Alle moderne databasesystemer understøtter et Query Optimizer-modul til automatisk at identificere den mest effektive strategi til at udføre SQL-forespørgslerne. Den effektive strategi kaldes "Plan", og den måles i form af omkostninger, som er direkte proportional med "Forespørgselsudførelse/svartid". Planen er repræsenteret i form af et træoutput fra Query Optimizer. Plantræsknuderne kan hovedsageligt opdeles i følgende 3 kategorier:
- Scan noder :Som forklaret i min tidligere blog "En oversigt over de forskellige scanningsmetoder i PostgreSQL", angiver det, hvordan en basistabeldata skal hentes.
- Tilslut dig noder :Som forklaret i min tidligere blog "En oversigt over JOIN-metoderne i PostgreSQL", angiver det, hvordan to tabeller skal slås sammen for at få resultatet af to tabeller.
- Materialiseringsknuder :Kaldes også som hjælpeknuder. De foregående to slags noder var relateret til, hvordan man henter data fra en basistabel, og hvordan man forbinder data hentet fra to tabeller. Noderne i denne kategori påføres oven på data hentet for yderligere at analysere eller udarbejde rapport osv. f.eks. Sortering af data, aggregering af data osv.
Overvej et simpelt forespørgselseksempel såsom...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Antag, at en plan genereret svarende til forespørgslen som nedenfor:
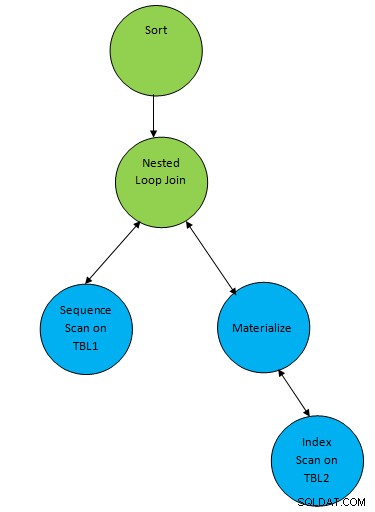
Så her er én hjælpeknude "Sorter" tilføjet oven på resultatet af join for at sortere dataene i den påkrævede rækkefølge.
Nogle af hjælpeknuderne, der genereres af PostgreSQL-forespørgselsoptimeringsværktøjet, er som nedenfor:
- Sortér
- Samlet
- Gruppér efter samlet
- Grænse
- Unik
- LockRows
- SetOp
Lad os forstå hver enkelt af disse noder.
Sortér
Som navnet antyder, tilføjes denne node som en del af et plantræ, når der er behov for sorterede data. Sorterede data kan kræves eksplicit eller implicit som nedenfor to tilfælde:
Brugerscenariet kræver sorterede data som output. I dette tilfælde kan sorteringsnoden være oven på hentning af hele data inklusive al anden behandling.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Bemærk: Selvom brugeren krævede det endelige output i sorteret rækkefølge, kan sorteringsnoden ikke tilføjes i den endelige plan, hvis der er et indeks på den tilsvarende tabel og sorteringskolonne. I dette tilfælde kan den vælge indeksscanning, som vil resultere i implicit sorteret rækkefølge af data. Lad os for eksempel oprette et indeks på ovenstående eksempel og se resultatet:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Som forklaret i min tidligere blog En oversigt over JOIN-metoderne i PostgreSQL kræver Merge Join, at begge tabeldata sorteres, før de tilsluttes. Så det kan ske, at Merge Join viste sig at være billigere end nogen anden joinmetode, selv med en ekstra omkostning ved sortering. Så i dette tilfælde vil sorteringsnode blive tilføjet mellem join- og scanningsmetode for tabellen, så sorterede poster kan videregives til join-metoden.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Samlet
Aggregeret node tilføjes som en del af et plantræ, hvis der er en aggregeret funktion, der bruges til at beregne enkelte resultater fra flere inputrækker. Nogle af de anvendte aggregerede funktioner er COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) og MIN (MINIMUM).
En aggregeret node kan komme oven på en basisrelationsscanning eller (og) ved sammenføjning af relationer. Eksempel:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Denne slags noder er udvidelser af "Aggregate"-knuden. Hvis aggregerede funktioner bruges til at kombinere flere inputrækker i henhold til deres gruppe, tilføjes disse slags noder til et plantræ. Så hvis forespørgslen har en brugt samlet funktion, og sammen med det er der en GROUP BY-klausul i forespørgslen, så vil enten HashAggregate eller GroupAggregate node blive tilføjet til plantræet.
Da PostgreSQL bruger Cost Based Optimizer til at generere et optimalt plantræ, er det næsten umuligt at gætte, hvilke af disse noder der vil blive brugt. Men lad os forstå, hvornår og hvordan det bliver brugt.
HashAggregate
HashAggregate fungerer ved at bygge hash-tabellen over dataene for at gruppere dem. Så HashAggregate kan bruges af gruppeniveau, hvis sammenlægningen sker på usorteret datasæt.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Her er demo1 tabelskemadataene som i eksemplet vist i det foregående afsnit. Da der kun er 1000 rækker at gruppere, så er den nødvendige ressource til at bygge en hash-tabel mindre end prisen på sortering. Forespørgselsplanlæggeren beslutter at vælge HashAggregate.
GroupAggregate
GroupAggregate fungerer på sorterede data, så det kræver ingen yderligere datastruktur. GroupAggregate kan bruges af gruppeniveau, hvis aggregeringen er på sorteret datasæt. For at gruppere på sorterede data kan den enten eksplicit sortere (ved at tilføje sorteringsknude), eller den kan fungere på data hentet efter indeks, i hvilket tilfælde det er implicit sorteret.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Her er demo2-tabelskemadataene som i eksemplet vist i forrige afsnit. Da der her er 100.000 rækker at gruppere, så den nødvendige ressource til at bygge hash-tabel kan være dyrere end prisen på sortering. Så forespørgselsplanlæggeren beslutter at vælge GroupAggregate. Bemærk her, at posterne valgt fra "demo2"-tabellen er eksplicit sorteret, og for hvilke der er tilføjet en node i plantræet.
Se et andet eksempel nedenfor, hvor allerede data hentes sorteret på grund af indeksscanning:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Se et eksempel mere nedenfor, som selvom det har Index Scan, stadig skal sorteres eksplicit som den kolonne, hvor indekset der og grupperingskolonnen ikke er det samme. Så stadig skal den sorteres i henhold til grupperingskolonnen.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Bemærk: GroupAggregate/HashAggregate kan bruges til mange andre indirekte forespørgsler, selvom aggregering med gruppe ikke er der i forespørgslen. Det afhænger af, hvordan planlæggeren fortolker forespørgslen. For eksempel. Lad os sige, at vi skal have en særskilt værdi fra tabellen, så kan den ses som en gruppe af den tilsvarende kolonne og derefter tage en værdi fra hver gruppe.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Så her bliver HashAggregate brugt, selvom der ikke er nogen aggregering og gruppe involveret.
Grænse
Grænseknuder tilføjes til plantræet, hvis "limit/offset"-sætningen bruges i SELECT-forespørgslen. Denne klausul bruges til at begrænse antallet af rækker og eventuelt give en offset for at begynde at læse data. Eksempel nedenfor:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Unik
Denne node bliver valgt for at få en særskilt værdi fra det underliggende resultat. Bemærk, at afhængigt af forespørgslen, selektiviteten og andre ressourceoplysninger, kan den distinkte værdi hentes ved hjælp af HashAggregate/GroupAggregate også uden brug af Unique node. Eksempel:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL giver funktionalitet til at låse alle valgte rækker. Rækker kan vælges i en "Delt" tilstand eller "Eksklusiv" tilstand afhængigt af henholdsvis "FOR SHARE" og "FOR UPDATE" klausulen. En ny node "LockRows" føjes til plantræet for at opnå denne operation.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL giver funktionalitet til at kombinere resultaterne af to eller flere forespørgsler. Så efterhånden som typen af Join node bliver valgt til at forbinde to tabeller, bliver en lignende type SetOp node valgt til at kombinere resultaterne af to eller flere forespørgsler. Overvej for eksempel en tabel med medarbejdere med deres id, navn, alder og deres løn som nedenfor:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Lad os nu få medarbejdere med en alder på over 25 år:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Lad os nu få medarbejdere med en løn på mere end 95 mio.:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)For nu at få medarbejdere med en alder på over 25 år og en løn på mere end 95 mio., kan vi skrive nedenstående krydsforespørgsel:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Så her er en ny slags node HashSetOp tilføjet for at evaluere skæringspunktet mellem disse to individuelle forespørgsler.
Bemærk, at der er tilføjet to andre slags nye noder her:
Tilføj
Denne node tilføjes for at kombinere flere resultater sat til én.
Scanning af underforespørgsler
Denne node tilføjes for at evaluere enhver underforespørgsel. I ovenstående plan tilføjes underforespørgslen for at evaluere en ekstra konstant kolonneværdi, som angiver, hvilket inputsæt der bidrog med en specifik række.
HashedSetop arbejder ved at bruge hashen af det underliggende resultat, men det er muligt at generere sorteringsbaseret SetOp-operation af forespørgselsoptimeringsværktøjet. Sorteringsbaseret Setop-knude er angivet som "Setop".
Bemærk:Det er muligt at opnå det samme resultat som vist i ovenstående resultat med en enkelt forespørgsel, men her er det vist ved hjælp af intersect for en nem demonstration.
Konklusion
Alle noder i PostgreSQL er nyttige og bliver udvalgt baseret på arten af forespørgslen, data osv. Mange af klausulerne er kortlagt én til én med noder. For nogle klausuler er der flere muligheder for noder, som bliver besluttet baseret på de underliggende dataomkostningsberegninger.