Funktionerne RANK, DENSE_RANK og ROW_NUMBER bruges til at hente en stigende heltalsværdi. De starter med en værdi baseret på betingelsen pålagt af ORDER BY-sætningen. Alle disse funktioner kræver ORDER BY-klausulen for at fungere korrekt. I tilfælde af partitionerede data nulstilles heltalstælleren til 1 for hver partition.
I denne artikel vil vi studere funktionerne RANK, DENSE_RANK og ROW_NUMBER i detaljer, men før det, lad os oprette dummy-data, som disse funktioner kan bruges på, medmindre din database er fuldt sikkerhedskopieret.
Forberedelse af dummy-data
Udfør følgende script for at oprette en database kaldet ShowRoom og indeholdende en tabel kaldet Biler (som indeholder 15 tilfældige registreringer af biler):
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
RANK-funktion
RANK-funktionen bruges til at hente rangerede rækker baseret på betingelsen i ORDER BY-sætningen. For eksempel, hvis du vil finde navnet på bilen med tredje højeste effekt, kan du bruge RANK-funktionen.
Lad os se RANK-funktionen i aktion:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
Scriptet ovenfor finder og rangerer alle posterne i Biler-tabellen og sorterer dem i rækkefølge efter faldende kraft. Outputtet ser således ud:
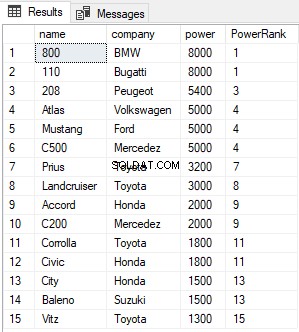
PowerRank-kolonnen i ovenstående tabel indeholder RANK for bilerne sorteret efter faldende rækkefølge efter deres kraft. En interessant ting ved RANK-funktionen er, at hvis der er lighed mellem N tidligere poster for værdien i ORDER BY-kolonnen, springer RANK-funktionerne de næste N-1 positioner over, før tælleren øges. For eksempel er der i ovenstående resultat uafgjort for værdierne i potenskolonnen mellem 1. og 2. række, derfor springer RANK-funktionen over den næste (2-1 =1) en post og hopper direkte til 3. række.
RANK-funktionen kan bruges i kombination med PARTITION BY-sætningen. I så fald vil rangen blive nulstillet for hver ny partition. Tag et kig på følgende script:
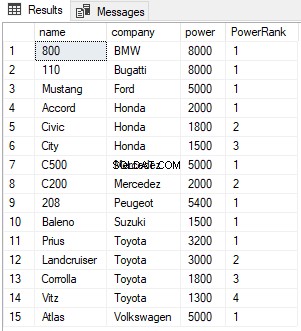
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
I scriptet ovenfor opdeler vi resultaterne efter firmakolonne. For hver virksomhed vil RANK blive nulstillet til 1 som vist nedenfor:
DENSE_RANK-funktion
Funktionen DENSE_RANK ligner RANK-funktionen, men funktionen DENSE_RANK springer ikke over nogen rækker, hvis der er uafgjort mellem rækkerne af de foregående poster. Tag et kig på følgende script.
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
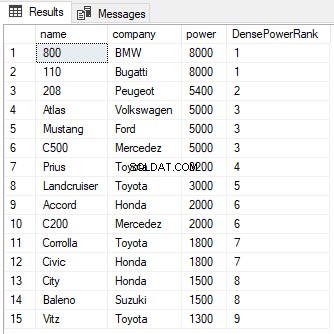
Du kan se på outputtet, at på trods af at der er uafgjort mellem rækkerne af de to første rækker, springes den næste rang ikke over og er blevet tildelt en værdi på 2 i stedet for 3. Som med RANK-funktionen kan PARTITION BY-sætningen også bruges med DENSE_RANK-funktionen som vist nedenfor:
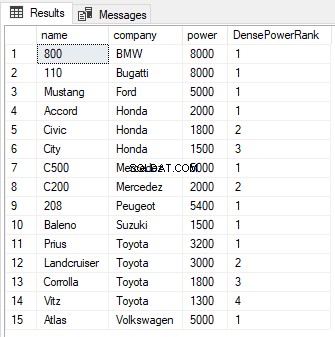
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
ROW_NUMBER funktion
I modsætning til funktionerne RANK og DENSE_RANK returnerer funktionen ROW_NUMBER ganske enkelt rækkenummeret for de sorterede poster, der starter med 1. Hvis f.eks. funktionerne RANK og DENSE_RANK i de to første poster i kolonnen ORDER BY er ens, tildeles begge 1 som deres RANK og DENSE_RANK. Funktionen ROW_NUMBER vil dog tildele værdierne 1 og 2 til disse rækker uden at tage det faktum, at der tages lige højde for dem. Udfør følgende script for at se funktionen ROW_NUMBER i aktion.
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
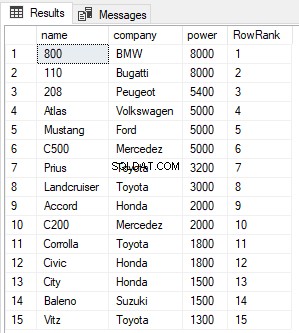
Fra outputtet kan du se, at ROW_NUMBER-funktionen simpelthen tildeler et nyt rækkenummer til hver post, uanset dens værdi.
PARTITION BY-sætningen kan også bruges med ROW_NUMBER-funktionen som vist nedenfor:
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
Outputtet ser således ud:
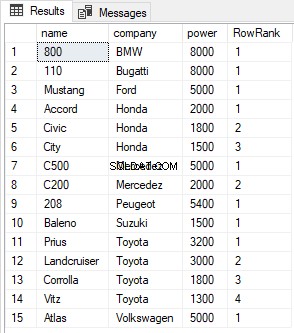
Ligheder mellem funktionerne RANK, DENSE_RANK og ROW_NUMBER
Funktionerne RANK, DENSE_RANK og ROW_NUMBER har følgende ligheder:
1- Alle kræver en rækkefølge efter klausul.
2- Alle returnerer et stigende heltal med en basisværdi på 1.
3- Når de kombineres med en PARTITION BY-klausul, nulstiller alle disse funktioner den returnerede heltalsværdi til 1, som vi har set.
4- Hvis der ikke er nogen duplikerede værdier i kolonnen, der bruges af ORDER BY-sætningen, vil disse funktioner returnerer det samme output.
For at illustrere det sidste punkt, lad os oprette en ny tabel Car1 i ShowRoom-databasen uden duplikerede værdier i potenskolonnen. Udfør følgende script:
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
Outputtet ser således ud:
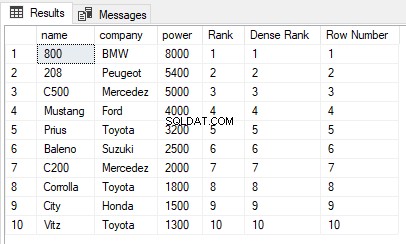
Du kan se, at der ikke er nogen duplikerede værdier i potenskolonnen, som bruges i ORDER BY-sætningen, derfor er outputtet af funktionerne RANK, DENSE_RANK og ROW_NUMBER det samme.
Forskel mellem RANK, DENSE_RANK og ROW_NUMBER funktioner
Den eneste forskel mellem RANK-, DENSE_RANK- og ROW_NUMBER-funktionen er, når der er duplikerede værdier i kolonnen, der bruges i ORDER BY-klausulen.
Hvis du går tilbage til tabellen Biler i ShowRoom-databasen, kan du se, at den indeholder masser af duplikerede værdier. Lad os prøve at finde RANK, DENSE_RANK og ROW_NUMBER i Cars1-tabellen sorteret efter magt. Udfør følgende script:
SELECT name,company, power,
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
Outputtet ser således ud:
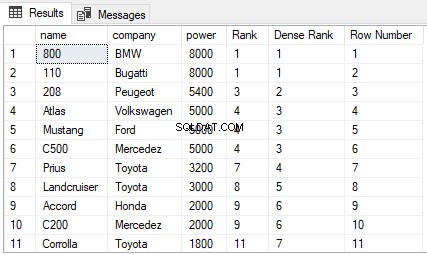
Fra outputtet kan du se, at RANK-funktionen springer de næste N-1 rækker over, hvis der er uafgjort mellem N tidligere rækker. På den anden side springer DENSE_RANK-funktionen ikke over rækker, hvis der er uafgjort mellem rækkerne. Endelig har funktionen ROW_NUMBER ingen bekymringer med rangering. Det returnerer blot rækkenummeret for de sorterede poster. Selvom der er duplikerede poster i kolonnen, der bruges i ORDER BY-sætningen, vil ROW_NUMBER-funktionen ikke returnere duplikerede værdier. I stedet vil den fortsætte med at stige uafhængigt af de duplikerede værdier.
Nyttige links:
For at lære mere om funktionerne ROW_NUMBER(), RANK() og DENSE_RANK() kan du læse den fantastiske artikel af Ahmad Yaseen:
Metoder til at rangere rækker i SQL Server:ROW_NUMBER(), RANK(), DENSE_RANK() og NTILE()