Denne artikel er den anden i en serie om optimeringstærskler relateret til gruppering og aggregering af data. I del 1 gav jeg den omvendte formel for Stream Aggregate-operatøromkostningerne. Jeg forklarede, at denne operatør skal forbruge rækkerne ordnet af grupperingssættet (en hvilken som helst rækkefølge af dets medlemmer), og at når dataene er opnået forudbestilt fra et indeks, får du lineær skalering med hensyn til antallet af rækker og antallet af grupper. Der er heller ikke behov for hukommelsesbevilling i sådan et tilfælde.
I denne artikel fokuserer jeg på omkostningsberegning og skalering af en strømaggregatbaseret operation, når dataene ikke opnås forudbestilt fra et indeks, men skal sorteres først.
I mine eksempler vil jeg bruge PerformanceV3-eksempeldatabasen, som i del 1. Du kan downloade scriptet, der opretter og udfylder denne database herfra. Før du kører eksemplerne fra denne artikel, skal du sørge for at køre følgende kode først for at slippe et par unødvendige indekser:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
De eneste to indekser, der skal være tilbage i denne tabel, er idx_cl_od (grupperet med orderdate som nøgle) og PK_Orders (ikke-klynget med orderid som nøglen).
Sortér + Stream Samlet
Fokus i denne artikel er at prøve at finde ud af, hvordan en strømaggregatoperation skaleres, når dataene ikke er forudbestilt af grupperingssættet. Da Stream Aggregate-operatøren skal behandle de bestilte rækker, hvis de ikke er forudbestilt i et indeks, skal planen inkludere en eksplicit sorteringsoperator. Så omkostningerne ved den samlede operation, du bør tage i betragtning, er summen af omkostningerne for Sort + Stream Aggregate-operatørerne.
Jeg vil bruge følgende forespørgsel (vi kalder det forespørgsel 1) til at demonstrere en plan, der involverer en sådan optimering:
SELECT shipperid, MAX(orderdate) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
Planen for denne forespørgsel er vist i figur 1.

Figur 1:Plan for forespørgsel 1
Grunden til at jeg bruger et tabeludtryk med et TOP-filter er for at kontrollere det nøjagtige antal (estimerede) rækker involveret i grupperingen og aggregeringen. Anvendelse af kontrollerede ændringer gør det nemmere at prøve at omdanne omkostningsformlerne.
Hvis du undrer dig over, hvorfor filtrering af et så lille antal rækker i dette eksempel, har det at gøre med de optimeringstærskler, der gør denne strategi foretrukket frem for Hash Aggregate-algoritmen. I del 3 vil jeg beskrive omkostningsberegning og skalering af hash-alternativet. I tilfælde, hvor optimeringsværktøjet ikke selv vælger en strømaggregatoperation, f.eks. når et stort antal rækker er involveret, kan du altid gennemtvinge det med hintet OPTION(ORDER GROUP) under researchprocessen. Når du fokuserer på omkostningerne ved serieplaner, kan du naturligvis tilføje et MAXDOP 1-tip for at eliminere parallelitet.
Som nævnt, for at evaluere omkostningerne og skaleringen af en ikke-forudbestilt strømaggregatalgoritme, skal du tage højde for summen af Sort + Stream Aggregate-operatorerne. Du kender allerede omkostningsformlen for Stream Aggregate-operatøren fra del 1:
@numrows * 0,0000006 + @numrows * 0,0000005I vores forespørgsel har vi 100 estimerede inputrækker og 5 estimerede outputgrupper (5 forskellige afsender-id'er estimeret baseret på tæthedsoplysninger). Så prisen for Stream Aggregate-operatøren i vores plan er:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Lad os prøve at finde ud af kalkulationsformlen for sorteringsoperatoren. Husk, at vores fokus er de estimerede omkostninger og skalering, fordi vores ultimative mål er at finde ud af optimeringstærskler, hvor optimeringsværktøjet ændrer sine valg fra en strategi til en anden.
I/O-omkostningsestimatet ser ud til at være fast:0,0112613. Jeg får de samme I/O-omkostninger uanset faktorer som antal rækker, antal sorteringskolonner, datatype og så videre. Dette er sandsynligvis for at tage højde for noget forventet I/O-arbejde.
Med hensyn til CPU-omkostningerne, desværre afslører Microsoft ikke offentligt de nøjagtige algoritmer, som de bruger til sortering. Blandt de almindelige algoritmer, der bruges til sortering af databasemotorer generelt, er forskellige implementeringer af flettesortering og quicksort. Takket være indsatsen fra Paul White, som er glad for at se på Windows debugger stakspor (ikke alle af os har maven til dette), har vi lidt mere indsigt i emnet, udgivet i hans serie "Internals of the Seven SQL Server sorterer." Ifølge Pauls resultater bruger den generelle sorteringsklasse (brugt i ovenstående plan) flettesortering (først intern, derefter overgang til ekstern). I gennemsnit kræver denne algoritme n log n sammenligninger for at sortere n elementer. Med dette i tankerne er det sandsynligvis et sikkert bud som udgangspunkt at antage, at CPU-delen af operatørens omkostninger er baseret på en formel som:
Operatør CPU-omkostning =Selvfølgelig kan dette være en oversimplificering af den faktiske omkostningsformel, som Microsoft bruger, men i mangel af dokumentation om sagen er dette et indledende bedste gæt.
Dernæst kan du få sorterings-CPU-omkostningerne fra to forespørgselsplaner, der er produceret til sortering af forskellige antal rækker, f.eks. 1000 og 2000, og baseret på disse og ovenstående formel, omvendt manipulere sammenligningsomkostningerne og opstartsomkostningerne. Til dette formål behøver du ikke bruge en grupperet forespørgsel; det er nok bare at lave en grundlæggende BESTILLING AF. Jeg vil bruge følgende to forespørgsler (vi kalder dem forespørgsel 2 og forespørgsel 3):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) SOM DORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) SOM DORDER BY myorderid;
Pointen med at sortere efter resultatet af en beregning er at tvinge en sorteringsoperator til at blive brugt i planen.
Figur 2 viser de relevante dele af de to planer:
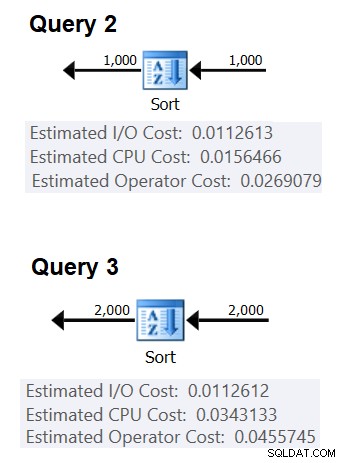
Figur 2:Planer for forespørgsel 2 og forespørgsel 3
For at prøve at udlede omkostningerne ved en sammenligning, skal du bruge følgende formel:
sammenligningsomkostninger =
((
/ (
(0,0343133 – 0,0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2,25061348918698E-06
Hvad angår opstartsomkostningerne, kan du udlede det baseret på begge planer, f.eks. baseret på planen, der sorterer 2000 rækker:
opstartsomkostninger =0,0343133 – 2000*LOG(2000) * 2,25061348918698E-06 =9,99127891201865>E-01865>
Og dermed bliver vores Sort CPU-omkostningsformel:
Sorter operatør CPU-omkostninger =9,99127891201865E-05 + @numrows * LOG(@numrows) * 2,25061348918698E-06Ved at bruge lignende teknikker vil du opdage, at faktorer som den gennemsnitlige rækkestørrelse, antallet af bestillingskolonner og deres datatyper ikke påvirker de anslåede sorterings-CPU-omkostninger. Den eneste faktor, der synes at være relevant, er det estimerede antal rækker. Bemærk, at sorteringen skal have en hukommelsesbevilling, og bevillingen er proportional med antallet af rækker (ikke grupper) og den gennemsnitlige rækkestørrelse. Men vores fokus i øjeblikket er de estimerede operatøromkostninger, og det ser ud til, at dette estimat kun er påvirket af det estimerede antal rækker.
Denne formel ser ud til at forudsige CPU-omkostningerne godt op til en tærskel på omkring 5.000 rækker. Prøv det med følgende tal:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
VÆLG tal, 9,99127891201865E-05 + tal * LOG(tal) * 2,25061348918698E-06 SOM forudsagt pris FRA (VÆRDI(100), (200), (300), (400)), (1050)), (1050)), , (2000), (3000), (4000), (5000)) AS D(tal);
Sammenlign hvad formlen forudsiger og de estimerede CPU-omkostninger, som planerne viser for følgende forespørgsler:
SELECT orderid % 1000000000 som myorderid FRA (VÆLG TOP (100) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 som myorderid FRA (VÆLG TOP (200) * FRA dbo.Orders) SOM BESTIL AF myorderid; VÆLG ordre-id % 1000000000 som myorderid FRA (SELECT TOP (300) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 som myorderid FRA (SELECT TOP (400) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 som myorderid FRA (SELECT TOP (500) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 som myorderid FRA (SELECT TOP (1000) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 som myorderid FRA (SELECT TOP (2000) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 som myorderid FRA (SELECT TOP (3000) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 som myorderid FRA (SELECT TOP (4000) * FRA dbo.Orders) SOM BESTILLES AF myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) SOM DORDER BY myorderid;
Jeg fik følgende resultater:
numrows forudsagt pris estimeret omkostningsforhold ------------------ --------------- -------------- --- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
Kolonnen forudsagte omkostninger viser forudsigelsen baseret på vores omvendt udviklede formel, kolonnen anslåede omkostninger viser de anslåede omkostninger, der vises i planen, og kolonneforholdet viser forholdet mellem sidstnævnte og førstnævnte.
Forudsigelsen virker ret præcis op til 5.000 rækker. Men med tal større end 5.000 holder vores omvendte formel op med at fungere godt. Følgende forespørgsel giver dig forudsigelserne for 6K, 7K, 10K, 20K, 100K og 200K rækker:
VÆLG tal, 9,99127891201865E-05 + tal * LOG(tal) * 2,25061348918698E-06 SOM forudsagt pris FRA (VÆRDI(6000), (7000), (100000), (010000), (010000), (02) ) AS D(tal);
Brug følgende forespørgsler til at få de estimerede CPU-omkostninger fra planerne (bemærk tippet om at fremtvinge en seriel plan, da det med et større antal rækker er mere sandsynligt, at du får en parallel plan, hvor omkostningsformlerne er justeret for parallelitet):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) SOM DORDER BY myorderid OPTION(MAXDOP 1); VÆLG ordre-id % 1000000000 som myorderid FRA (VÆLG TOP (7000) * FRA dbo.Orders) SOM BESTILLES AF myorderid OPTION(MAXDOP 1); VÆLG ordre-id % 1000000000 som myorderid FRA (SELECT TOP (10000) * FRA dbo.Orders) SOM DORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 som myorderid FRA (SELECT TOP (20000) * FRA dbo.Orders) SOM DORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) SOM DORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) SOM DORDER BY myorderid OPTION(MAXDOP 1);
Jeg fik følgende resultater:
numrows forudsagt pris estimeret omkostningsforhold ------------------ --------------- -------------- --- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10000 0.207389 0.603420 2.9096 20000 0.445878 1.311710 2.9419 100000 2.591210 7.623920 2.942222 200000 5.494330 16.194200Som du kan se, ud over 5.000 rækker bliver vores formel mindre og mindre nøjagtig, men mærkeligt nok stabiliserer nøjagtighedsforholdet sig på omkring 2,94 på omkring 20.000 rækker. Dette indebærer, at med store tal gælder vores formel stadig, kun med en højere sammenligningsomkostning, og at omkring mellem 5.000 og 20.000 rækker, går den gradvist over fra den lavere sammenligningsomkostning til den højere. Men hvad kan forklare forskellen mellem den lille skala og den store skala? Den gode nyhed er, at svaret ikke er så komplekst som at forene kvantemekanik og generel relativitetsteori med strengteori. Det er bare det, at Microsoft i mindre skala ville tage højde for det faktum, at CPU-cachen sandsynligvis vil blive brugt, og til omkostningsformål antager de en fast cachestørrelse.
Så for at finde ud af sammenligningsomkostningerne i stor skala, vil du bruge sorteringen af CPU-omkostninger fra to planer for tal over 20.000. Jeg bruger 100.000 og 200.000 rækker (sidste to rækker i tabellen ovenfor). Her er formlen til at udlede sammenligningsomkostningerne:
sammenligningsomkostninger =
(16,1657 – 7,62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6,62193536908588E-06Dernæst er her formlen til at udlede startomkostningerne baseret på planen for 200.000 rækker:
opstartspris =
16,1657 – 200000*LOG(200000) * 6,62193536908588E-06 =1,35166186417734E-04Det kan sagtens være, at opstartsomkostningerne for de små og store vægte er de samme, og at den forskel, vi fik, skyldes afrundingsfejl. I hvert fald, med et stort antal rækker, bliver startomkostningerne ubetydelige sammenlignet med sammenligningernes omkostninger.
Sammenfattende er her formlen for sorteringsoperatørens CPU-omkostninger for store tal (>=20000):
Operatør CPU-pris =1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06Lad os teste nøjagtigheden af formlen med 500K, 1M og 10M rækker. Følgende kode giver dig vores formels forudsigelser:
SELECT numrows, 1,35166186417734E-04 + numrows * LOG(numrows) * 6,62193536908588E-06 AS predicated cost FROM (VALUES(500000), (1000000), (1000000), (1000000), (1000000), (1000s)s DAS);Brug følgende forespørgsler til at få de anslåede CPU-omkostninger:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) SOM D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) SOM D ORDER BY myorderid OPTION(MAXDOP 1); SELECT CHECKSUM(NEWID()) as myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);Jeg fik følgende resultater:
numrows forudsagt pris estimeret omkostningsforhold ------------------ --------------- -------------- --- --- 500000 43,4479 43,448 1,0000 1000000 91,4856 91,486 1,0000 10000000 1067,3300 1067,340 1,0000Det ser ud til, at vores formel for store tal klarer sig ret godt.
Sæt det hele sammen
De samlede omkostninger ved at anvende et strømaggregat med eksplicit sortering for et lille antal rækker (<=5.000 rækker) er:
+ + =
0,0112613
+ 9,99127891201865E-05 + @numrows * LOG(@ numrows) * 2,25061348918698E-06
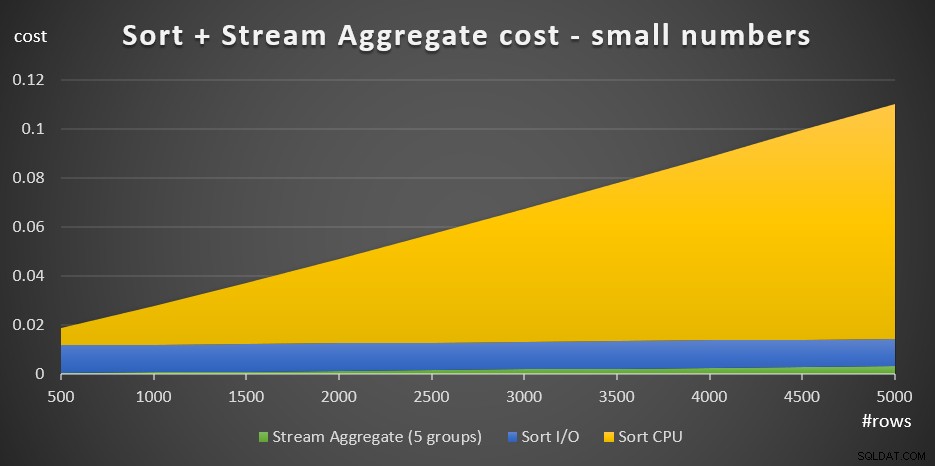
+ @numrows * 0,0000006 + @numrows * 0,0000005Figur 3 har et områdediagram, der viser, hvordan disse omkostninger skaleres.
Figur 3:Sorteringsomkostninger + Streamaggregat for små antal af rækkerSorterings-CPU-omkostningerne er den mest væsentlige del af de samlede Sort + Stream samlede omkostninger. Alligevel, med et lille antal rækker, er Stream Aggregate-omkostningerne og Sort I/O-delen af omkostningerne ikke helt ubetydelige. Visuelt kan du tydeligt se alle tre dele i diagrammet.
Hvad angår et stort antal rækker (>=20.000), er omkostningsformlen:
0,0112613
+ 1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06
+ @numrows * 0,000s.Jeg så ikke meget værdi i at forfølge den nøjagtige måde, hvorpå sammenligningsomkostningerne går fra den lille til den store skala.
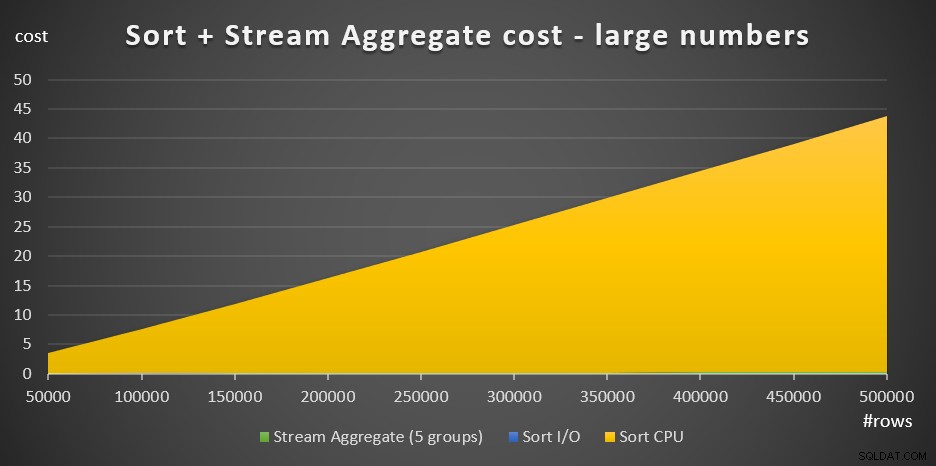
Figur 4 har et områdediagram, der viser, hvordan omkostningerne skaleres for store tal.
Figur 4:Sorteringsomkostninger + Streamaggregat for et stort antal rækkerMed et stort antal rækker er Stream Aggregate-omkostningerne og Sort I/O-omkostningerne så ubetydelige sammenlignet med Sort CPU-omkostningerne, at de ikke engang er synlige for det blotte øje i diagrammet. Derudover er den del af Sort CPU-omkostningerne, der tilskrives opstartsarbejdet, også ubetydelig. Derfor er den eneste del af omkostningsberegningen, der virkelig er meningsfuld, den samlede sammenligningsomkostning:
@numrows * LOG(@numrows) *Det betyder, at når du skal evaluere skaleringen af Sort + Stream Aggregate-strategien, kan du forenkle den til denne dominerende del alene. Hvis du f.eks. har brug for at evaluere, hvordan prisen vil skalere fra 100.000 rækker til 100.000.000 rækker, kan du bruge formlen (bemærk, at sammenligningsomkostningerne er irrelevante):
(100000000 * LOG(100000000)*) / (100000 * LOG(100000)*) =1600Dette fortæller dig, at når antallet af rækker stiger fra 100.000 med en faktor 1.000 til 100.000.000, så stiger de estimerede omkostninger med en faktor på 1.600.
Skalering fra 1.000.000 til 1.000.000.000 rækker beregnes som:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500Det vil sige, at når antallet af rækker stiger fra 1.000.000 med en faktor på 1.000, så stiger de estimerede omkostninger med en faktor på 1.500.
Disse er interessante observationer om måden, hvorpå Sort + Stream Aggregate-strategien skalerer. På grund af dens meget lave opstartsomkostninger og ekstra lineære skalering, ville du forvente, at denne strategi vil klare sig godt med meget små antal rækker, men ikke så godt med store tal. Også det faktum, at Stream Aggregate-operatøren alene repræsenterer en så lille brøkdel af omkostningerne sammenlignet med, når der også er behov for en sortering, fortæller dig, at du kan få markant bedre ydeevne, hvis situationen er sådan, at du er i stand til at skabe et understøttende indeks .
I den næste del af serien vil jeg dække skaleringen af Hash Aggregate-algoritmen. Hvis du nyder denne øvelse med at prøve at finde ud af omkostningsformler, så se om du kan finde ud af det for denne algoritme. Det, der er vigtigt, er at finde ud af de faktorer, der påvirker det, måden det skalerer på og betingelserne, hvor det klarer sig bedre end de andre algoritmer.