Over hele kloden er jobportalsiden et velkendt træk ved internetlandskabet. Store spillere som Indeed og Monster har forvandlet jobjagt og rekruttering til en veritabel onlineindustri. Lad os dykke ned i de elementære funktioner, der udnyttes af jobportaler og bygge en datamodel, der kan understøtte dem.
Folk elsker at spare tid ved at bruge teknologiske innovationer; online jobportalen er en anden version af at arbejde smartere, ikke hårdere. Både jobsøgende og virksomheder indser værdien i at tage deres søgning online:de får en bedre rækkevidde ved højere hastigheder og lavere omkostninger.
Jobportalbranchen er ret stabiliseret nu, i hvert fald med hensyn til trafikmængder. Jobjægere bruger disse portaler til at finde stillinger i mange brancher og bevæger sig ud over IT til sektorer som teknik, salg, fremstilling og finansielle tjenesteydelser. De får dog hård konkurrence fra sociale medier og professionelle netværkssider som LinkedIn. Men der er stadig muligheder for at udforske, såsom at udvide deres penetration til landdistrikter og mindre byer.
Så som vi sagde, vil vi udforske dette emne fra et databasedesignperspektiv. Lad os starte med at opregne de grundlæggende forventninger til en jobportal.
Hvad forventer folk af en online jobportal?
Både arbejdsgivere og jobsøgende forventer følgende funktionaliteter fra en online jobside:
- Folk kan registrere sig som jobsøgende, opbygge deres profiler og søge job, der matcher deres kompetencer.
- Brugere kan uploade deres eksisterende CV'er. Hvis de ikke har en, bør de kunne udfylde en formular og få lavet et CV til dem.
- Folk kan ansøge direkte til opslåede job.
- Virksomheder kan registrere sig, opslå job og søge jobsøgende profiler.
- Flere repræsentanter fra en virksomhed bør være i stand til at registrere og udsende job.
- Virksomhedsrepræsentanter kan se en liste over jobansøgere og kan kontakte dem, tage initiativ til en samtale eller udføre en anden handling relateret til deres stilling.
- Registrerede brugere skal kunne søge efter job og filtrere resultaterne baseret på placering, nødvendige færdigheder, løn, erfaringsniveau osv.
Opbygning af datamodellen
Efter at have overvejet ovenstående krav, kom jeg frem til tre brede funktionelle kategorier:
- Administration af brugere – Hvordan portalen håndterer brugere, det vil sige jobsøgende, HR-personale og uafhængige eller rådgivende rekrutterere. (Med henblik på denne model behandles individuelle HR-repræsentanter og uafhængige eller rådgivende rekrutterere som virksomheder, i det mindste med hensyn til hvordan de bruger portalen.)
- Bygningsprofiler – Hvordan portalen giver jobsøgende og organisationer mulighed for at oprette profiler og CV'er.
- Opslå og slå job op – Hvordan portalen letter processen med at opslå, søge og søge job.
Lad os se på hvert af disse områder separat.
1. Håndtering af brugere
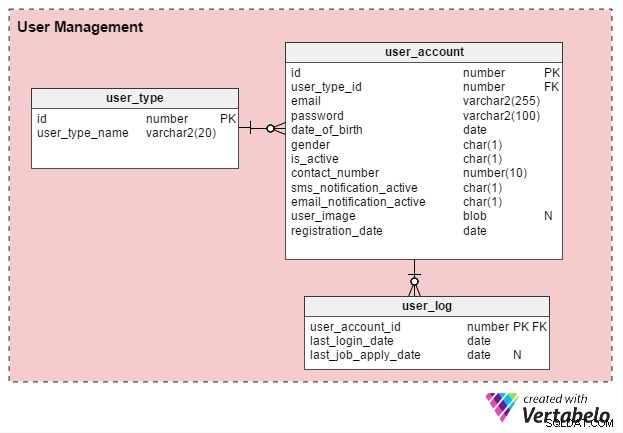
Der er primært to typer online jobportalbrugere:individuelle jobsøgende og HR-rekrutører (eller uafhængige rekrutteringskonsulenter). Lad os oprette en tabel med navnet user_type at gemme disse optegnelser. Til at starte med vil det have to poster – en for jobsøgende og en anden for rekrutteringsvirksomheder. (Vi kan altid oprette yderligere registreringstyper efter behov.)
Brugere skal registrere sig, før de kan bruge portalen. user_account tabel gemmer deres grundlæggende kontooplysninger. Jeg overvejede tidligere at navngive denne tabel "bruger", men da bruger er et systemdefineret nøgleord i næsten alle databaser, foretrækker jeg at holde mig til "bruger_konto".
user_account tabellen har følgende kolonner:
- id – Dette er både tabellens primære nøgle og en unik identifikator for hver bruger. Dette ID vil blive henvist til af andre tabeller i datamodellen.
- user_type_id – Dette betyder, om brugeren er jobsøgende eller rekrutterer.
- e-mail – Denne kolonne indeholder brugerens e-mailadresse. Det fungerer som et andet bruger-id for portalen.
- adgangskode – Dette gemmer en krypteret kontoadgangskode (oprettet af brugere under registrering).
- fødselsdato og køn – Som deres navne antyder, indeholder disse kolonner brugernes fødselsdato og køn.
- er_aktiv – Til at begynde med ville denne kolonne være "Y", men brugere kan indstille deres profil til inaktiv eller "N". Denne kolonne gemmer deres valg.
- kontakt_nummer – Dette er telefonnummeret (normalt mobilt), der oplyses under registreringen. Brugere kan modtage SMS (tekst) notifikationer på dette nummer. Det kan være det samme antal (eller ej) som den jobsøgende anfører i deres profil eller CV.
- sms_notification_active og email_notification_active – Disse kolonner gemmer brugernes præferencer vedrørende modtagelse af meddelelser via tekst og/eller e-mail.
- bruger_billede – Dette er en BLOB-type attribut, der gemmer hver brugers profilbillede. Da denne portal kun tillader ét profilbillede pr. bruger, giver det mening at gemme det her.
- registrationsdato – Denne kolonne registrerer, hvornår brugeren er registreret på portalen.
Vi opretter endnu en tabel, user_log , der gemmer en registrering af brugernes sidste login-dato og deres sidste jobansøgningsdato. Der er en masse funktioner, som kan bygges ud fra denne viden. For eksempel kan vi bruge disse oplysninger til at besvare spørgsmålet Søger bruger X aktivt job ? Hvis det er tilfældet, kan de tilbydes et produkt til at lave et effektivt CV. Brugere, der ikke aktivt søger job, ville ikke modtage et sådant tilbud.
2. Opbygning af profiler
Vi kan yderligere opdele dette afsnit i to områder:virksomheds- eller organisationsprofiler og jobsøgende profiler.
Virksomhedsprofiler
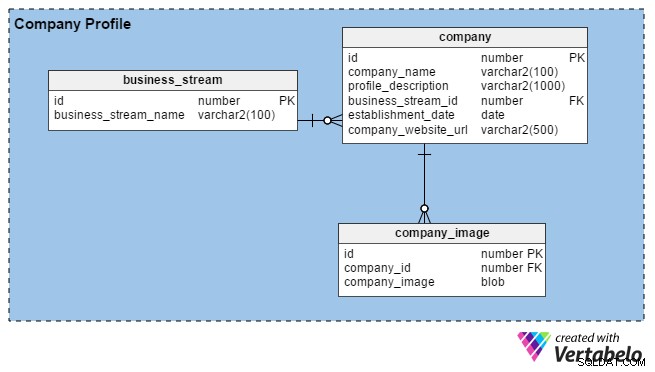
Normalt bygger HR-teams virksomhedsprofiler ved at indtaste detaljer om deres organisation og billeder af deres kontorer, bygninger osv. Deres hovedformål er at tiltrække gode talenter. Når rekrutterere registrerer sig på portalen, kan de også opbygge profiler af deres virksomheder (eller deres personlige brand, hvis de er uafhængige) ved at give nogle grundlæggende detaljer, såsom hvor længe de har været i virksomheden, deres placering og deres primære forretningsstrøm ( f.eks. fremstilling, it-tjenester, finans osv.).
Portalen giver HR- og konsulentkonsulenter mulighed for at uploade så mange billeder, som de vil (i modsætning til jobsøgende, som kun kan uploade et). Derfor har vi oprettet company_image tabel for at gemme flere billeder for hver rekrutteringskonto. virksomheds-id kolonne i denne tabel er en fremmednøgle, der refererer til den unikke identifikator, der bruges i company tabel.
I company tabel, har vi følgende kolonner:
- id – Den primære nøgle i denne tabel bruges også til entydigt at identificere virksomheder.
- virksomhedsnavn – Som kolonnenavnet antyder, har dette det juridiske navn på en virksomhed.
- profilbeskrivelse – Dette indeholder en kort beskrivelse af hver virksomhed.
- business_stream_id – Denne kolonne viser, hvilken forretningsstrøm en virksomhed tilhører. For eksempel kan et olie- og gasudforskningsselskab ansætte it-ingeniører , men deres hovedforretning er fortsat "Olie og gas".
- establishment_date – Denne kolonne fortæller dig, hvor gammel en virksomhed er.
- company_website_url – Dette er en obligatorisk (ikke-nullbar) kolonne. Den indeholder en vejledning til virksomhedens officielle hjemmeside, så jobsøgende kan finde ud af mere information.
Til sidst, business_stream tabel har kun to attributter, et id, der er den primære nøgle for denne tabel, og en beskrivelse af virksomhedens primære forretningsstrøm (business_stream_name ).
Jobsøgende profiler
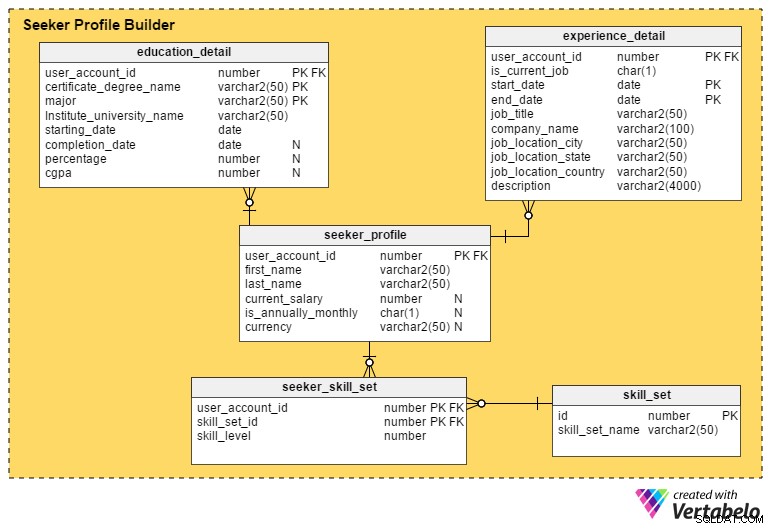
Dette er den mest kritiske del af en jobportal. Medmindre en portal fanger så mange detaljer som muligt fra jobsøgende, er det vanskeligt for rekrutterere at shortliste profilerne eller kandidaterne.
seeker_profile tabel indeholder yderligere detaljer, der ikke blev registreret under registreringsprocessen. Den indeholder disse felter:
- user_account_id – Denne kolonne er henvist fra
user_accounttabel, og den fungerer som den primære nøgle for denne tabel. Det sikrer, at der maksimalt vil være én profil pr. jobsøger. - fornavn og efternavn – Som navnene antyder, indeholder disse kolonner den jobsøgendes for- og efternavn.
- aktuel_løn – Denne attribut indeholder den jobsøgendes aktuelle løn. Den er nullbar, fordi folk måske ikke ønsker at afsløre den.
- er_årligt_månedligt – Dette definerer, om deres løn er pr. år eller pr. måned.
- valuta – Dette gemmer lønnens valuta.
education_detail tabel gemmer hver jobsøgendes uddannelseshistorie, som leveret af dem. Den har en sammensat primær nøgle, der består af user_account_id , certifikat_gradsnavn og major kolonner. Dette sikrer, at brugere kun indtaster én rekord for hver grad eller certifikat. Tabellen indeholder disse attributter:
- user_account_id – Denne kolonne er henvist fra
user_accounttabel og fungerer som den primære nøgle for denne tabel. - certifikat_gradsnavn – Dette er certifikatet eller gradstypen; for eksempel. gymnasium, videregående uddannelse, kandidat, postgraduate eller professionscertifikat.
- major – Denne spalte rummer hovedstudiet for certifikatet eller graden – f.eks. en bachelorgrad med hovedfag i datalogi.
- institutt_universitetsnavn – Dette er instituttet, skolen eller universitetet, der tildelte graden eller certifikatet.
- startdato – Denne attribut gemmer datoen, hvor brugeren blev optaget i et uddannelsesprogram.
- afslutningsdato – Dette er den dato, hvor graden eller certifikatet blev tildelt. Denne egenskab er dog nullbar; folk er muligvis stadig ved at gennemføre deres program, mens de søger job, eller de kan være faldet helt ud af programmet.
- procent og cgpa – Disse kolonner gemmer karakterprocenten eller CGPA (kumulativt karaktergennemsnit) opnået af brugere i deres grad eller certifikatkursus.
experience_detail tabel fører optegnelser over brugernes tidligere og nuværende faglige erfaring. Den indeholder følgende vigtige kolonner:
- user_account_id – Denne kolonne er henvist fra
user_accounttabel og er den primære nøgle til denne tabel. - er_aktuelt_job – Dette er en indikatorkolonne, der angiver brugerens aktuelle job. Denne kolonne spiller også en vigtig rolle i at udlede brugernes nuværende placering og hvor længe de har beholdt deres nuværende position.
- startdato – Dette gemmer, hvornår en bruger starter et job.
- slutdato – Dette gemmer, hvornår en bruger afslutter et job.
- job_title – Dette indeholder oplysninger om brugerens jobrolle.
- virksomhedsnavn – Disse attributter har det relevante firmanavn, der er knyttet til et job.
- job_location_city – Dette betyder den by, hvor jobbet var placeret.
- job_location_state – Dette angiver den tilstand, hvor jobbet var placeret.
- job_location_country – Dette angiver det land, hvor jobbet var placeret.
- beskrivelse – Denne kolonne gemmer detaljer om jobroller og ansvar, udfordringer og præstationer.
Jobsøgende kan besidde flere kompetencer. For at holde styr på alle disse færdighedssæt opretter vi tabellen seeker_skill_set . Kolonnerne er:
- user_account_id – Denne kolonne er henvist fra
user_accounttabel og er den primære nøgle til denne tabel. - skill_set_id – Dette ID angiver, hvilke færdigheder brugeren besidder.
- færdighedsniveau – Denne numeriske egenskab kvantificerer jobsøgendes ekspertise inden for en bestemt færdighed. Et tal fra 1 (begynder) til 10 (ekspert) angiver deres erfaringsniveau.
Til sidst, skill_set tabel indeholder beskrivelser af alle de færdigheder, der henvises til i ovenstående tabels skill_set_id attribut. Den indeholder kun to kolonner, et skill_set_name og dets relaterede id .
3. Opslå og slå op på job
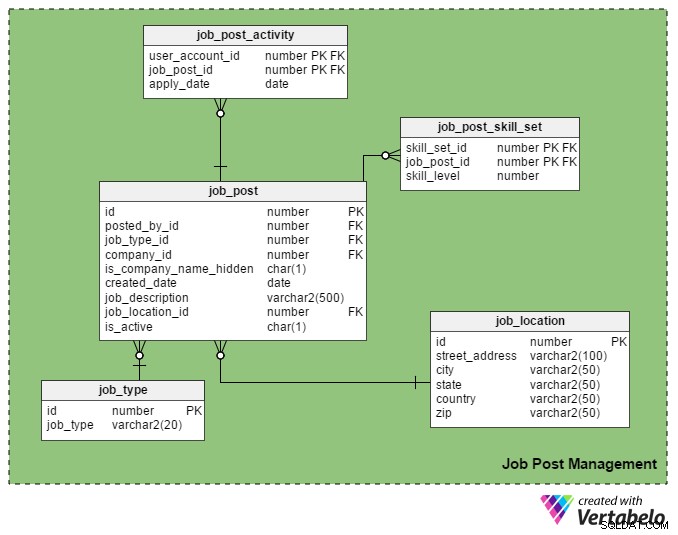
Dette er den vigtigste USP (Unique Selling Point) for en jobportal. Kun registrerede rekrutterere har tilladelse til at slå et job op på portalen, og kun registrerede jobsøgende må ansøge dem.
job_post tabel er hovedtabellen i dette emneområde. Som du måske kan gætte, indeholder den detaljer om jobopslag. Alle de andre tabeller i dette afsnit er oprettet omkring det og forbundet med det.
- id – Dette er den primære nøgle i denne tabel. Hver stilling er tildelt et unikt nummer, og dette nummer henvises til i andre tabeller.
- indsendt_af_id – Denne kolonne indeholder register_user_id af den rekrutterer, der har slået jobbet op.
- job_type_id – Denne kolonne angiver, om jobbets varighed er permanent eller midlertidig (kontrakt).
- virksomheds-id – Denne kolonne gemmer id'et for virksomheden relateret til jobopslaget. Det er en reference til
companytabel. - er_virksomhedsnavn_skjult - Dette er en flagkolonne, der viser, om virksomhedens navn skal vises til jobsøgende. Rekrutterere foretrækker måske ikke at vise firmanavne på deres opslag. I stedet bruger de udtryk som "Global Automobile Company", "California-Based IT Company" og så videre.
- oprettet_dato – Dette gemmer datoen, hvor jobbet er slået op.
- jobbeskrivelse – Dette indeholder en kort beskrivelse af jobbet.
- job_location_id – Dette henviser til en attribut i
job_locationtabel, der gemmer den faktiske placering af jobbet:adresse, by, stat, land og postnummer. - er_aktiv – Dette betyder, om et job stadig er ledigt. Rekrutterere kan markere deres stillinger som inaktive, så snart stillingerne er besat.
job_post_skill_set tabel gemmer detaljer om de færdigheder, der kræves til et job. Tabelstrukturen er identisk med seeker_skill_set bord.
Og den sidste tabel i dette afsnit, job_post_activity tabel, indeholder detaljer om, hvilke jobsøgende der søger et job og hvornår.
Hvad ville du føje til denne online jobportal-datamodel?
Nutidens online jobportaler gør mere end at give en platform til at opslå og søge job. De omfatter ofte andre professionelle tjenester som:
- Et personligt dashboard til at holde styr på jobansøgninger
- Opdateringer i realtid på applikationer
- Video-CV-byggere
- Eksperttjenester til at skrive CV
- LinkedIn eller andre profilbyggere på sociale medier
- Lønrapporter på tværs af jobroller, virksomheder, brancher eller geografiske lokationer
Hvis vi ville bygge disse funktioner ind i vores system, hvilke yderligere ændringer skulle vi så foretage? Kan du komme i tanke om andre must-haves i en jobportal?
Fortæl os venligst dine synspunkter i kommentarfeltet.