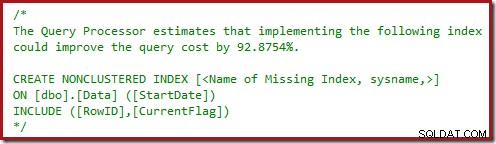
Tilføjelse af et filtreret indeks kan have overraskende bivirkninger på eksisterende forespørgsler, selv hvor det ser ud til, at det nye filtrerede indeks er fuldstændig uafhængigt. Dette indlæg ser på et eksempel, der påvirker DELETE-udsagn, der resulterer i dårlig ydeevne og en øget risiko for dødvande.
Testmiljø
Følgende tabel vil blive brugt i hele dette indlæg:
CREATE TABLE dbo.Data ( RowID integer IDENTITY NOT NULL, SomeValue heltal NOT NULL, StartDate date NOT NULL, CurrentFlag bit NOT NULL, Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10), CONSTRAINT PKID PRIMARY NØGLE KLYNGET (RowID)); Denne næste sætning opretter 499.999 rækker af eksempeldata:
INSERT dbo.Data WITH (TABLOCKX) (SomeValue, StartDate, CurrentFlag)SELECT CONVERT(heltal, RAND(n) * 1e6) % 1000, DATEADD(DAY, (N.n - 1) % 31, '20140101'), KONVERTER(bit, 0)FRA dbo.Number AS NWHERE N.n>=1 OG N.n <500000;
Det bruger en taltabel som en kilde til på hinanden følgende heltal fra 1 til 499.999. Hvis du ikke har en af dem i dit testmiljø, kan følgende kode bruges til effektivt at oprette en, der indeholder heltal fra 1 til 1.000.000:
Med N1 AS (VÆLG N1.n FRA (VÆRDIER (1),(1),(1),(1),(1),(1),(1),(1),(1), (1)) SOM N1 (n)), N2 AS (VÆLG L.n FRA N1 AS L CROSS JOIN N1 AS R), N3 AS (VÆLG L.n FRA N2 AS L CROSS JOIN N2 AS R), N4 AS (VÆLG L.n FRA N3 AS L CROSS JOIN N2 AS R), N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)SELECT -- Destinationskolonnetype heltal NOT NULL ISNULL(CONVERT(heltal, N.n), 0) AS nINTO dbo .Number FRA NOPTION (MAXDOP 1); ÆNDRINGSTABEL dbo.NumbersGrundlaget for de senere tests vil være at slette rækker fra testtabellen for en bestemt Startdato. For at gøre processen med at identificere rækker, der skal slettes mere effektiv, skal du tilføje dette ikke-klyngede indeks:
OPRET IKKE-KLUNGERET INDEKS IX_Data_StartDateON dbo.Data (StartDate);Eksempeldataene
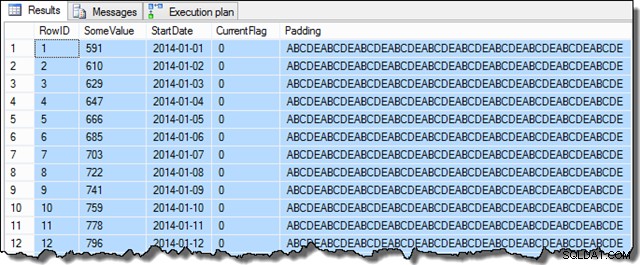
Når disse trin er gennemført, vil prøven se sådan ud:
VÆLG TOP (100) D.RowID, D.SomeValue, D.StartDate, D.CurrentFlag, D.PaddingFROM dbo.Data AS DORDER BY D.RowID;
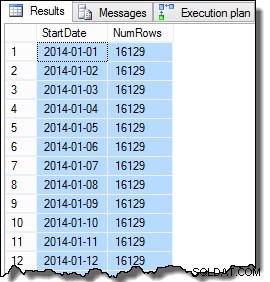
SomeValue-kolonnens data kan være lidt anderledes på grund af den pseudo-tilfældige generation, men denne forskel er ikke vigtig. Samlet set indeholder eksempeldataene 16.129 rækker for hver af de 31 Startdato-datoer i januar 2014:
VÆLG D.StartDate, NumRows =COUNT_BIG(*)FRA dbo.Data AS DGROUP BY D.StartDateORDER BY D.StartDate;
Det sidste trin, vi skal udføre for at gøre dataene noget realistiske, er at indstille CurrentFlag-kolonnen til sand for det højeste RowID for hver startdato. Følgende script udfører denne opgave:
MED LastRowPerDay AS( SELECT D.CurrentFlag FROM dbo.Data AS D WHERE D.RowID =( SELECT MAX(D2.RowID) FROM dbo.Data AS D2 WHERE D2.StartDate =D.StartDate ))UPDATE LastRowPerDaySET CurrentFlag 1;Udførelsesplanen for denne opdatering indeholder en Segment-Top-kombination for effektivt at lokalisere det højeste RowID pr. dag:
Læg mærke til, hvordan udførelsesplanen ikke minder meget om den skriftlige form af forespørgslen. Dette er et godt eksempel på, hvordan optimeringsværktøjet fungerer ud fra den logiske SQL-specifikation i stedet for at implementere SQL direkte. Hvis du undrer dig, er den Ivrige bordspole i den plan påkrævet til Halloween-beskyttelse.
Sletning af en dag med data
Ok, så med de indledende færdigheder, er opgaven at slette rækker for en bestemt startdato. Dette er den slags forespørgsel, du måske rutinemæssigt kører på den tidligste dato i en tabel, hvor dataene har nået slutningen af deres brugstid.
Tager vi 1. januar 2014 som vores eksempel, er testsletningsforespørgslen enkel:
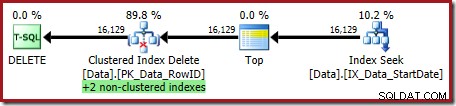
SLET dbo.DataWHERE StartDate ='20140101';Udførelsesplanen er ligeledes ret enkel, dog værd at se lidt detaljeret på:
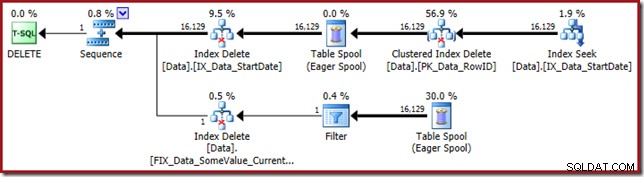
Plananalyse
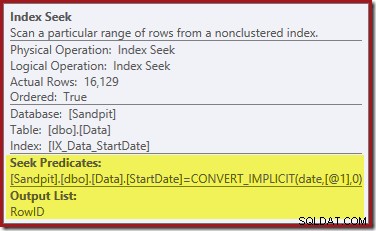
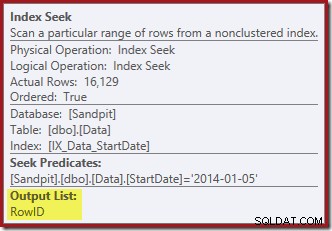
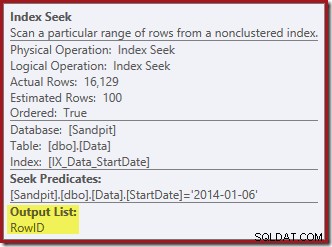
Indekssøgningen yderst til højre bruger det ikke-klyngede indeks til at finde rækker for den angivne startdatoværdi. Den returnerer kun de RowID-værdier, den finder, som operatørværktøjstip bekræfter:
Hvis du undrer dig over, hvordan StartDate-indekset formår at returnere RowID'et, så husk, at RowID er det unikke clustered-indeks for tabellen, så det automatisk inkluderes i StartDate-ikke-clustered-indekset.
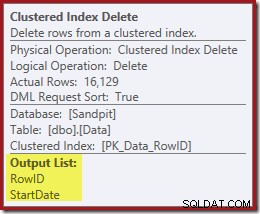
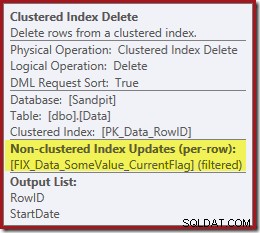
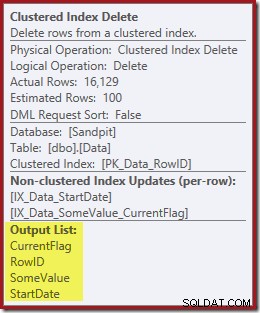
Den næste operatør i planen er Clustered Index Delete. Dette bruger RowID-værdien fundet af Index Seek til at finde rækker, der skal fjernes.
Den sidste operatør i planen er en Index Delete. Dette fjerner rækker fra det ikke-klyngede indeks
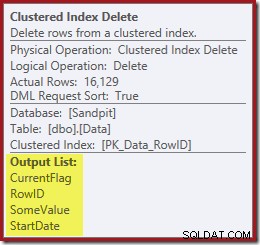
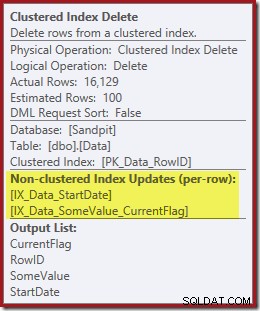
IX_Data_StartDateder er relateret til RowID'et fjernet af Clustered Index Delete. For at finde disse rækker i det ikke-klyngede indeks skal forespørgselsprocessoren have Startdatoen (nøglen til det ikke-klyngede indeks).Husk, at den originale Index Seek ikke returnerede startdatoen, kun RowID. Så hvordan får forespørgselsprocessoren startdatoen for indekssletningen? I dette særlige tilfælde kunne optimeringsværktøjet have bemærket, at StartDate-værdien er en konstant og optimeret den væk, men det er ikke, hvad der skete. Svaret er, at operatoren Clustered Index Delete læser Startdato-værdien for den aktuelle række og tilføjer den til strømmen. Sammenlign outputlisten for Clustered Index Delete vist nedenfor med den for Index Seek lige ovenfor:
Det kan virke overraskende at se en Slet-operatør læse data, men det er sådan det virker. Forespørgselsprocessoren ved, at den bliver nødt til at finde rækken i det klyngede indeks for at slette det, så den kan lige så godt udsætte læsning af kolonner, der er nødvendige for at vedligeholde ikke-klyngede indekser, indtil det tidspunkt, hvis den kan.
Tilføjelse af et filtreret indeks
Forestil dig nu, at nogen har en afgørende forespørgsel mod denne tabel, som klarer sig dårligt. Den hjælpsomme DBA udfører en analyse og tilføjer følgende filtrerede indeks:
OPRET IKKE-KLUSTERET INDEX FIX_Data_SomeValue_CurrentFlagON dbo.Data (SomeValue)INCLUDE (CurrentFlag)WHERE CurrentFlag =1;Det nye filtrerede indeks har den ønskede effekt på den problematiske forespørgsel, og alle er glade. Bemærk, at det nye indeks slet ikke refererer til kolonnen Startdato, så vi forventer slet ikke, at det påvirker vores forespørgsel om sletning af dagen.
Sletning af en dag med det filtrerede indeks på plads
Vi kan teste den forventning ved at slette data for anden gang:
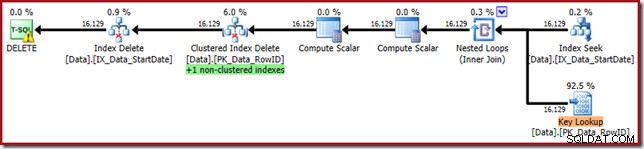
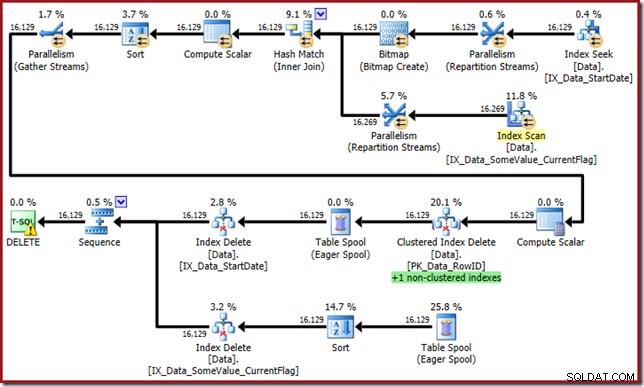
SLET dbo.DataWHERE StartDate ='20140102';Pludselig er udførelsesplanen ændret til en parallel Clustered Index Scan:
Bemærk, at der ikke er nogen separat indeksslet-operator for det nye filtrerede indeks. Optimeringsværktøjet har valgt at bevare dette indeks i operatoren Clustered Index Delete. Dette er fremhævet i SQL Sentry Plan Explorer som vist ovenfor ("+1 ikke-klyngede indekser") med alle detaljer i værktøjstip:
Hvis tabellen er stor (tænk på datavarehus), kan denne ændring til en parallel scanning være meget væsentlig. Hvad skete der med den pæne Index Seek på StartDate, og hvorfor ændrede et fuldstændigt ikke-relateret filtreret indeks tingene så dramatisk?
Sådan finder du problemet
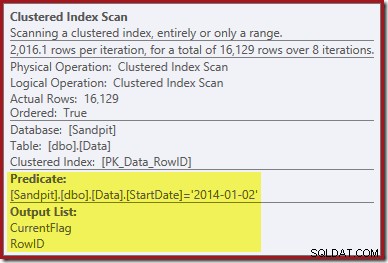
Den første ledetråd kommer fra at se på egenskaberne for Clustered Index Scan:
Ud over at finde RowID-værdier for Clustered Index Delete-operatoren at slette, læser denne operator nu CurrentFlag-værdier. Behovet for denne kolonne er uklart, men det begynder i det mindste at forklare beslutningen om at scanne:CurrentFlag-kolonnen er ikke en del af vores StartDate ikke-klyngede indeks.
Vi kan bekræfte dette ved at omskrive sletteforespørgslen for at tvinge brugen af StartDate ikke-klyngede indeks:
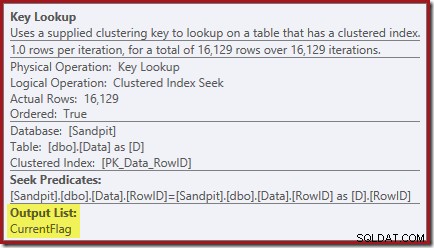
SLET DFROM dbo.Data AS D WITH (INDEX(IX_Data_StartDate))WHERE StartDate ='20140103';Udførelsesplanen er tættere på sin oprindelige form, men den har nu et nøgleopslag:
Nøgleopslagsegenskaberne bekræfter, at denne operatør henter CurrentFlag-værdier:
Du har måske også lagt mærke til advarselstrekanterne i de sidste to planer. Disse mangler indeksadvarsler:
Dette er en yderligere bekræftelse på, at SQL Server gerne vil se CurrentFlag-kolonnen inkluderet i det ikke-klyngede indeks. Årsagen til ændringen til en parallel Clustered Index Scan er nu klar:forespørgselsprocessoren beslutter, at scanning af tabellen vil være billigere end at udføre nøgleopslag.
Ja, men hvorfor?
Det hele er meget underligt. I den oprindelige udførelsesplan var SQL Server i stand til at læse ekstra kolonnedata, der er nødvendige for at vedligeholde ikke-klyngede indekser hos Clustered Index Delete-operatoren. CurrentFlag kolonneværdien er nødvendig for at vedligeholde det filtrerede indeks, så hvorfor håndterer SQL Server det ikke bare på samme måde?
Det korte svar er, at det kan, men kun hvis det filtrerede indeks vedligeholdes i en separat indeksslet-operator. Vi kan tvinge dette til den aktuelle forespørgsel ved hjælp af udokumenteret sporingsflag 8790. Uden dette flag vælger optimeringsværktøjet, om hvert indeks skal vedligeholdes i en separat operator eller som en del af basistabeloperationen.
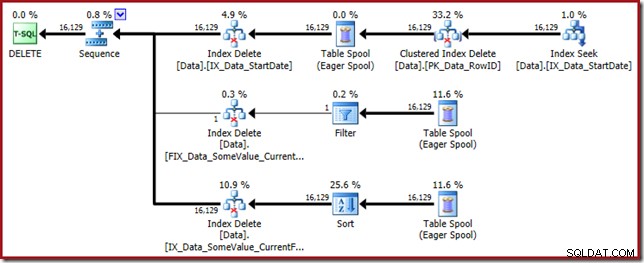
-- Tvunget bred opdateringsplanDELETE dbo.DataWHERE StartDate ='20140105'OPTION (QUERYTRACEON 8790);Udførelsesplanen er tilbage til at søge StartDate ikke-klyngede indeks:
Indekssøgningen returnerer kun RowID-værdier (ingen CurrentFlag):
Og Clustered Index Slet læser de kolonner, der er nødvendige for at vedligeholde de ikke-klyngede indekser, inklusive CurrentFlag:
Disse data skrives ivrigt til en bordspole, som afspilles for hvert indeks, der skal vedligeholdes. Bemærk også den eksplicitte Filter-operator før Index Delete-operatoren for det filtrerede indeks.
Et andet mønster, du skal være opmærksom på
Dette problem resulterer ikke altid i en tabelscanning i stedet for en indekssøgning. For at se et eksempel på dette skal du tilføje endnu et indeks til testtabellen:
OPRET IKKE-KLUSTERET INDEX IX_Data_SomeValue_CurrentFlagON dbo.Data (SomeValue, CurrentFlag);Bemærk, at dette indeks er ikke filtreret og involverer ikke kolonnen Startdato. Prøv nu en dag-slet-forespørgsel igen:
SLET dbo.DataWHERE StartDate ='20140104';Optimizeren kommer nu med dette monster:
Denne forespørgselsplan har en høj overraskelsesfaktor, men årsagen er den samme. Kolonnen CurrentFlag er stadig nødvendig, men nu vælger optimeringsværktøjet en indekskrydsningsstrategi for at få den i stedet for en tabelscanning. Brug af sporingsflaget fremtvinger en vedligeholdelsesplan pr. indeks, og fornuften genoprettes igen (den eneste forskel er en ekstra spole-gentagelse for at vedligeholde det nye indeks):
Kun filtrerede indekser forårsager dette
Dette problem opstår kun, hvis optimeringsværktøjet vælger at opretholde et filtreret indeks i en Clustered Index Delete-operator. Ikke-filtrerede indekser påvirkes ikke, som det følgende eksempel viser. Det første trin er at droppe det filtrerede indeks:
DROP INDEX FIX_Data_SomeValue_CurrentFlagON dbo.Data;Nu skal vi skrive forespørgslen på en måde, der overbeviser optimeringsværktøjet til at vedligeholde alle indekserne i Clustered Index Delete. Mit valg til dette er at bruge en variabel og et hint til at sænke optimizerens forventninger til rækkeantal:
-- Alle kvalificerende rækker vil blive slettetDECLARE @Rows bigint =9223372036854775807; -- Optimer planen for sletning af 100 rækker DELETE TOP (@Rows)FROM dbo.DataOUTPUT Deleted.RowID, Deleted.SomeValue, Deleted.StartDate, Deleted.CurrentFlagWHERE StartDate ='20140106'OPTION (@00S FOR);Udførelsesplanen er:
Begge ikke-klyngede indekser vedligeholdes af Clustered Index Delete:
Indekssøgningen returnerer kun RowID:
De kolonner, der er nødvendige for indeksvedligeholdelsen, hentes internt af sletteoperatøren; disse detaljer er ikke eksponeret i vis plan output (så outputlisten for sletoperatøren ville være tom). Jeg tilføjede en
OUTPUTklausul til forespørgslen for at vise Clustered Index Delete endnu en gang returnerende data, den ikke modtog på sit input:
Sidste tanker
Dette er en vanskelig begrænsning at omgå. På den ene side ønsker vi generelt ikke at bruge udokumenterede sporingsflag i produktionssystemer.
Den naturlige 'fix' er at tilføje de kolonner, der er nødvendige for filtreret indeksvedligeholdelse, til alle ikke-klyngede indekser, der kan bruges til at finde rækker, der skal slettes. Dette er ikke et særligt tiltalende forslag, set fra en række synspunkter. Et andet alternativ er slet ikke at bruge filtrerede indekser, men det er næppe heller ideelt.
Min fornemmelse er, at forespørgselsoptimeringsværktøjet burde overveje et vedligeholdelsesalternativ pr. indeks for filtrerede indekser automatisk, men dens begrundelse ser ud til at være ufuldstændig på dette område lige nu (og baseret på simple heuristikker snarere end korrekt pris pr. indeks/pr. række). alternativer).
For at sætte nogle tal omkring det udsagn kom den parallelle klyngede indeksscanningsplan valgt af optimeringsværktøjet på 5.5 enheder i mine tests. Den samme forespørgsel med sporingsflaget anslår en pris på 1,4 enheder. Med det tredje indeks på plads havde planen for parallelle indekskryds, valgt af optimeringsværktøjet, en anslået pris på 4,9 , hvorimod sporingsflagsplanen kom ind på 2,7 enheder (alle test på SQL Server 2014 RTM CU1 build 12.0.2342 under 120 kardinalitet estimeringsmodellen og med sporingsflag 4199 aktiveret).
Jeg betragter dette som en adfærd, der bør forbedres. Du kan stemme for at være enig eller uenig med mig i dette Connect-emne.