For et par dage siden udkom en ny version af ClusterControl, 1.7.2, hvor vi kan se flere nye funktioner, en af de vigtigste er understøttelsen af TimescaleDB.
TimescaleDB er en open source tidsseriedatabase optimeret til hurtig indlæsning og komplekse forespørgsler, der understøtter fuld SQL. Det er baseret på PostgreSQL, og det tilbyder det bedste fra NoSQL og Relationelle verdener til tidsseriedata. TimescaleDB understøtter streaming replikering som den primære metode til replikering, som kan bruges i en høj tilgængelighed. PostgreSQL kommer dog ikke med automatisk failover, og dette er et problem i et produktionsmiljø med høj tilgængelighed. Manuel failover indebærer normalt, at et menneske bliver søgt og skal finde en computer, logge ind på systemerne, forstå, hvad der foregår, før failover-procedurer påbegyndes. Dette udmønter sig i en lang nedetid. Heldigvis er der en måde at automatisere failovers med ClusterControl, som nu understøtter TimescaleDB.
I denne blog vil vi se, hvordan du implementerer en replikeret TimescaleDB-opsætning med automatisk failover med blot et par klik ved at bruge ClusterControl. Vi vil også se, hvordan du tilføjer et enkelt databaseslutpunkt til applikationer via HAProxy. Som en forudsætning bør du installere 1.7.2-versionen af ClusterControl på en dedikeret vært eller VM.
Implementer TimescaleDB
For at udføre en ny installation af TimescaleDB fra ClusterControl skal du blot vælge indstillingen "Deploy" og følge instruktionerne, der vises. Bemærk, at hvis du allerede har en TimescaleDB-instans kørende, så skal du vælge 'Importér eksisterende server/database' i stedet.
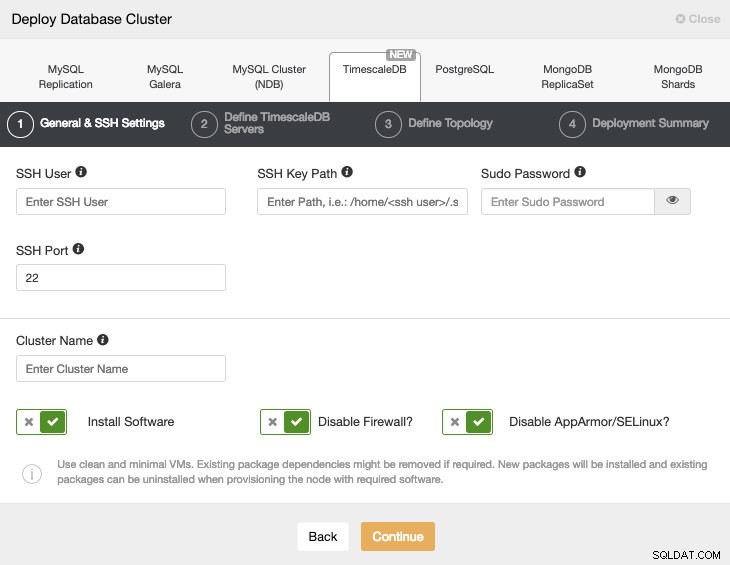
Når vi vælger TimescaleDB, skal vi angive bruger, nøgle eller adgangskode og port for at forbinde med SSH til vores TimescaleDB-værter. Vi har også brug for et navn til vores nye klynge, og hvis vi ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for os.
Tjek venligst ClusterControl-brugerkravet for denne opgave her.
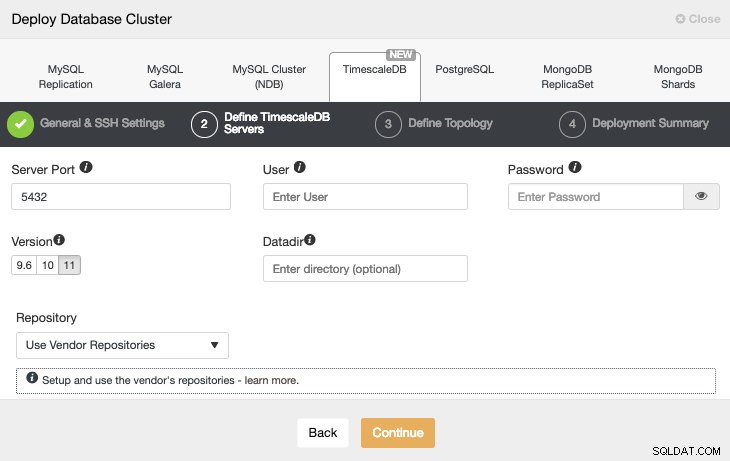
Efter opsætning af SSH-adgangsoplysningerne skal vi definere databasebruger, version og datadir (valgfrit). Vi kan også angive, hvilket lager der skal bruges.
I det næste trin skal vi tilføje vores servere til den klynge, vi skal oprette.
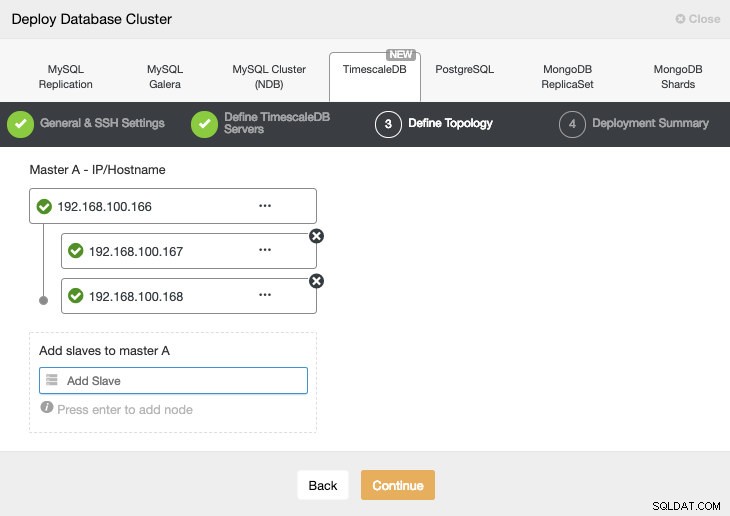
Når vi tilføjer vores servere, kan vi indtaste IP eller værtsnavn.
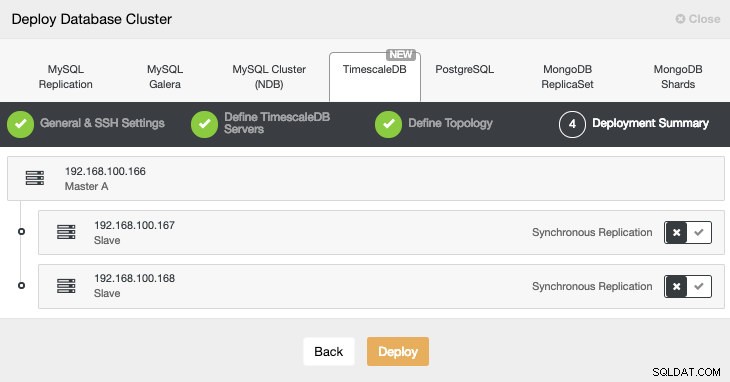
I det sidste trin kan vi vælge, om vores replikering skal være Synchronous eller Asynchronous.
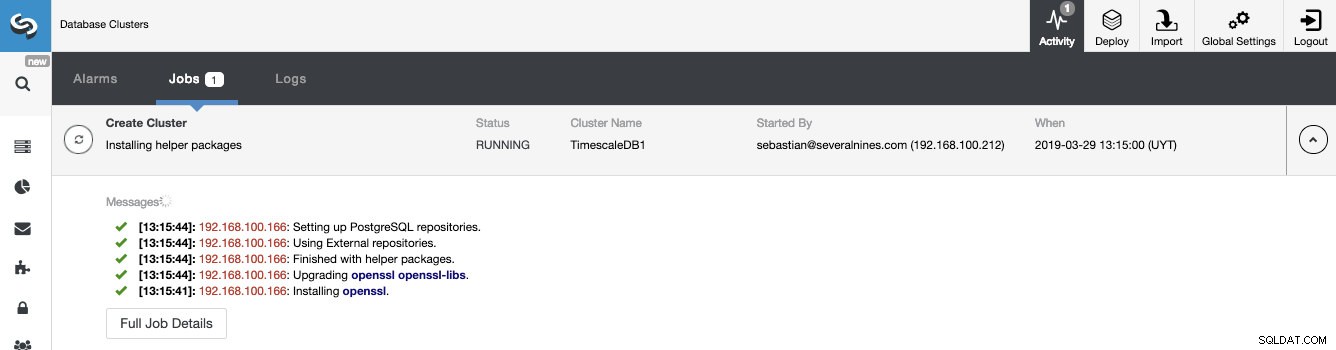
Vi kan overvåge status for oprettelsen af vores nye klynge fra ClusterControl-aktivitetsmonitoren.
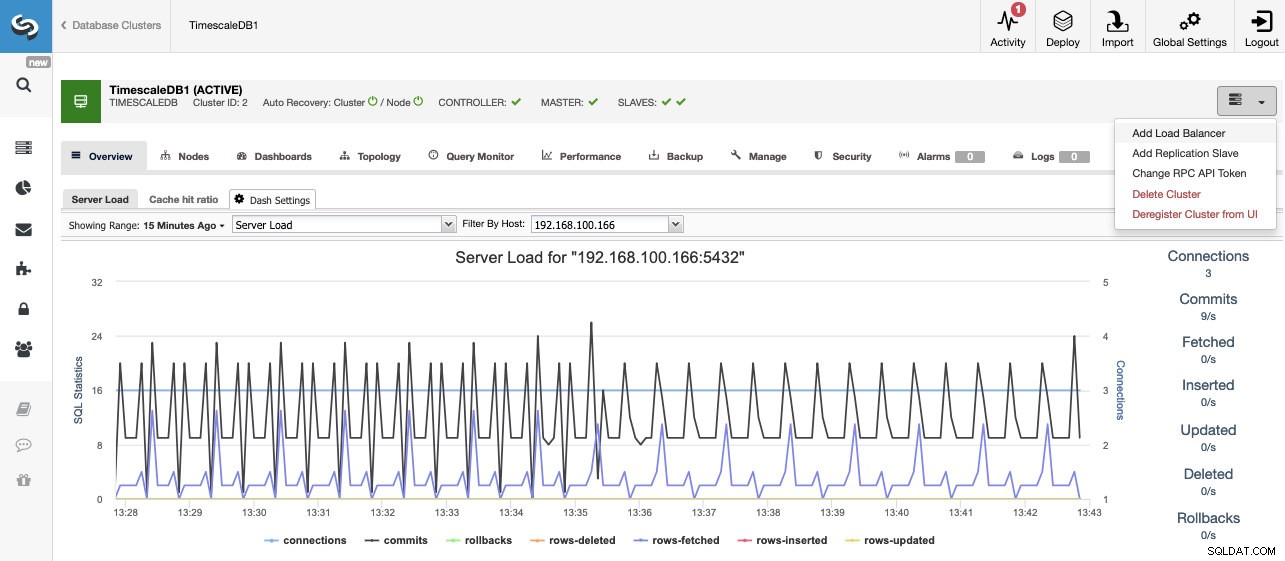
Når opgaven er færdig, kan vi se vores nye TimescaleDB-klynge på hovedskærmen for ClusterControl.

Når vi har oprettet vores klynge, kan vi udføre flere opgaver på den, såsom at tilføje en belastningsbalancer (HAProxy) eller en ny replika.
Skalering af tidsskalaDB
Hvis vi går til klyngehandlinger og vælger "Tilføj replikeringsslave", kan vi enten oprette en ny replika fra bunden eller tilføje en eksisterende TimescaleDB-database som en replika.
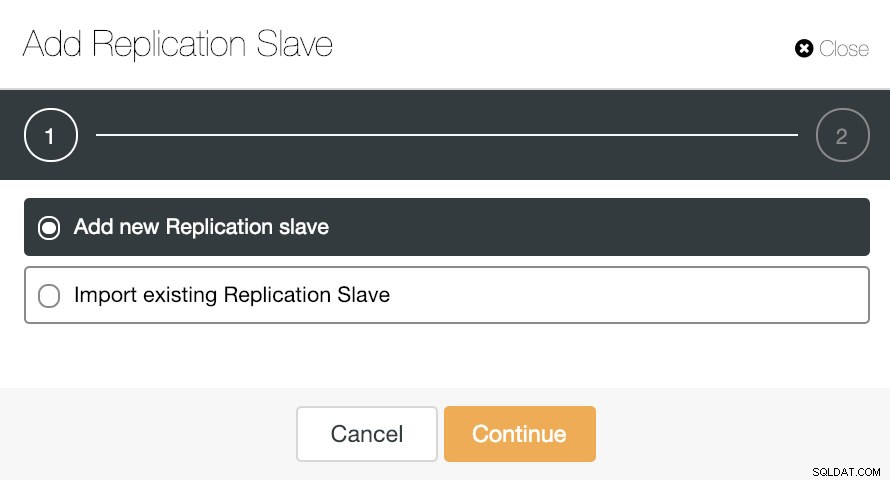
Lad os se, hvordan det kan være en rigtig nem opgave at tilføje en ny replikeringsslave.
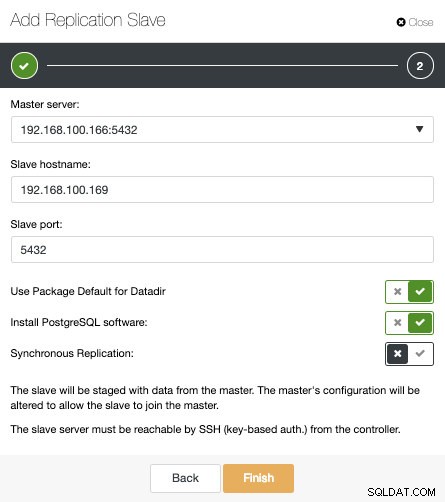
Som du kan se på billedet, skal vi kun vælge vores Master server, indtaste IP adressen til vores nye slave server og database porten. Derefter kan vi vælge, om vi vil have ClusterControl til at installere softwaren for os, og om replikeringsslaven skal være Synchronous eller Asynchronous.
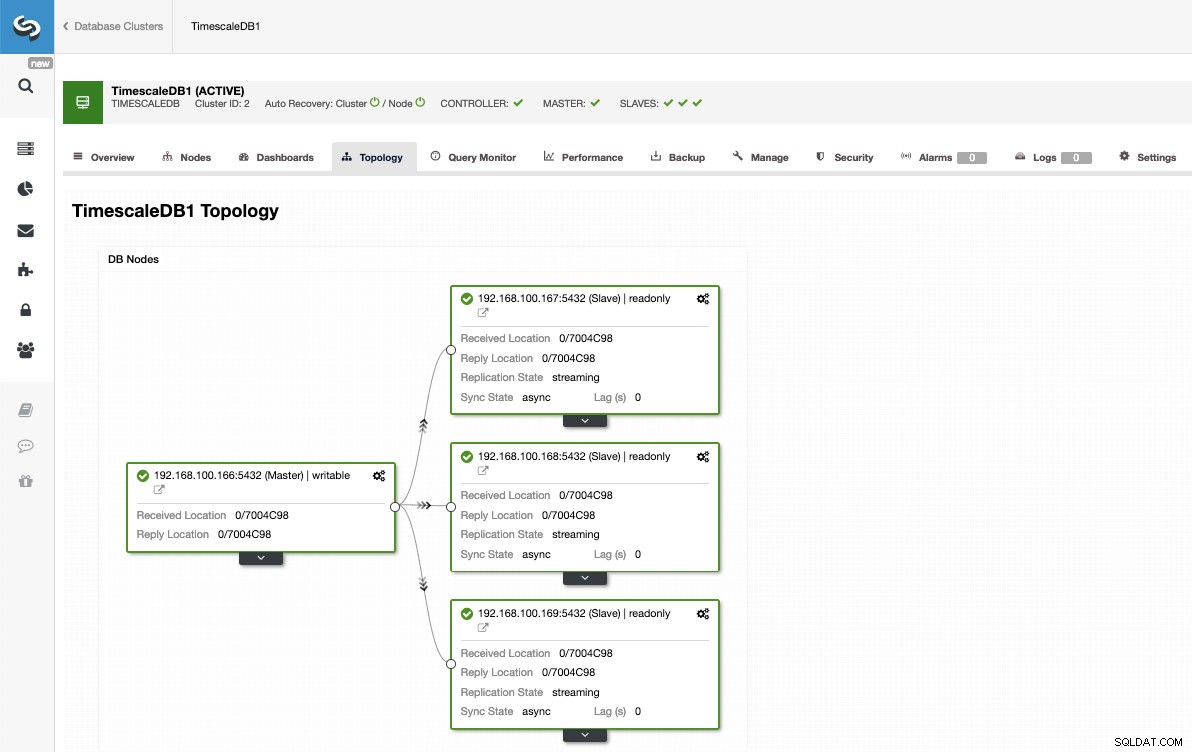
På denne måde kan vi tilføje så mange replikaer, som vi vil, og sprede læst trafik mellem dem ved hjælp af en load balancer, som vi også kan implementere med ClusterControl.
Fra ClusterControl kan du også udføre forskellige administrationsopgaver såsom Genstart vært, Genopbyg replikeringsslave eller Fremme slave med et enkelt klik.
Konklusion
Som vi har set ovenfor, kan du nu implementere TimescaleDB ved at bruge ClusterControl. Når den er installeret, tilbyder ClusterControl en lang række funktioner, lige fra overvågning, alarmering, automatisk failover, backup, punkt-i-tidsgendannelse, sikkerhedskopieringsbekræftelse til skalering af læste replikaer. Dette kan hjælpe dig med at administrere TimescaleDB på en venlig og intuitiv måde.