Bryllupper er ofte ledsaget af munterhed og fest med talrige gæster, mad, drikkevarer, musik og dans. Men alt dette kan ikke ske uden den rette forberedelse og koordinering. Lad os se nærmere på, hvordan datamodellering kan hjælpe os med at organisere et bryllup bedre, så alt forløber glat.
Foreløbig baggrund
Selvom vi stort set alle er klar over, hvordan en typisk bryllupsceremonie ser ud, kan det ikke skade kort at overveje nogle aspekter, der potentielt kan påvirke vores datamodel.
Bryllupspartnere
Selvom de fleste traditionelle kulturer vil have ceremonier mellem en mand og kvinde, finder ægteskaber af samme køn også sted i andre samfund. Vores datamodel bør udformes på en sådan måde, at den rummer alle muligheder.
Skala og kompleksitet
Bryllupsceremonier varierer meget i deres størrelse, varighed og kompleksitet. Nogle er små, beskedne lejligheder, men andre er store festligheder. I Kroatien kan du for eksempel holde en simpel bryllupsceremoni, hvor et par bliver gift i rådhuset, udveksler deres ringe og løfter før deres gæster og enten deltage i en middag efter ceremonien eller tage hjem. I andre lande kan bryllupper være ret komplicerede:de kan involvere polterabend, forhandlinger, middage, flere ceremonier og så videre. I nogle tilfælde kan disse ceremonier vare i flere dage og forekomme et par forskellige steder! Igen bør vores datamodel være forberedt til at håndtere disse situationer.
Endeligt resultat og udgifter
I de fleste tilfælde bliver parret gift efter fejringen og modtager en faktura for alle omkostningerne (husleje, mad og drikkevarer, band osv.). De kan beslutte at hyre et bureau til at tage sig af alle disse omkostninger for dem, eller de kan vælge at klare det hele på egen hånd. Uanset hvad, bør vi tage højde for disse situationer.
Datamodellen:Oversigt
Vores datamodel for denne artikel består af fem sektioner:
- Placeringer
- Partnere, produkter og tjenester
- Bryllup
- Deltagere
- Fakturaer
Vi vil grundigt diskutere hvert af disse områder i den rækkefølge, de er anført ovenfor. Mens vi arbejder på at udvikle vores datamodel, påtager vi os rollen som det bureau, der arrangerer brylluppet.
Afsnit 1:Placeringer
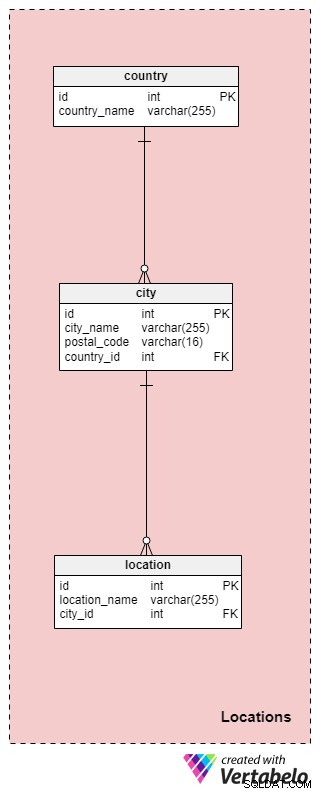
Locations sektionen indeholder universelle tabeller, der kan bruges i mange andre datamodeller. Som vi bemærkede tidligere, kan hele bryllupsceremonien kun finde sted på et enkelt sted, eller det kan potentielt strække sig over flere steder. Lad os diskutere tabellerne i dette afsnit mere detaljeret.
country tabel gemmer oplysninger om det land, hvor brylluppet finder sted. I de fleste tilfælde vil dette land matche placeringen af vores bureau, men det er muligvis ikke tilfældet, hvis vi opererer internationalt. Hvert land i denne tabel er entydigt defineret af dets country_name .
Dernæst skal vi gemme listen over alle byer og/eller landsbyer, hvor brylluppet vil blive organiseret. Disse oplysninger vil blive gemt i city bord. For hver by gemmer vi dens navn og postnummer samt det land, den er beliggende i.
Den sidste tabel i dette emneområde er location . Steder er mere specifikke, såsom rådhuse, kirker, parker og så videre. For hver lokation gemmer vi dens navn og en reference til id'et for den by, den er placeret i. Kombinationen af disse to attributter danner den unikke nøgle til denne tabel.
For lokationer, bemærk, at vi har taget en konservativ tilgang her for at undgå at dække de usædvanlige tilfælde, hvor ceremonien finder sted i f.eks. et tog eller et fly (i hvilket tilfælde "placeringen" kan involvere flere byer). Hvis vi gerne vil dække disse sager, skal vi lave nogle ændringer i vores model.
Afsnit 2:Partnere, produkter og tjenester

Før vi går videre til den centrale del af vores datamodel, skal vi gemme listen over alle partnere, vi arbejder med, samt de produkter og tjenester, de tilbyder. For at opnå dette bruger vi fem tabeller.
Først og fremmest er listen over alle partnere, vi arbejder med, gemt i partner ordbog. For hver partner gemmer vi deres unikke partner_code og partner_name .
Selvfølgelig vil vores partnere levere bryllupsrelaterede tjenester, som kunne omfatte catering, organisering af bands, opsætning af lyd- og videoudstyr, yde huslejestøtte og meget mere. I det væsentlige kan alt, hvad du kan tænke på, potentielt være relateret til et bryllup på en eller anden måde. Vi gemmer denne liste over tjenester i service ordbog. For hver tjeneste gemmer vi:
service_code– en værdi, vi vil bruge internt til unikt at betegne en bestemt tjeneste.service_name– tjenestens navn. Bemærk, at forskellige tjenester kan dele det samme navn. Dette ville ske, hvis to af vores partnere tilfældigvis tilbyder den samme service, hvilket er ret sandsynligt. Det ville endda være ønskeligt, hvis de bruger det samme navn for samme tjenestetype, fordi det ville gøre det meget nemmere at sammenligne priser for de samme tjenester.description– en valgfri tekstbeskrivelse af tjenesten.picture– et link til det sted, hvor det tilknyttede servicebillede er gemt.price– den aktuelle pris for denne service. Den kan indeholde en værdi på NULL, hvis prisen ikke kan bestemmes uden først at evaluere forskellige faktorer, såsom hvor mange mennesker, der planlægger at deltage i ceremonien.
provides_service tabel relaterer partnere til listen over tjenester, de leverer. For hver unik kombination af partner_id og service_id , gemmer vi en detaljeret tekstbeskrivelse af arten af den service, der leveres af partneren, og om tjenesten er tilgængelig i øjeblikket.
Vi har også brug for tabeller til lagring af information om produkter og deres relationer til partnere. product tabellen følger samme logik som service tabel, bortset fra, som navnet antyder, at den er specifik for produkter. I denne tabel gemmer vi alle mulige produkter, der er afgørende for de fleste bryllupsceremonier, såsom ringe, outfits, dekorationer, blomster, møbler og mere.
Den sidste tabel i dette afsnit er provides_product bord. Det fungerer ligesom provides_service tabel, bortset fra at den er specifik for produkter i modsætning til tjenester. Det specificerer, hvilke af vores partnere, der tilbyder det pågældende produkt.
Afsnit 3:Bryllupper
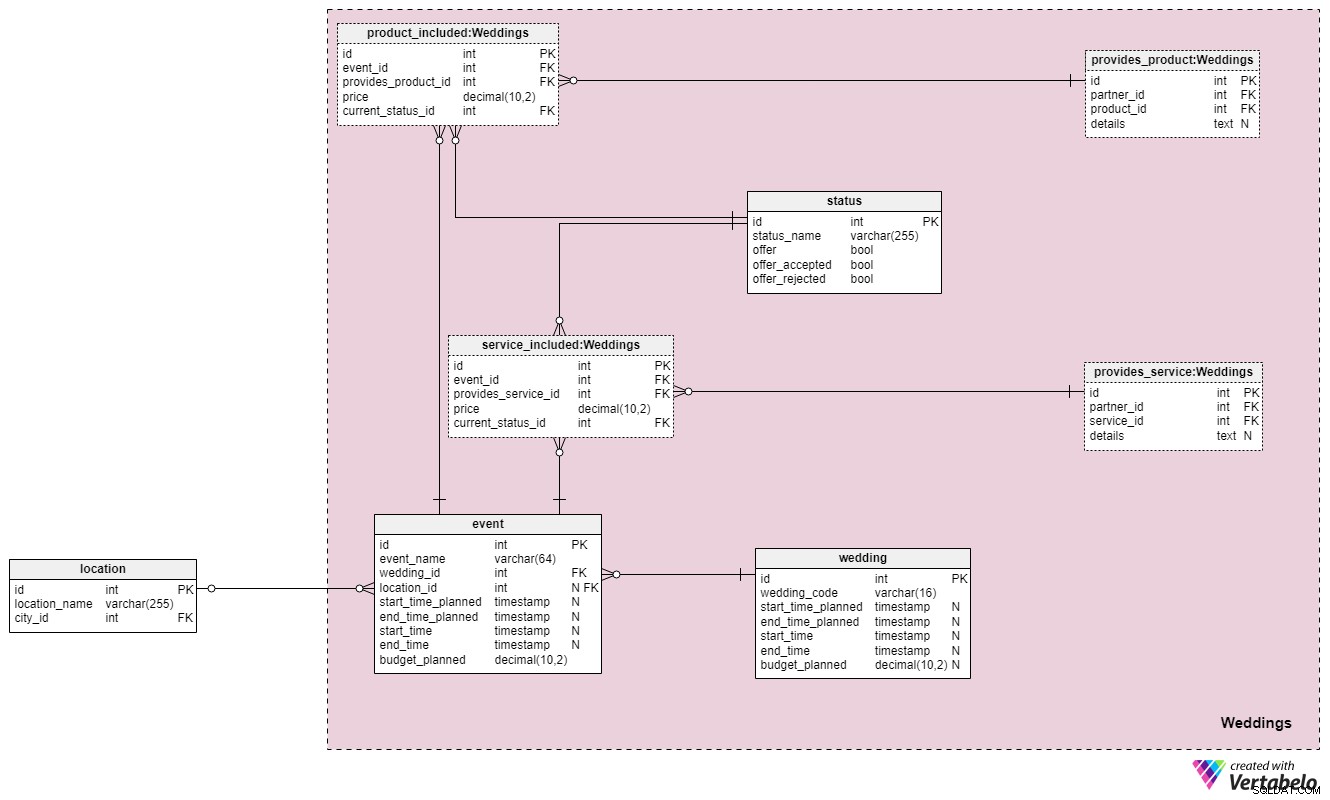
Vi er endelig nået frem til hjertet af vores datamodel – Weddings afsnit. Den indeholder fem nye tabeller, der refererer til andre sektioners tabeller. Bemærk, at dette afsnits egne tabeller også vil blive refereret i kommende dele af vores model.
I wedding tabel, gemmer vi den komplette liste over alle bryllupper, vi er/var involveret i at organisere. Hvert bryllup vil blive tildelt sin egen unikke wedding_code . Vi gemmer også de planlagte start- og sluttider for hele ceremonien, og vi opdaterer de reelle start- og sluttider, når disse oplysninger bliver tilgængelige. Derudover gemmer vi budget_planned værdi, så vi i det mindste har et skøn over, hvor meget det hele vil koste. Alle andre detaljer relateret til brylluppet er gemt i andre områder af datamodellen, så det er alt, hvad vi virkelig har brug for lige nu.
Ideen her er at behandle hvert bryllup som en række begivenheder. Begivenheder vil igen være relateret til tilbud på ønskede produkter/ydelser, afviste og accepterede tilbud og andre relevante detaljer. For at give dig en bedre idé om, hvordan det hele fungerer, kunne vi opdele hele brylluppet i følgende begivenheder:planlægningsfase, polterabend, ceremoni og efterfest/middag. Det er selvfølgelig blot nogle af de mest almindelige bryllupsbegivenheder. Alle bryllupsarrangementer er gemt i begivenhedstabellen. En event vil have et unikt id.
Hver begivenhed er forbundet med et enkelt bryllup, og det vil enten være relateret til ét sted eller ingen. Sidstnævnte tilfælde opstår, hvis begivenheden er mere konceptuel , såsom planlægningsfasen (da der ikke er et enkelt sted, hvor det skal foregå). Ligesom med selve bryllupsceremonien vil et arrangement have planlagte og rigtige start-/sluttidspunkter samt et planlagt budget. Bemærk, at vi har holdt tingene enkle her med hensyn til placeringer. Hvis begivenheder involverer flere lokationer, bliver vi nødt til at justere vores datamodel.
Fortsat vil vi gerne gemme alle tjenester og produkter, der er relateret til en begivenhed. For at gøre det bruger vi tre tabeller:status , product_included , og service_included .
status table er en ordbog, der holder styr på alle statusser relateret til produkter og tjenester for en bestemt begivenhed. Det inkluderer flagvariabler, der angiver, om et produkt/en tjeneste er blevet tilbudt, accepteret eller afvist. For hver post i denne tabel gemmer vi et unikt status_name .
De resterende to tabeller i dette afsnit med titlen product_included og service_included , ligner hinanden strukturelt og konceptuelt. For hver begivenhed gemmer vi listen over produkter og tjenester, der blev tilbudt, og ændrer deres status, hvis de bliver accepteret eller afvist. For hver post i disse to tabeller gemmer vi følgende almindelige attributter:
event_id– en henvisning til den relaterede begivenhed.provides_product_id/provides_service_id– referencer til tabellerne med produkter/tjenester, som vores partnere tilbyder.price– foreslået pris for produktet/ydelsen. Denne pris kan afvige fra den standardpris, vi har registreret, hvis vi foreslår et særligt tilbud.current_status_id– en reference tilstatusordbog, der angiver, om denne post blev tilbudt, accepteret eller afvist.
Afsnit 4:Deltagere
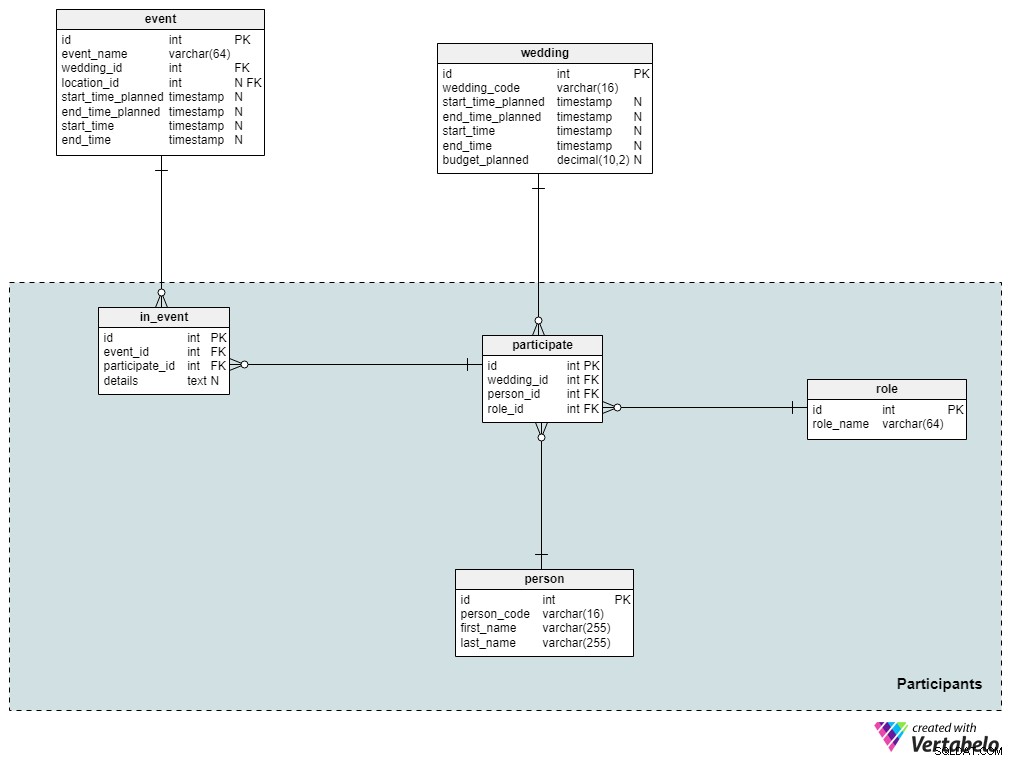
Hvis du arrangerer et stort bryllup, er chancerne for, at du kender de fleste af de gæster, der planlægger at deltage. Selvfølgelig vil de gæster, du inviterer – hvad enten det er dine venner eller slægtninge – sandsynligvis bringe andre mennesker, du ikke kender personligt, såsom deres venner eller kolleger. I dette afsnit gemmer vi den komplette liste over gæster, der er blevet inviteret til brylluppet, samt deres roller.
person tabel indeholder en liste over alle personer, der er med i brylluppet. For hver enkelt person gemmer vi deres unikke person_code og for- og efternavne. Vi kan selvfølgelig tilføje flere detaljer, hvis vi ønsker det.
Dernæst vil vi definere alle mulige roller, som man kunne påtage sig under et bryllup. Disse roller inkluderer "gæst", "bedste mand", "groomsman", "brudepige", "brud", "groom" og så videre. For hver rolle gemmer vi kun det unikke role_name i denne tabel. En person kan kun påtage sig én rolle til et bestemt bryllup.
Dernæst vil vi relatere bryllupper til deres deltagere. Bemærk, at participate tabel indeholder kun referencer til tabellerne wedding , person og role . Kombinationen af wedding_id og person_id fungerer som den alternative nøgle til denne tabel.
Brylluppet vil bestå af flere arrangementer, men ikke alle deltagere vil være involveret i disse. Derfor skal vi opbevare disse oplysninger separat. I in_event tabel, gemmer vi unikke par af fremmednøgler, der refererer til tabellerne event og participate . Alle yderligere oplysninger vil blive gemt i details tekst tilskrevet.
Afsnit 5:Fakturaer
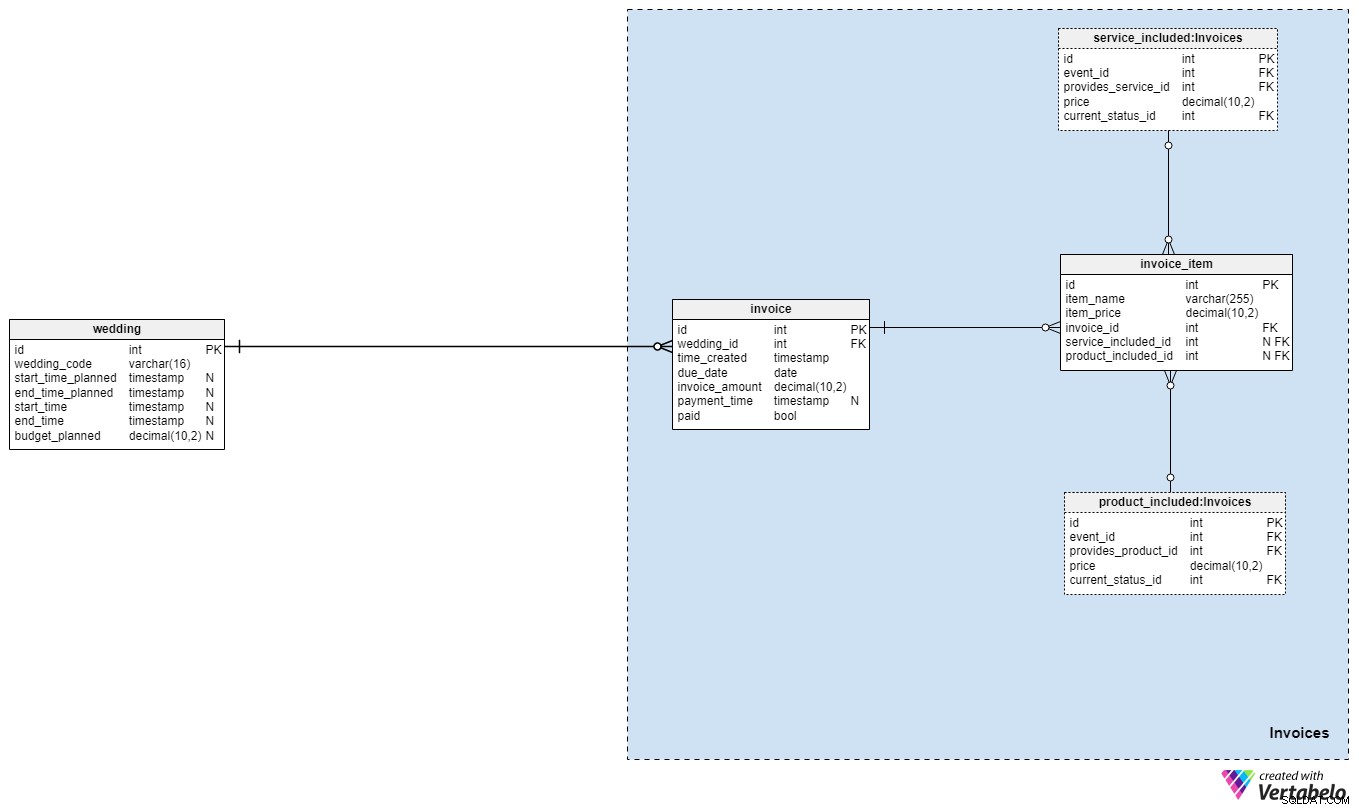
Vi er næsten færdige! Det sidste afsnit af vores datamodel giver os mulighed for at spore udgifter i forbindelse med brylluppet. Spændende, ikke?
Vi genererer normalt én invoice pr. bryllup, men vi kunne også generere mere, hvis vi havde brug for det. Forhåbentlig vil det samlede beløb, vi fakturerer parret, nøje matche vores planlagte budget, men det er måske ikke altid tilfældet. For hver faktura gemmer vi følgende oplysninger:
wedding_id– en henvisning til det bryllup, som fakturaen er udstedt for.time_created– tidsstemplet for, hvornår fakturaen blev genereret.due_date– den dato, hvor fakturaen skal betales.invoice_amount– det samlede beløb, der skal betales.payment_time– tidsstemplet for, hvornår betalingen faktisk blev udstedt. Selvfølgelig vil denne attribut indeholde værdien NULL, indtil betalingen er foretaget.paid– et flag, der angiver, om fakturaen er betalt. Denne attribut indstilles til "True" så snartpayment_timeer opdateret.
Den sidste tabel i vores model vedrører selve de fakturerede varer. Vi gemmer disse i invoice_item bord. For hver post gemmer vi følgende detaljer:
item_name– vores valgte navn for den specifikke vare.item_price– den pris, der er relateret til den specifikke vare.invoice_id– id'et for den relaterede faktura.service_included_id– id'et for den service, fakturavaren er relateret til. Denne attribut kan indstilles til NULL, hvis den pågældende vare ikke faktisk er relateret til nogen tjeneste, eller hvis det blot er et ekstra gebyr, vi har påført fakturaen.product_included_id– id'et på det produkt, fakturavaren er relateret til. Denne attribut kan indstilles til NULL, hvis den pågældende vare ikke faktisk er relateret til noget produkt, eller hvis det blot er et ekstra gebyr, vi har påført fakturaen.
Oversigt
Det opsummerer det stort set for denne datamodel! Endnu en gang ser vi, hvor nyttig datamodellering er til at organisere en virksomheds information.
Som vi bemærkede, er der mange ting, vi har udeladt fra vores datamodel for enkelhedens skyld. For eksempel bør vores model ideelt set spore tilbudshistorier, økonomiske detaljer og mere.
Fortæl os nedenfor, hvis du har forslag. Vi vil meget gerne høre dine tanker!