I denne artikel vil jeg forklare, hvordan man flytter en tabel fra den primære filgruppe til den sekundære filgruppe. Lad os først forstå, hvad der er datafil, filgruppe og type filgrupper.
Databasefiler og filgrupper
Når SQL Server er installeret på en hvilken som helst server, opretter den en primær datafil og logfil til at gemme data. Den primære datafil gemmer data og databaseobjekter som tabeller, indeks, lagrede procedurer osv. Logfiler gemmer information, der kræves for at gendanne transaktioner. Datafiler kan slås sammen i filgrupper.
SQL Server har tre typer filer
- Primær fil :Den oprettes, når SQL-serveren installeres, og den indeholder databasens metadata og information. Brugerdata, objekter kan gemmes på de Primære datafiler. Den primære fil har filtypenavnet .mdf.
- Sekundær fil :Sekundære filer er brugerdefinerede. De gemmer brugerdata, objekter oprettet af en bruger. De har .ndf-udvidelsen.
- Transaktionslogfil s:T-Logs-filerne logger alle de transaktioner, der er udført for at gendanne databasen. Logfiltypen i .ldf.
Som jeg nævnte ovenfor, kan datafiler grupperes i en filgruppe. Mens SQL Server installeres, opretter den den primære filgruppe, der har en primær datafil. Sekundære filgrupper er brugerdefinerede. De har sekundære datafiler. Når vi opretter en ny database, kan vi oprette sekundære datafiler og filgrupper. Tilføjelse af sekundære datafiler hjælper med at forbedre ydeevnen. Det kan oprettes på forskellige diskdrev eller separate diskpartitioner, hvilket reducerer IO vente- og læse-skriveforsinkelse.
Det anbefales at opbevare tabeller og indekser i separate filgrupper. Desuden forbedres ydeevnen ved at holde store tabeller i separate filer.
Der er tre typer filgrupper:
- Rækkefilgruppe :Rækkefilgruppe, også kendt som Primær filgruppe, indeholder en primær datafil. SQL-objekt, data, systemtabeller allokeres til den primære filgruppe.
- Hukommelsesoptimeret filgruppe :Hukommelsesoptimeret filgruppe indeholder hukommelsesoptimerede tabeller og data. For at aktivere OLTP i hukommelsen skal vi oprette en hukommelsesoptimeret filgruppe.
- FileStream :Fil-stream filgruppe indeholder fil-stream data som billeder, dokumenter, eksekverbare filer osv. Den primære filgruppe kan ikke indeholde fil-stream data, vi skal oprette en FileStream fil gruppe. Den indeholder FileStream-dataene.
Demoopsætning
I denne demo oprettede jeg "DemoDatabase" på SQL Server 2017-instansen. Fanerne "Records" og "PatientData" blev oprettet på databasen. Den primære nøgle "PK_CIDX_Records_ID" blev oprettet på "Records"-tabellen, og "CIDX_PatientData_ID"-klyngeindekset blev oprettet på "PatientData"-tabellen. I denne demo vil jeg flytte tabellerne "Records" og "PatientData" fra den primære filgruppe til den sekundære filgruppe.
Til dette skal vi gøre følgende:
- Opret en sekundær filgruppe.
- Tilføj datafiler til den sekundære filgruppe.
- Flyt tabellen til den sekundære filgruppe ved at flytte det klyngede indeks med den primære nøglebegrænsning.
- Flyt tabellerne til den sekundære filgruppe ved at flytte det klyngede indeks uden den primære nøgle.
Opret sekundær filgruppe
En sekundær filgruppe kan oprettes ved hjælp af T-SQL ELLER ved hjælp af Tilføj fil op-guiden fra SQL Server Management Studio. For at tilføje en filgruppe ved hjælp af SSMS skal du åbne SSMS og vælge en database, hvor en filgruppe skal oprettes. Højreklik på databasen og vælg "Egenskaber ”>> vælg “Filgrupper ” og klik på “Tilføj filgruppe ” som vist i følgende billede:
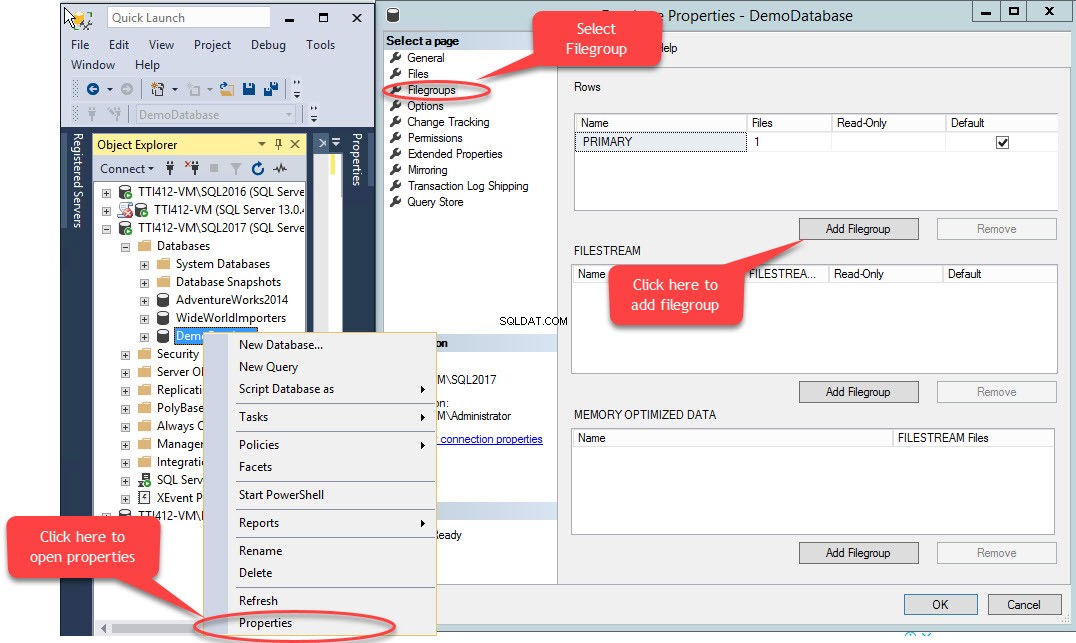
Når vi klikker på "Tilføj filgruppe " knappen, tilføjes en række i "Rækker ” gitter. I "Rækker ” gitter, angiv passende filgruppenavn i “Navn ” kolonne. Filgruppe er hverken skrivebeskyttet eller standard; behold derfor Skrivebeskyttet og Standard afkrydsningsfelter ryddet for ny filgruppe. Se følgende billede:
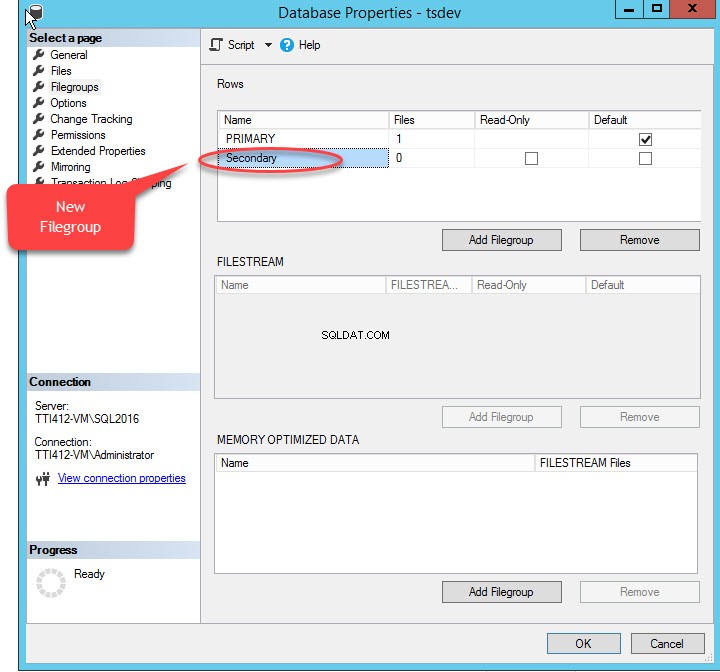
Klik på OK for at lukke dialogboksen.
For at oprette en filgruppe ved hjælp af T-SQL-script skal du køre følgende script.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Tilføjelse af filer til filgruppe
For at tilføje filer i en filgruppe skal du åbne databaseegenskaber, vælge "filer" og klikke på "Tilføj". Som vist på følgende billede:
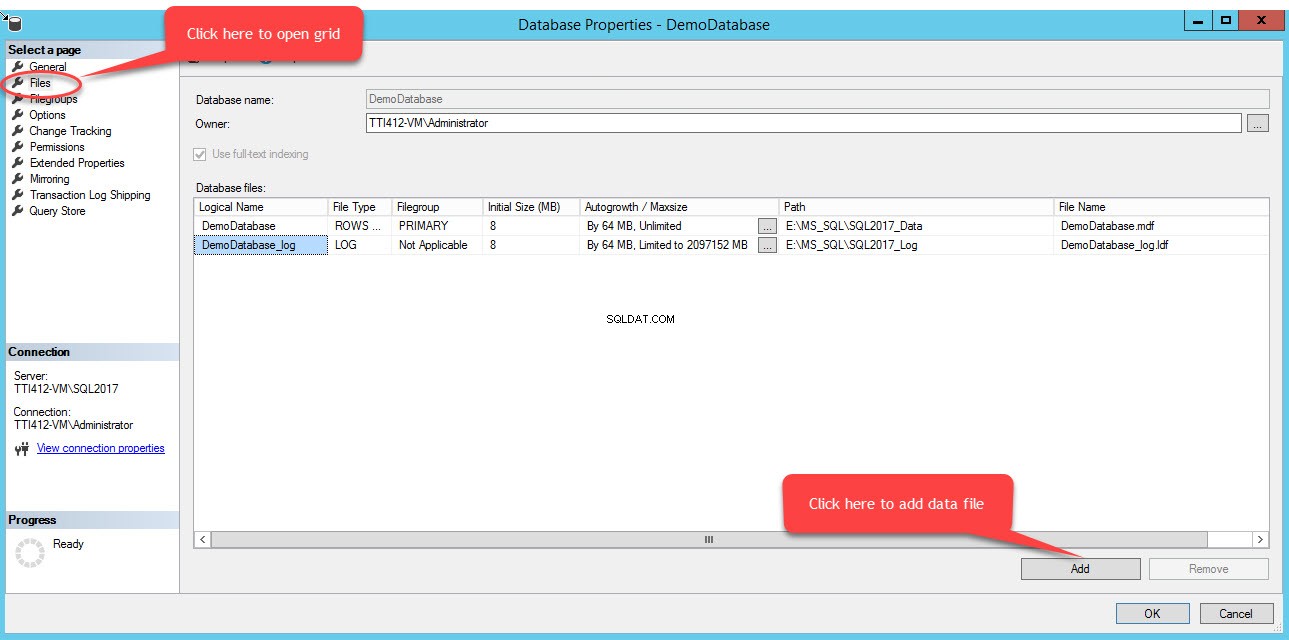
En tom række vil blive tilføjet i Databasefiler gittervisning. Angiv et passende logisk navn i Logisk navn i gittervisningen kolonne, skal du vælge Rækkedata fra Filtype rullemenuen, vælg sekundær fra Filgruppen drop-down boksen, skal du angive den oprindelige størrelse på filen i Oprindelig størrelse kolonner, skal du indstille parameteren for automatisk vækst og maksimal størrelse i Autovækst/Maxsize kolonne, angive den fysiske placering af den sekundære datafil i stien kolonnen og angiv passende filnavn i Filnavn kolonne. Se følgende billede:
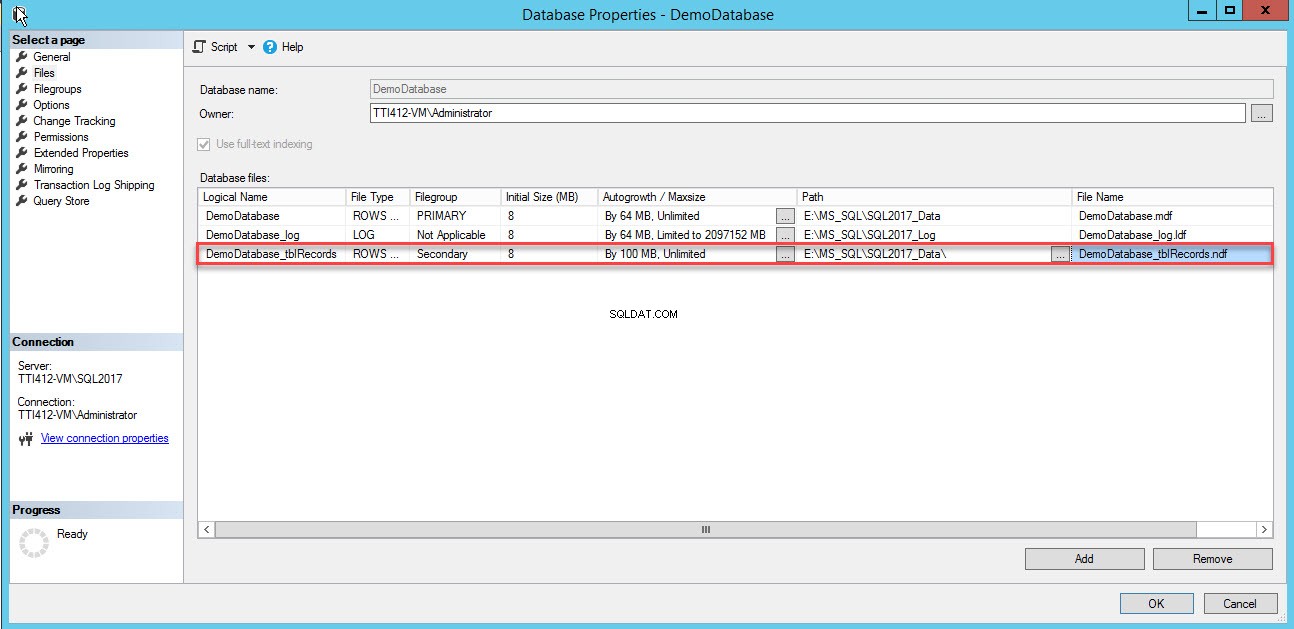
Brug følgende T-SQL-script til at oprette en sekundær datafil.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
Den sekundære datafil er blevet oprettet. Se følgende billede:
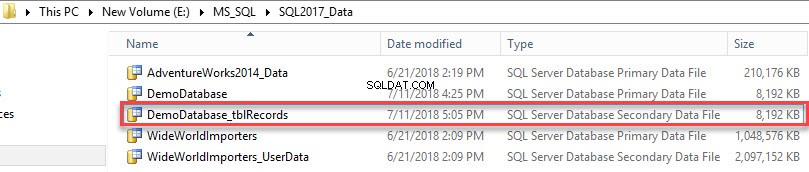
For at se en liste over filgrupper, der er oprettet i databasen, skal du udføre følgende forespørgsel.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Nedenfor er et output af forespørgslen.

Overførsel af eksisterende tabel fra primær filgruppe til sekundær filgruppe
Vi kan flytte en eksisterende tabel til en anden filgruppe ved at flytte det klyngede indeks til en anden filgruppe. Som vi ved, har en bladknude i det klyngede indeks faktiske data; derfor kan flytning af klyngeindeks flytte hele tabellen til en anden filgruppe. Flytning af indeks har en begrænsning:Hvis indekset er en primær nøgle eller en unik begrænsning, kan du ikke flytte indeks ved hjælp af SQL Server Management Studio. For at flytte disse indekser skal vi bruge opret indekset sætning og med DROP_Existing=ON mulighed.
Flytning af grupperet indeks med primær nøglebegrænsning.
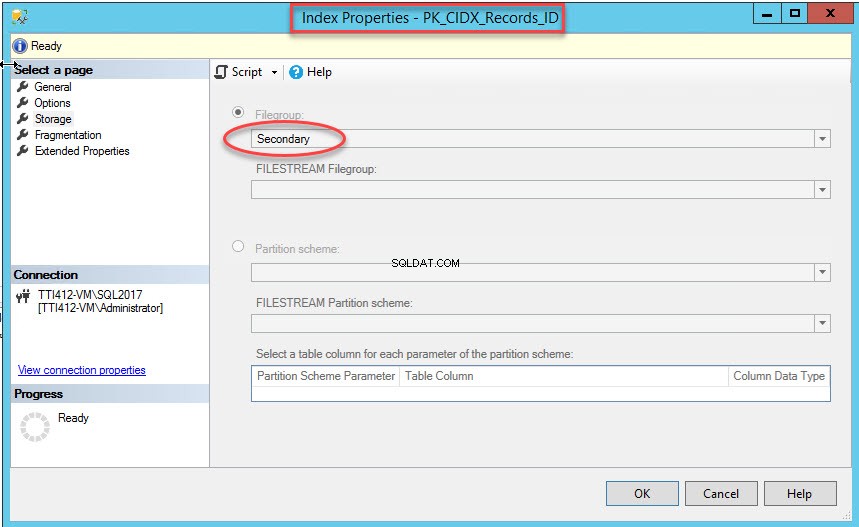
Primær nøgle håndhæver unikke værdier, og skaber derfor det unikke klyngeindeks. Nøglekolonnen er PRN. For at oprette den i den sekundære filgruppe skal du indstille DROP_EXISTING=ON indstilling, og filgruppen skal være sekundær. Udfør følgende script.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
Når kommandoen er udført korrekt, skal du kontrollere, at indekset er blevet oprettet i den sekundære filgruppe. Til dette skal du højreklikke på Lager mulighed i Indeksegenskaber dialog boks. For at åbne indeksegenskaber skal du udvide DemoDatabase database>> udvid tabeller>> udvid indekser . Højreklik på PK_CIDX_Records_ID , som vist på følgende billede:
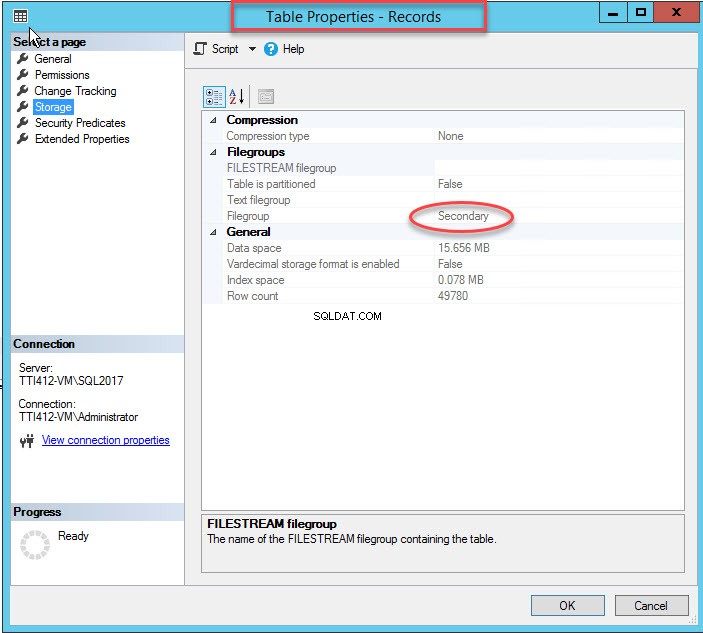
Som jeg nævnte, når et klynget indeks flytter til en sekundær filgruppe, vil tabellen blive flyttet til den sekundære filgruppe. For at bekræfte det skal du højreklikke på Lager mulighed iTabelegenskaber dialog boks. For at åbne indeksegenskaber skal du udvide DemoDatabase database>> udvid Tabel s>> højreklik på Records, og vælg lagerplads som vist på følgende billede:
Flytning af grupperet indeks uden primærnøgle
Vi kan flytte klynget indeks uden primær nøgle ved hjælp af SQL Server Management Studio. For at gøre det skal du udvide DemoDatabasen database>> udvid tabeller>> udvid Indekse s>> højreklik på CIDX_PatientData_ID indeks og vælg Egenskaber, som vist på følgende billede:
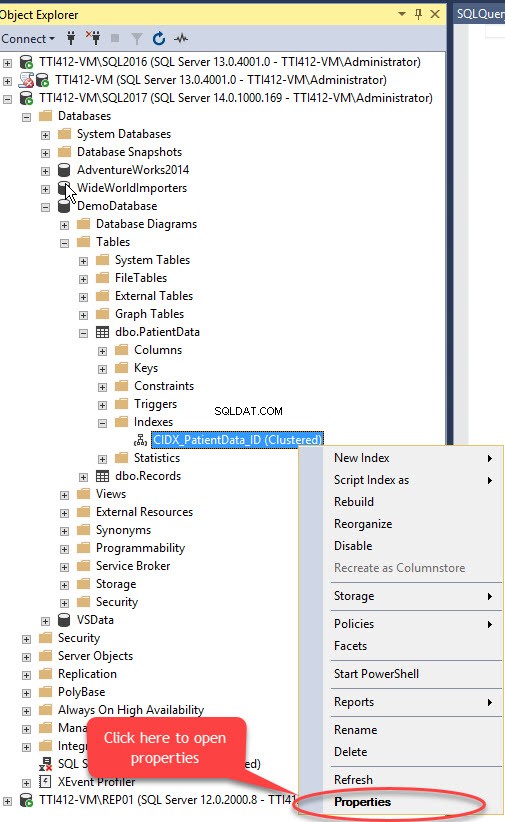
Indeksegenskaber dialogboksen åbnes. Vælg Opbevaring i dialogboksen og klik på Filgruppe i vinduet Lager rullemenuen skal du vælge Sekundær filgruppe og klik på OK, som vist på følgende billede:
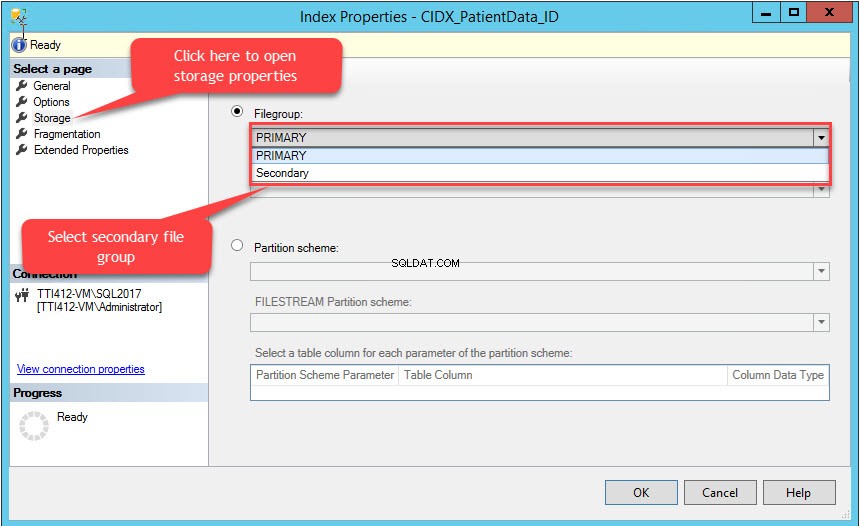
Ændring af indeksfilgruppen vil genskabe hele indekset. Når indekset er genskabt, skal du åbne Tabelegenskaber og vælg et lager.
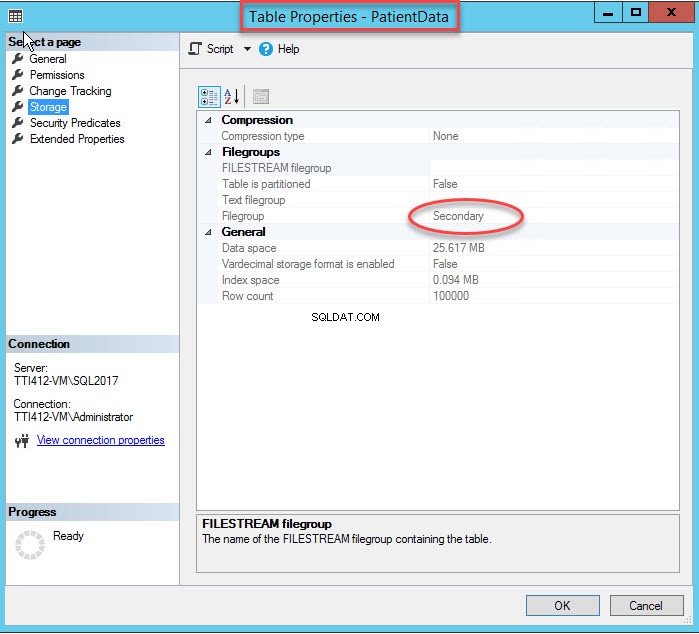
Som du kan se på billedet ovenfor, sammen med flytning af CIDX_PatientData_ID grupperet indeks til den sekundære filgruppe,Patientdata tabellen flyttes også til Sekundær filgruppe.
Ved at udføre følgende forespørgsel kan du finde listen over objekter, der er oprettet til forskellige filgrupper:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Nedenfor er resultatet af forespørgslen:
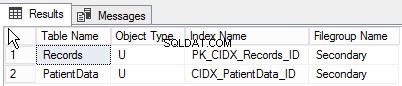
Oversigt
I denne artikel har jeg forklaret
-
- Grundlæggende om datafiler og filgrupper.
- Sådan opretter du en sekundær filgruppe og tilføjer en sekundær datafil til den.
- Flyt tabellen til sekundær filgruppe ved at flytte:
- Primær nøgle.
- Klynget indeks.