Brug af et multi-sky- eller multi-datacenter-miljø er nyttigt til geo-distribuerede topologier eller endda til en katastrofe-genopretningsplan, og faktisk bliver det mere populært i dag, derfor er konceptet split-brain bliver også vigtigere, da risikoen for at få den øget i denne form for scenarie. Du skal forhindre en split-brain for at undgå potentielt datatab eller datainkonsistens, hvilket kan være et stort problem for virksomheden.
I denne blog vil vi se, hvad en split-brain er, og hvordan ClusterControl kan hjælpe dig med at undgå dette vigtige problem.
Hvad er Split-Brain?
I PostgreSQL-verdenen opstår split-brain, når mere end én primær node er tilgængelig på samme tid (uden noget tredjepartsværktøj til at have et multi-master-miljø), der tillader applikationen at skrive i begge noder. I dette tilfælde vil du have forskellige oplysninger om hver node, hvilket genererer datainkonsistens i klyngen. Det kan være svært at løse dette problem, da du skal flette data, noget som nogle gange ikke er muligt.
PostgreSQL split-hjerne i en multi-sky-topologi
Lad os antage, at du har følgende multi-cloud-topologi til PostgreSQL (som er en ret almindelig topologi i dag):
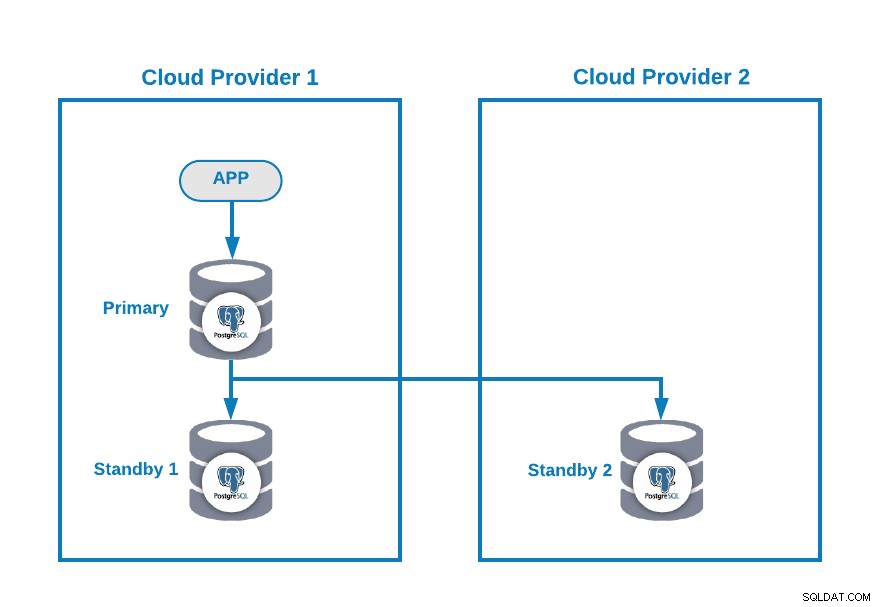
Selvfølgelig kan du forbedre dette miljø ved f.eks. at tilføje en Application Server i Cloud Provider 2, men i dette tilfælde, lad os bruge denne grundlæggende konfiguration.
Hvis din primære node er nede, bør en af standby-knuderne promoveres som en ny primær, og du skal ændre IP-adressen i din applikation for at bruge denne nye primære node.
Der er forskellige måder at gøre dette på automatisk. For eksempel kan du bruge en virtuel IP-adresse, der er tildelt din primære node, og overvåge den. Hvis det mislykkes, skal du fremme en af standby-knuderne og migrere den virtuelle IP-adresse til denne nye primære node, så du ikke behøver at ændre noget i din applikation, og dette kan laves ved hjælp af dit eget script eller værktøj.
I øjeblikket har du ikke noget problem, men... hvis din gamle primære node kommer tilbage, skal du sikre dig, at du ikke har to primære noder i samme klynge på samme tid .
De mest almindelige metoder til at undgå denne situation er:
- STONITH:Skyd den anden knude i hovedet.
- SMITH:Skyd mig selv i hovedet.
PostgreSQL giver ingen mulighed for at automatisere denne proces. Du skal lave det på egen hånd.
Sådan undgår du split-hjerne i PostgreSQL med ClusterControl
Lad os nu se, hvordan ClusterControl kan hjælpe dig med denne opgave.
For det første kan du bruge det til at implementere eller importere dit PostgreSQL Multi-Cloud-miljø på en nem måde, som du kan se i dette blogindlæg.
Derefter kan du forbedre din topologi ved at tilføje en Load Balancer (HAProxy), som du også kan gøre ved at bruge ClusterControl efter denne blog. Så du vil have noget som dette:
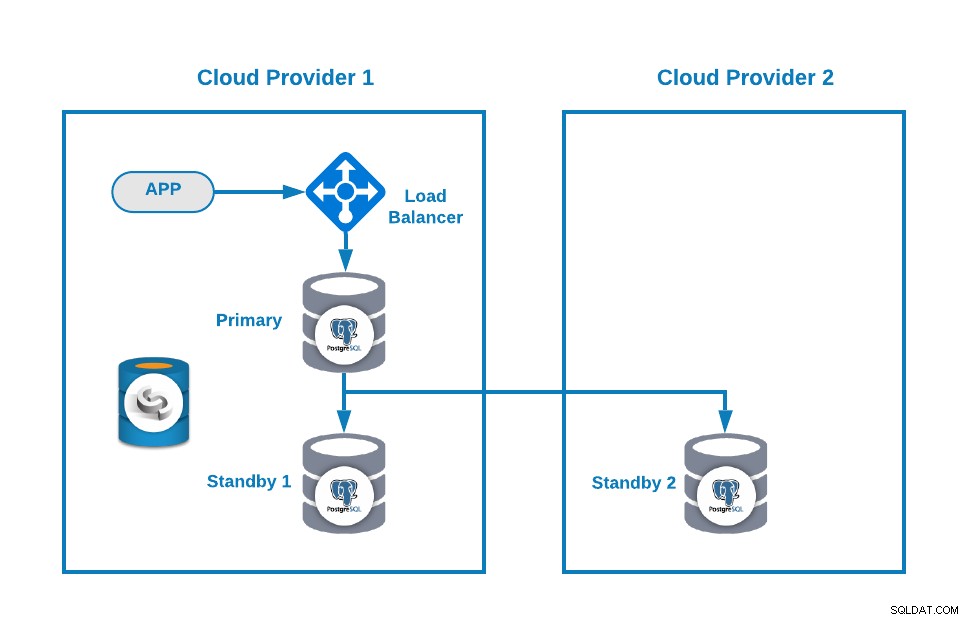
ClusterControl har en auto-failover-funktion, der registrerer masterfejl og fremmer standby node med de mest aktuelle data som ny primær. Det mislykkes også over resten af standby-knuderne med at replikere fra den nye primære knude.
HAProxy er konfigureret af ClusterControl med to forskellige porte som standard, en læse-skrive og en skrivebeskyttet. I read-write-porten har du din primære node som online og resten af dine noder som offline, og i read-only-porten har du både den primære og standby node online. På denne måde kan du afbalancere læsetrafikken mellem dine noder, men du sørger for, at i skrivende stund vil læse-skrive-porten blive brugt, og skrive i den primære node, som er den server, der er online.
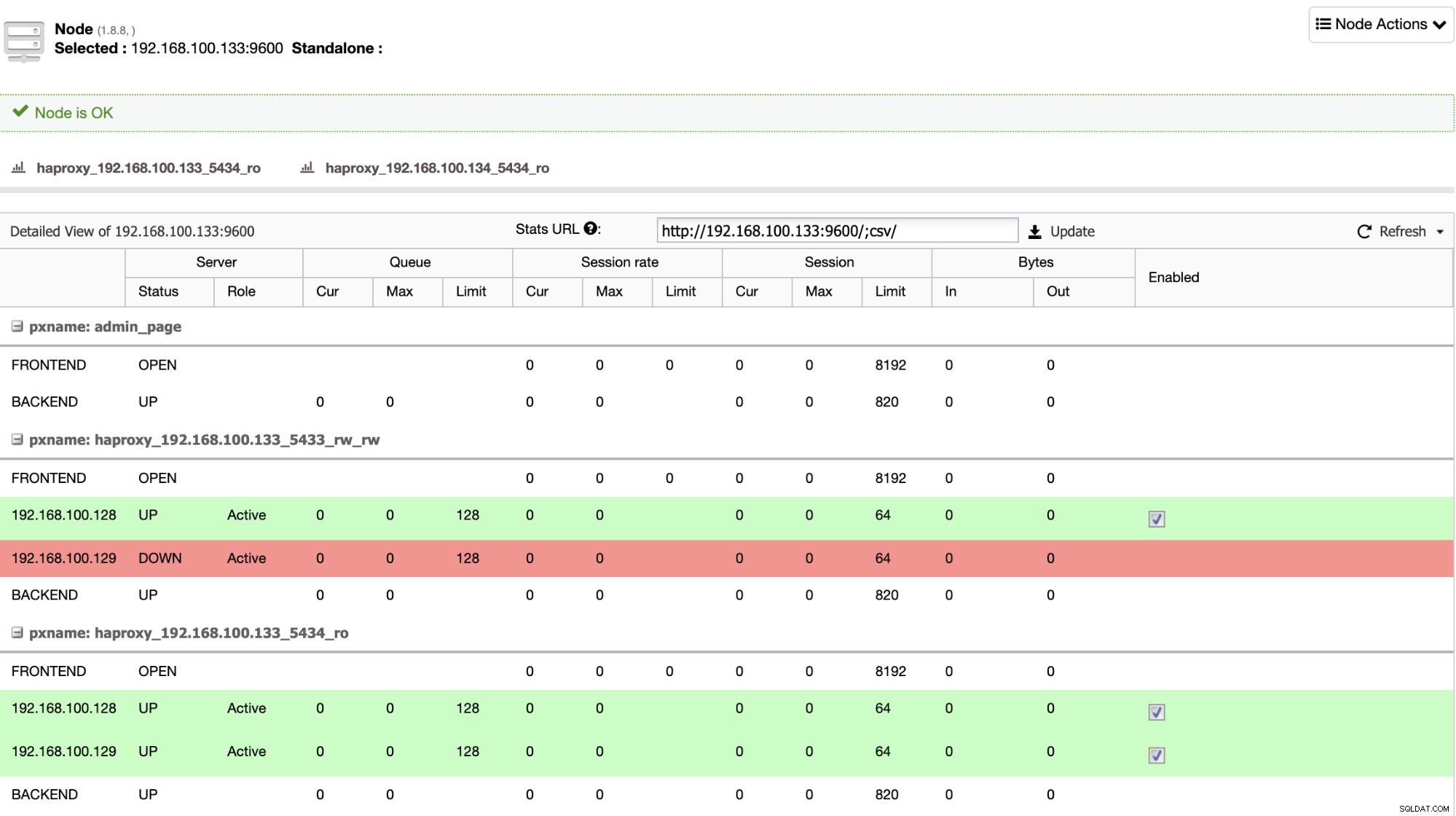
Når HAProxy registrerer, at en af dine noder, enten primær eller standby, er ikke tilgængelig, markerer den den automatisk som offline og tager den ikke i betragtning for at sende trafik til den. Denne kontrol udføres af sundhedstjekscripts, der er konfigureret af ClusterControl på tidspunktet for implementeringen. Disse kontrollerer, om forekomsterne er oppe, om de er under gendannelse eller er skrivebeskyttede.
Hvis din gamle primære node kommer tilbage, vil ClusterControl også undgå at starte den, for at forhindre en potentiel split-brain, hvis du har en direkte forbindelse, der ikke bruger Load Balancer, men du kan tilføje den til klyngen som en standby-knude på en automatisk eller manuel måde ved hjælp af ClusterControl UI eller CLI, så kan du fremme den til at have den samme topologi, som du kørte før problemet.
Konklusion
Har "Autorecovery"-indstillingen aktiveret, vil ClusterControl udføre denne automatiske failover samt give dig besked om problemet. På denne måde kan dine systemer genoprette sig på få sekunder uden din indgriben, og du vil undgå en split-hjerne i et PostgreSQL Multi-Cloud-miljø.
Du kan også forbedre dit High Availability-miljø ved at tilføje flere ClusterControl-noder ved hjælp af CMON HA-funktionen beskrevet i denne blog.