På PASS Summit for et par uger siden udgav Microsoft CTP2.1 af SQL Server 2019, og en af de store funktionsforbedringer, der er inkluderet i CTP'en, er Scalar UDF Inlining. Før denne udgivelse ønskede jeg at lege med ydeevneforskellen mellem inlining af skalar UDF'er og RBAR (row-by-agonizing-row) eksekvering af skalar UDF'er i tidligere versioner af SQL Server, og jeg stødte på en syntaksindstilling for OPRET FUNKTION sætning i SQL Server Books Online, som jeg aldrig havde set før.
DDL for CREATE FUNCTION understøtter en WITH-klausul for funktionsmuligheder, og mens jeg læste Books Online bemærkede jeg, at syntaksen inkluderede følgende:
-- Transact-SQL funktionsklausuler::= { [ ENKRYPTION ] | [ SKEMABINDING ] | [ RETURNERER NULL PÅ NULL INPUT | KALDET PÅ NULL INPUT ] | [ EXECUTE_AS_Clause ] }
Jeg var virkelig nysgerrig efter RETURNS NULL ON NULL INPUT funktionsindstilling, så jeg besluttede at lave nogle test. Jeg var meget overrasket over at finde ud af, at det faktisk er en form for skalær UDF-optimering, der har været i produktet siden mindst SQL Server 2008 R2.
Det viser sig, at hvis du ved, at en skalar UDF altid vil returnere et NULL-resultat, når der leveres et NULL-input, så skal UDF ALTID oprettes med RETURNS NULL ON NULL INPUT mulighed, for så kører SQL Server slet ikke funktionsdefinitionen for nogen rækker, hvor inputtet er NULL – kortslutter det i kraft og undgår spildte udførelse af funktionslegemet.
For at vise dig denne adfærd vil jeg bruge en SQL Server 2017-instans med den seneste kumulative opdatering anvendt på den og AdventureWorks2017 database fra GitHub (du kan downloade den herfra), som leveres med en dbo.ufnLeadingZeros funktion, der blot tilføjer indledende nuller til inputværdien og returnerer en streng på otte tegn, som inkluderer de indledende nuller. Jeg vil oprette en ny version af den funktion, der inkluderer RETURNS NULL ON NULL INPUT mulighed, så jeg kan sammenligne den med den oprindelige funktion for udførelsesydelse.
USE [AdventureWorks2017];GO CREATE FUNCTION [dbo].[ufnLeadingZeros_new]( @Value int ) RETURERER varchar(8) MED SCHEMABINDING, RETURERER NULL PÅ NULL INPUT AS BEGIN Retur DECLARE); SET @ReturnValue =CONVERT(varchar(8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue; RETURN (@ReturnValue); ENDE; GÅ Med det formål at teste forskellene i eksekveringsydeevnen i databasemotoren for de to funktioner, besluttede jeg at oprette en udvidet begivenhedssession på serveren for at spore sqlserver.module_end hændelse, som udløses i slutningen af hver udførelse af den skalære UDF for hver række. Dette lader mig demonstrere række-for-række-bearbejdningssemantikken og lader mig også spore, hvor mange gange funktionen faktisk blev påkaldt under testen. Jeg besluttede også at samle sql_batch_completed og sql_statement_completed begivenheder og filtrer alt efter session_id for at sikre mig, at jeg kun fangede information relateret til den session, jeg rent faktisk kørte testene på (hvis du vil replikere disse resultater, skal du ændre 74'eren alle steder i koden nedenfor til det sessions-id din test kode vil køre ind). Begivenhedssessionen bruger TRACK_CAUSALITY så det er nemt at tælle, hvor mange afviklinger af funktionen der er sket gennem activity_id.seq_no værdi for begivenhederne (som øges med én for hver begivenhed, der opfylder session_id filter).
OPRET EVENT SESSION [Session72] PÅ SERVER ADD EVENT sqlserver.module_end( WHERE ([pakke0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver_comple (WHERE EVENT sqlserver.sql [pakke0].[equal_uint64]([sqlserver].[session_id],(74)))), TILFØJ EVENT sqlserver.sql_batch_starting( HVOR ([pakke0].[equal_uint64]([sqlserver].[session_id],(74) ))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([pakke0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( pakke WHERE ([equal_0] ([sqlserver].[session_id],(74)))) MED (TRACK_CAUSALITY=ON) GO
Da jeg startede begivenhedssessionen og åbnede Live Data Viewer i Management Studio, kørte jeg to forespørgsler; en, der bruger den originale version af funktionen til at indsætte nuller til CurrencyRateID kolonnen i Sales.SalesOrderHeader tabel, og den nye funktion til at producere det identiske output, men ved at bruge RETURNS NULL ON NULL INPUT mulighed, og jeg fangede oplysningerne om den faktiske udførelsesplan til sammenligning.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FRA Sales.SalesOrderHeader; GÅ
Gennemgang af data for udvidede begivenheder viste et par interessante ting. For det første kørte den oprindelige funktion 31.465 gange (fra antallet af modul_end hændelser) og den samlede CPU-tid for sql_statement_completed hændelsen var 204ms med en varighed på 482ms.
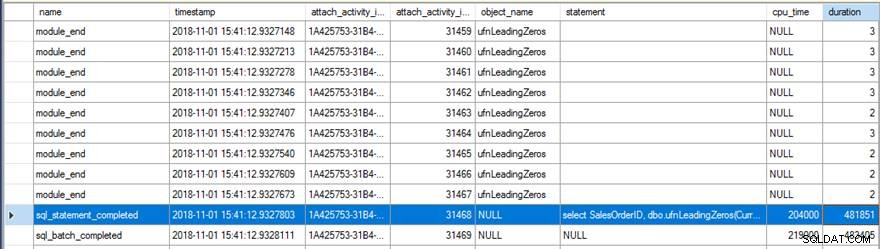
Den nye version med RETURNS NULL ON NULL INPUT den angivne indstilling kørte kun 13.976 gange (igen, fra antallet af module_end hændelser) og CPU-tiden for sql_statement_completed hændelsen var 78 ms med en varighed på 359 ms.

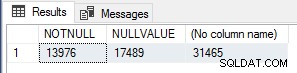
Jeg fandt dette interessant, så for at bekræfte antallet af eksekveringer kørte jeg følgende forespørgsel for at tælle IKKE NULL værdirækker, NULL-værdirækker og samlede rækker i Sales.SalesOrderHeader tabel.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT.
Disse tal svarer nøjagtigt til antallet af module_end hændelser for hver af testene, så dette er bestemt en meget simpel ydelsesoptimering for skalære UDF'er, der bør bruges, hvis du ved, at resultatet af funktionen vil være NULL, hvis inputværdierne er NULL, for at kortslutte/omgå funktionsudførelse udelukkende for disse rækker.
QueryTimeStats-oplysningerne i de faktiske udførelsesplaner afspejlede også præstationsgevinsten:
Dette er en ganske betydelig reduktion i CPU-tid alene, hvilket kan være et betydeligt smertepunkt for nogle systemer.
Brugen af skalære UDF'er er et velkendt design-anti-mønster for ydeevne, og der er en række forskellige metoder til at omskrive koden for at undgå deres brug og ydeevne. Men hvis de allerede er på plads og ikke nemt kan ændres eller fjernes, skal du blot genskabe UDF'en med RETURNS NULL ON NULL INPUT mulighed kunne være en meget enkel måde at forbedre ydeevnen på, hvis der er mange NULL-input på tværs af datasættet, hvor UDF'en bruges.