Failover er et systems evne til at fortsætte med at arbejde, selvom der opstår en fejl. Det antyder, at systemets funktioner overtages af sekundære komponenter, hvis de primære komponenter svigter, eller hvis det er nødvendigt. Så hvis du oversætter det til et PostgreSQL multi-cloud-miljø, betyder det, at når din primære node fejler (eller en anden grund, som vi vil nævne i næste afsnit) i din primære cloud-udbyder, skal du være i stand til at fremme standby-noden i den sekundære for at holde systemerne kørende.
Generelt giver alle cloud-udbydere dig en failover-mulighed i den samme cloud-udbyder, men det kan være muligt, at du har brug for failover til en anden anden cloud-udbyder. Selvfølgelig kan du gøre det manuelt, men du kan også bruge nogle af ClusterControl-funktionerne som auto-failover eller fremme slavehandling for at gøre dette på en venlig og nem måde.
I denne blog vil du se, hvorfor du skal have failover, hvordan du gør det manuelt, og hvordan du bruger ClusterControl til denne opgave. Vi antager, at du har en ClusterControl-installation kørende og allerede har oprettet din databaseklynge i to forskellige cloud-udbydere.
Hvad bruges failover til?
Der er flere mulige anvendelser af failover.
Masterfejl
Hvis din primære node er nede, eller selvom din primære cloud-udbyder har nogle problemer, skal du failover for at sikre, at dit system er tilgængeligt. I dette tilfælde kan det være nødvendigt at have en automatisk måde at gøre dette på for at mindske nedetiden.
Migrering
Hvis du vil migrere dine systemer fra en cloud-udbyder til en anden ved at minimere din nedetid, kan du bruge failover. Du kan oprette en replika i den sekundære Cloud Provider, og når den er synkroniseret, skal du stoppe dit system, promovere din replika og failover, før du peger dit system til den nye primære node i den sekundære Cloud Provider.
Vedligeholdelse
Hvis du skal udføre en vedligeholdelsesopgave på din PostgreSQL primære node, kan du promovere din replika, udføre opgaven og genopbygge din gamle primære som en standby-node.
Herefter kan du promovere den gamle primære og gentage genopbygningsprocessen på standby-knuden og vende tilbage til den oprindelige tilstand.
På denne måde kan du arbejde på din server uden at risikere at være offline eller miste information, mens du udfører en vedligeholdelsesopgave.
Opgraderinger
Det er muligt at opgradere din PostgreSQL-version (siden PostgreSQL 10) eller endda opgradere dit operativsystem ved hjælp af logisk replikering uden nedetid, da det kan gøres med andre motorer.
Trinnene ville være de samme som at migrere til en ny cloud-udbyder, kun at din replika ville være i en nyere PostgreSQL- eller OS-version, og du skal bruge logisk replikering, da du ikke kan bruge streaming replikering mellem forskellige versioner.
Failover handler ikke kun om databasen, men også applikationen. Hvordan ved de, hvilken database de skal oprette forbindelse til? Du ønsker sandsynligvis ikke at skulle ændre din applikation, da dette kun vil forlænge din nedetid, så du kan konfigurere en Load Balancer, som automatisk vil pege på den server, der blev promoveret, når din primære node er nede.
At have en enkelt Load Balancer-instans er ikke den bedste mulighed, da det kan blive et enkelt fejlpunkt. Derfor kan du også implementere failover til Load Balancer ved at bruge en service som Keepalved. På denne måde, hvis du har et problem med din primære Load Balancer, vil Keepalived migrere den virtuelle IP til din sekundære Load Balancer, og alt fortsætter med at fungere gennemsigtigt.
En anden mulighed er brugen af DNS. Ved at promovere standby-knuden i den sekundære cloud-udbyder, ændrer du direkte hostnavnets IP-adresse, der peger på den primære node. På denne måde slipper du for at skulle ændre din applikation, og selvom det ikke kan gøres automatisk, er det et alternativ, hvis du ikke ønsker at implementere en Load Balancer.
Sådan failover PostgreSQL manuelt
Før du udfører en manuel failover, skal du kontrollere replikeringsstatussen. Det kan være muligt, at når du skal failover, er standby-knuden ikke opdateret på grund af en netværksfejl, høj belastning eller et andet problem, så du skal sikre dig, at din standby-knude har alt (eller næsten alle) oplysningerne. Hvis du har mere end én standby-knude, bør du også tjekke, hvilken der er den mest avancerede node og vælge den til failover.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Når du vælger den nye primære node, kan du først køre kommandoen pg_lsclusters for at få klyngeoplysningerne:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logSå skal du bare køre kommandoen pg_ctlcluster med promoveringshandlingen:
$ pg_ctlcluster 12 main promoteI stedet for den forrige kommando kan du køre kommandoen pg_ctl på denne måde:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedDerefter vil din standby node blive forfremmet til primær, og du kan validere den ved at køre følgende forespørgsel i din nye primære node:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Hvis resultatet er "f", er det din nye primære node.
Nu skal du ændre den primære database-IP-adresse i din applikation, Load Balancer, DNS eller den implementering, du bruger, hvilket, som vi nævnte, vil øge nedetiden ved at ændre dette manuelt. Du skal også sikre dig, at din forbindelse mellem kundeudbyderne fungerer korrekt, applikationen kan få adgang til den nye primære node, applikationsbrugeren har rettigheder til at få adgang til den fra en anden cloududbyder, og du bør genopbygge standbyknudepunkterne i fjernbetjeningen eller endda i den lokale cloud-udbyder for at replikere fra den nye primære, ellers vil du ikke have en ny failover-mulighed, hvis det er nødvendigt.
Sådan failover PostgreSQL ved hjælp af ClusterControl
ClusterControl har en række funktioner relateret til PostgreSQL-replikering og automatiseret failover. Vi antager, at du har din ClusterControl-server installeret, og at den administrerer dit Multi-Cloud PostgreSQL-miljø.
Med ClusterControl kan du tilføje lige så mange standby-noder eller Load Balancer-noder, som du har brug for, uden nogen netværks-IP-begrænsning. Det betyder, at det ikke er nødvendigt, at standby-knuden er i det samme primære knudenetværk eller endda i den samme cloud-udbyder. Med hensyn til failover giver ClusterControl dig mulighed for at gøre det manuelt eller automatisk.
Manuel failover
For at udføre en manuel failover, skal du gå til ClusterControl -> Vælg Cluster -> Nodes, og i Node Actions for en af dine standby-knuder skal du vælge "Promote Slave".
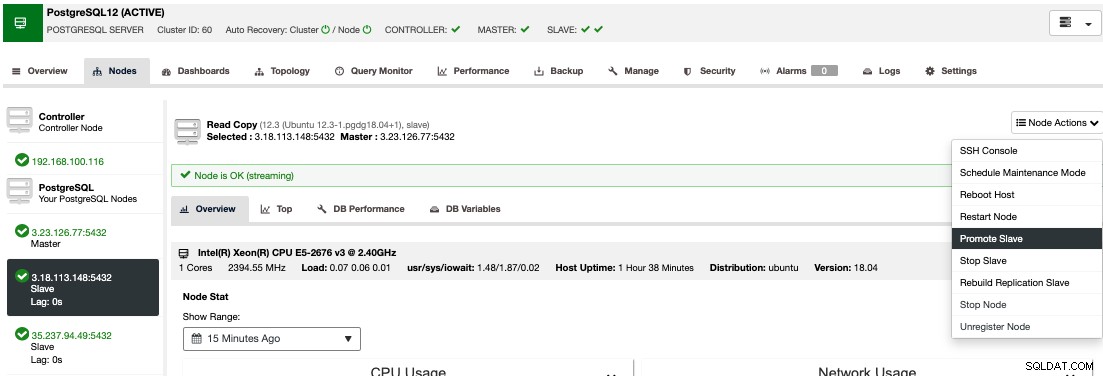
På denne måde bliver din standby-knude efter nogle få sekunder primær, og det, der tidligere var dit primære, er slået til standby. Så hvis din replika var i en anden cloud-udbyder, vil din nye primære node være der og køre.
Automatisk failover
I tilfælde af automatisk failover registrerer ClusterControl fejl i den primære knude og fremmer en standby-knude med de mest aktuelle data som den nye primære. Det virker også på resten af standby-knuderne for at få dem til at replikere fra denne nye primære.

Hvis indstillingen "Autorecovery" er slået TIL, vil ClusterControl udføre en automatisk failover som samt give dig besked om problemet. På denne måde kan dine systemer genoprette på få sekunder og uden din indgriben.
ClusterControl giver dig mulighed for at konfigurere en hvidliste/sortliste for at definere, hvordan du ønsker, at dine servere skal tages i betragtning (eller ikke tages i betragtning), når du beslutter dig for en primær kandidat.
ClusterControl udfører også adskillige kontroller af failover-processen, f.eks. som standard, hvis det lykkes dig at gendanne din gamle mislykkede primære node, vil den ikke automatisk blive genindført i klyngen, hverken som en primær eller som standby skal du gøre det manuelt. Dette vil undgå muligheden for tab af data eller inkonsekvens i tilfælde af, at din standby (som du promoverede) blev forsinket på tidspunktet for fejlen. Du vil måske også analysere problemet i detaljer, men når du føjer det til din klynge, vil du muligvis miste diagnostiske oplysninger.
Load Balancers
Som vi nævnte tidligere, er Load Balancer et vigtigt værktøj at overveje til din failover, især hvis du ønsker at bruge automatisk failover i din databasetopologi.
For at failoveren skal være gennemsigtig for både brugeren og applikationen, skal du have en komponent imellem, da det ikke er nok til at fremme en ny primær node. Til dette kan du bruge HAProxy + Keepalved.
For at implementere denne løsning med ClusterControl skal du gå til Cluster Actions -> Add Load Balancer -> HAProxy på din PostgreSQL-klynge. Hvis du vil implementere failover for din Load Balancer, skal du konfigurere mindst to HAProxy-forekomster, og derefter kan du konfigurere Keepalived (Cluster Actions -> Add Load Balancer -> Keepalved). Du kan finde flere oplysninger om denne implementering i dette blogindlæg.
Herefter vil du have følgende topologi:

HAProxy er som standard konfigureret med to forskellige porte, en læse-skrive og én skrivebeskyttet.
I læse-skriveporten har du din primære node som online og resten af noderne som offline. I den skrivebeskyttede port har du både den primære og standby-knuden online. På denne måde kan du afbalancere læsetrafikken mellem noderne. Når du skriver, vil læse-skrive-porten blive brugt, som vil pege på den aktuelle primære node.

Når HAProxy registrerer, at en af noderne, enten primær eller standby, er ikke tilgængelig, markerer den automatisk som offline. HAProxy vil ikke sende nogen trafik til det. Denne kontrol udføres af sundhedstjekscripts, der er konfigureret af ClusterControl på tidspunktet for implementeringen. Disse kontrollerer, om forekomsterne er oppe, om de er under gendannelse eller er skrivebeskyttede.
Når ClusterControl fremmer en ny primær node, markerer HAProxy den gamle som offline (for begge porte) og sætter den promoverede node online i læse-skriveporten. På denne måde fortsætter dine systemer med at fungere normalt.
Hvis den aktive HAProxy (som har tildelt en virtuel IP-adresse, som dine systemer opretter forbindelse til) fejler, migrerer Keepalved denne virtuelle IP til den passive HAProxy automatisk. Det betyder, at dine systemer så kan fortsætte med at fungere normalt.
Klynge-til-klynge-replikering i skyen
For at have et Multi-Cloud-miljø kan du bruge ClusterControl Add Slave-handlingen over din PostgreSQL-klynge, men også Cluster-to-Cluster-replikeringsfunktionen. I øjeblikket har denne funktion en begrænsning for PostgreSQL, der tillader dig kun at have én fjernknude, men vi arbejder på at fjerne denne begrænsning snart i en fremtidig udgivelse.
For at implementere det, kan du tjekke afsnittet "Klynge-til-klynge-replikering i skyen" i dette blogindlæg.

Når den er på plads, kan du promovere fjernklyngen, som vil generere en uafhængig PostgreSQL-klynge med en primær node, der kører på den sekundære cloud-udbyder.

Så, hvis du har brug for det, vil du have den samme klynge kørende i en ny cloud-udbyder på få sekunder.
Konklusion
At have en automatisk failover-proces er obligatorisk, hvis du vil have mindre nedetid som muligt, og også brug af forskellige teknologier som HAProxy og Keepalved vil forbedre denne failover.
ClusterControl-funktionerne, som vi nævnte ovenfor, giver dig mulighed for hurtigt at failover mellem forskellige Cloud-udbydere og administrere opsætningen på en nem og venlig måde.
Det vigtigste at tage i betragtning, før du udfører en failover-proces mellem forskellige cloud-udbydere, er forbindelsen. Du skal sikre dig, at din applikation eller dine databaseforbindelser fungerer som normalt ved brug af den primære, men også den sekundære cloud-udbyder i tilfælde af failover, og af sikkerhedsmæssige årsager skal du kun begrænse trafikken fra kendte kilder, så kun mellem skyen Udbydere og ikke tillade det fra nogen ekstern kilde.