I mit tidligere indlæg i denne serie viste jeg, at ikke alle forespørgselsscenarier kan drage fordel af In-Memory OLTP-teknologier. Faktisk kan brug af Hekaton i visse tilfælde faktisk have en skadelig effekt på ydeevnen (klik for at forstørre):

Performancemonitorprofil under udførelse af lagret procedure
Dog kunne jeg have stablet bunken mod Hekaton i det scenarie på to måder:
- Den hukommelsesoptimerede tabeltype, jeg oprettede, havde et bucket count på 256, men jeg sendte op til 2.000 værdier ind til sammenligning. I et nyere blogindlæg fra SQL Server-teamet forklarede de, at overdimensionering af bucket-antallet er bedre end at underdimensionere det – noget, som jeg vidste generelt, men ikke var klar over, også havde væsentlige effekter på tabelvariabler:Keep husk, at for et hash-indeks skal bucket_count være omkring 1-2X antallet af forventede unikke indeksnøgler. Overstørrelse er normalt bedre end understørrelse:Hvis du nogle gange kun indsætter 2 værdier i variablerne, men nogle gange indsætter op til 1000 værdier, er det normalt bedre at angive
BUCKET_COUNT=1000.De diskuterer ikke eksplicit den faktiske årsag til dette, og jeg er sikker på, at der er masser af tekniske detaljer, vi kunne dykke ned i, men den foreskrivende vejledning ser ud til at være for stor.
- Den primære nøgle var et hash-indeks på to kolonner, hvorimod den tabelværdisatte parameter kun forsøgte at matche værdier i en af disse kolonner. Det betød ganske enkelt, at hash-indekset ikke kunne bruges. Tony Rogerson forklarer dette lidt mere detaljeret i et nyligt blogindlæg:Hashen genereres på tværs af alle kolonner indeholdt i indekset, du skal også angive alle kolonnerne i hash-indekset på dit lighedstjek-udtryk, ellers kan indekset ikke bruges .
Jeg viste det ikke før, men læg mærke til, at planen mod den hukommelsesoptimerede tabel med hash-indekset med to kolonner faktisk laver en tabelscanning snarere end den indekssøgning, du kunne forvente mod det ikke-klyngede hash-indeks (da det førende kolonne var
SalesOrderID):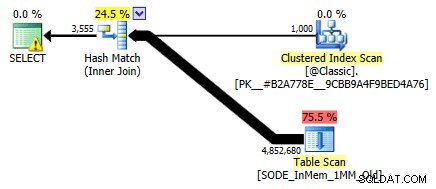
Forespørgselsplan, der involverer en tabel i hukommelsen med en to-kolonne hash-indeksFor at være mere specifik, i et hash-indeks, betyder den forreste kolonne ikke en bakke af bønner i sig selv; hashen matches stadig på tværs af alle kolonner, så det fungerer slet ikke som et traditionelt B-træindeks (med et traditionelt indeks kan et prædikat, der kun involverer den forreste kolonne, stadig være meget nyttigt til at eliminere rækker).
Hvad skal jeg gøre?
Nå, først oprettede jeg et sekundært hash-indeks på kun SalesOrderID kolonne. Et eksempel på et sådant bord med en million spande:
OPRET TABEL [dbo].[SODE_InMem_1MM]( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_QtyLL] [_Orderlin NULL] [_Orderlin] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceRabat] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMÆR NØGLE IKKE-KLUSTERET HASH ( [SalesOrderID], [SalesOrderDetailID] ) MED (BUCKET_COUNT =1048576), /* Jeg har tilføjet denne sekundære indeks:*/ INDEX x IKKE-KLUSTERET HASH ( [SalesOrderID] ) WITH (BUCKET_COUNT =1048576) /* Jeg brugte det samme bucket-antal for at minimere testpermutationer */ ) WITH (MEMORY_OPTIMIZED =ON, DURABILITY>_D SCHATA_DURABILITY_D SCHEMA);Husk at vores tabeltyper er sat op på denne måde:
CREATE TYPE dbo.ClassicTVP AS TABLE( Item INT PRIMARY KEY); CREATE TYPE dbo.InMemoryTVP AS TABLE( Item INT NOT NULL PRIMÆR NØGLE IKKE-KLUNGERET HASH MED (BUCKET_COUNT =256)) MED (MEMORY_OPTIMIZED =ON);Når jeg udfyldte de nye tabeller med data og oprettede en ny lagret procedure til at referere til de nye tabeller, viser den plan, vi får, korrekt en indekssøgning mod enkeltkolonne hash-indekset:
Forbedret plan ved hjælp af enkeltkolonne hash-indeksetMen hvad ville det egentlig betyde for præstationen? Jeg kørte det samme sæt test igen – forespørgsler mod denne tabel med bucket counts på 16K, 131K og 1MM; ved at bruge både klassiske og in-memory TVP'er med 100, 1.000 og 2.000 værdier; og i TVP-tilfældet i hukommelsen ved at bruge både en traditionel lagret procedure og en native kompileret lagret procedure. Sådan gik ydelsen i 10.000 gentagelser pr. kombination:
Ydeevneprofil for 10.000 iterationer mod et enkelt-kolonne hash-indeks, ved hjælp af en 256-spand TVPDu tænker måske, hej, den præstationsprofil ser ikke så fantastisk ud; tværtimod er den meget bedre end min tidligere test i sidste måned. Det viser blot, at bucket count for tabellen kan have en enorm indflydelse på SQL Servers evne til effektivt at bruge hash-indekset. I dette tilfælde er brugen af et bucket count på 16K helt klart ikke optimalt for nogen af disse tilfælde, og det bliver eksponentielt værre, efterhånden som antallet af værdier i TVP stiger.
Husk nu, at bucket count for TVP'en var 256. Så hvad ville der ske, hvis jeg øgede det ifølge Microsofts vejledning? Jeg oprettede en anden bordtype med en mere passende spandstørrelse. Da jeg testede 100, 1.000 og 2.000 værdier, brugte jeg næste potens af 2 til bucket count (2.048):
OPRET TYPE dbo.InMemoryTVP SOM TABEL( Vare INT IKKE NULL PRIMÆR NØGLE IKKE-KLUSTERET HASH MED (BUCKET_COUNT =2048)) MED (MEMORY_OPTIMIZED =ON);Jeg oprettede understøttende procedurer til dette og kørte det samme batteri af test igen. Her er præstationsprofilerne side om side:
Sammenligning af ydeevneprofil med 256- og 2.048-bucket TVP'er em>Ændringen i bucket count for tabeltypen havde ikke den indvirkning, jeg ville have forventet, givet Microsofts erklæring om dimensionering. Det havde egentlig ikke den store positiv effekt overhovedet; faktisk for nogle scenarier var det en lille smule værre. Men overordnet set er præstationsprofilerne, for alle hensigter, de samme.
Hvad der dog havde en enorm effekt, var at skabe det *rigtige* hash-indeks for at understøtte forespørgselsmønsteret. Jeg var taknemmelig for, at jeg var i stand til at demonstrere, at - på trods af mine tidligere tests, der indikerede noget andet - en in-memory-tabel og en in-memory TVP kunne slå den gamle måde at opnå det samme. Lad os bare tage det mest ekstreme tilfælde fra mit tidligere eksempel, hvor tabellen kun havde et to-kolonne hash-indeks:
Ydeevneprofil for 10 iterationer mod et hash-indeks med to kolonnerLinjen længst til højre viser varigheden af kun 10 iterationer af den oprindelige lagrede procedure, der matcher mod et upassende hashindeks – forespørgselstider fra 735 til 1.601 millisekunder. Men nu, med det rigtige hash-indeks på plads, udføres de samme forespørgsler i meget mindre område - fra 0,076 millisekunder til 51,55 millisekunder. Hvis vi udelader det værste tilfælde (16K bucket counts), er uoverensstemmelsen endnu mere udtalt. I alle tilfælde er dette mindst dobbelt så effektivt (i hvert fald med hensyn til varighed) som begge metoder, uden en naivt kompileret lagret procedure, mod den samme hukommelsesoptimerede tabel; og hundredvis af gange bedre end nogen af tilgangene til vores gamle hukommelsesoptimerede tabel med det eneste hash-indeks med to kolonner.
Konklusion
Jeg håber, jeg har demonstreret, at der skal udvises meget forsigtighed, når man implementerer hukommelsesoptimerede tabeller af enhver type, og at det i mange tilfælde måske ikke giver den største ydelsesgevinst at bruge en hukommelsesoptimeret TVP alene. Du vil overveje at bruge native-kompilerede lagrede procedurer for at få mest muligt for pengene, og i den bedste skala vil du virkelig være opmærksom på bucket count for hash-indekserne i dine hukommelsesoptimerede tabeller (men måske ikke så meget opmærksomhed på dine hukommelsesoptimerede tabeltyper).
For yderligere læsning om In-Memory OLTP-teknologi generelt, kan du prøve disse ressourcer:




- SQL Server Team Blog (Tag:Hekaton og Tag:In-Memory OLTP – er kodenavne ikke sjove?)
- Bob Beauchemins blog
- Klaus Aschenbrenners blog