Kolonnerne i denne tabel er:
id– Den primære nøgle i denne tabel.consent_questionnaire_id– Samtykkeformularens ID-nummer.question_id– Spørgsmålets ID-nummer.is_mandatory_optional– Angiver, om spørgsmålet er obligatorisk eller valgfrit for en given samtykkeformular. Et spørgsmål kan være en del af flere samtykkeformularer, men det kan være obligatorisk i nogle og valgfrit i andre. Det er den eneste grund til at beholde denne kolonne her i stedet for at have den iquestiontabel.
De næste par tabeller vil vi diskutere tag-samtykkeformularer til individuelle jobopslag og registrere kandidaternes svar. Lad os starte med job_post_questionnaire tabel, som gemmer oplysninger om, hvilke samtykkeerklæringer, der er en del af et jobopslag. Der kan være en eller flere samtykkeformularer tagget med et jobopslag. Kolonnerne i denne tabel er:
id– Tabellens primære nøgle.job_post_id– Angiver, hvilket jobopslag samtykkeformularen er tagget med.consent_questionnaire_id– Samtykkeformularen tagget til et jobopslag.
Dernæst appl_questionnaire_answer tabel logger de individuelle svar på hvert samtykkeformularspørgsmål som udfyldt af ansøgerne. Kolonnerne i denne tabel er:
job_post_activity_id– En fremmednøglekolonne henvist frajob_post_activitybord. Den gemmer oplysninger om den kandidat, der har besvaret spørgsmålet.quest_consent_quesnnaire_map_id– En anden fremmednøglekolonne henvist fraquest_consent_questionnaire_mapbord. Den gemmer, hvilket spørgsmål fra hvilken samtykkeformular, der besvares.answer– Jobansøgerens egentlige svar. Jeg har beholdt den som en CHAR(1) kolonne, fordi alle spørgsmål i vores model kan besvares som 'Ja' (svar ='Y'), 'Nej' (svar ='N') eller 'Ikke relevant' (svar ='X').
Den nye og forbedrede online jobportal-datamodel
Du kan se den færdige datamodel nedenfor.
Hvad vil du tilføje?
Kan du komme i tanke om andre funktioner, du kan tilføje til vores online jobportal? Del venligst dine synspunkter i kommentarfeltet.