Et multi-cloud-miljø er en god mulighed for en Disaster Recovery Plan (DRP), men det kan være en tidskrævende opgave, da du skal konfigurere forbindelsen mellem de forskellige cloud-udbydere, og du vil derefter nødt til at implementere og administrere din databaseklynge to forskellige steder.
I denne blog vil vi vise, hvordan man udfører en multi-cloud-implementering for PostgreSQL i to af de mest populære cloud-udbydere i øjeblikket, AWS og Google Cloud. Til denne opgave vil vi bruge nogle af de funktioner, som ClusterControl kan tilbyde dig, såsom skalering og klynge-til-klynge-replikering.
Vi antager, at du har en ClusterControl-installation kørende og allerede har oprettet to forskellige cloud-udbyderkonti.
Forberedelse af dit cloudmiljø
Først skal du oprette dit miljø i din primære cloud-udbyder. I dette tilfælde vil vi bruge AWS med 2 PostgreSQL-noder:

Sørg for, at du har tilladt SSH- og PostgreSQL-trafik fra din ClusterControl-server ved at redigering af din sikkerhedsgruppe:

Gå derefter til den sekundære Cloud Provider og opret mindst én virtuel maskine det vil være slavenoden. Vi vil bruge Google Cloud Platform med 1 PostgreSQL-node.

Og igen, sørg for, at du tillader SSH- og PostgreSQL-trafik fra din ClusterControl server:

I dette tilfælde tillader vi trafikken uden nogen begrænsning på kilden , men det er kun et eksempel, og det anbefales ikke i det virkelige liv.
Implementer en PostgreSQL-klynge i skyen
Vi vil bruge ClusterControl til denne opgave, så vi antager, at du har den installeret.
Gå til din ClusterControl-server, og vælg indstillingen "Deploy". Hvis du allerede har en PostgreSQL-instans kørende, skal du i stedet vælge "Importér eksisterende server/database".
Når du vælger PostgreSQL, skal du angive bruger, nøgle eller adgangskode og port at forbinde med SSH til dine PostgreSQL-noder. Du skal også bruge navnet på din nye klynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
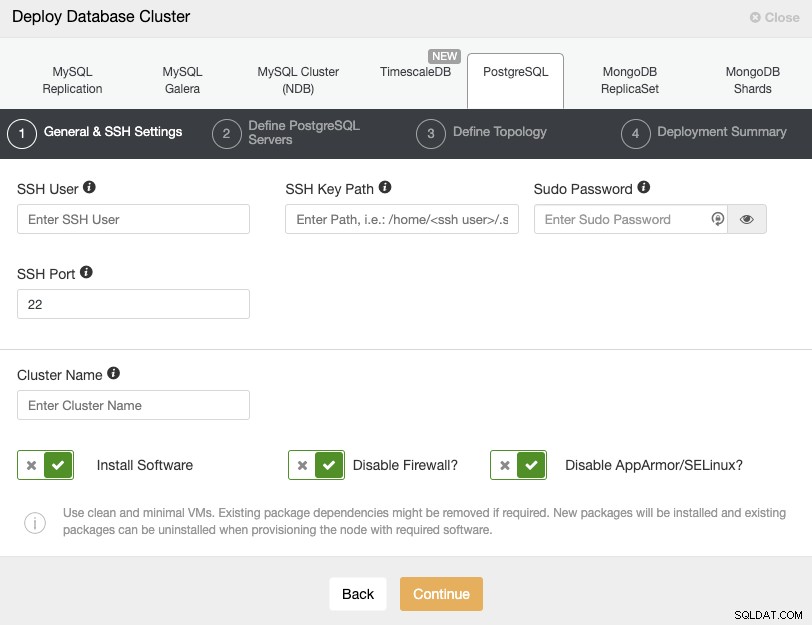
Se venligst ClusterControl-brugerkravene for at få flere oplysninger om dette trin.
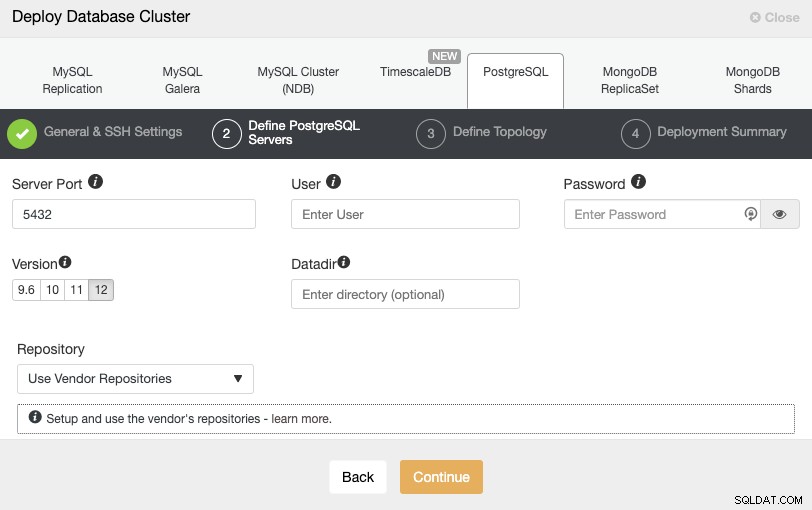
Efter opsætning af SSH-adgangsoplysningerne skal du definere databasebrugeren, version og datadir (valgfrit). Du kan også angive, hvilket lager der skal bruges. I det næste trin skal du tilføje dine servere til den klynge, du vil oprette.
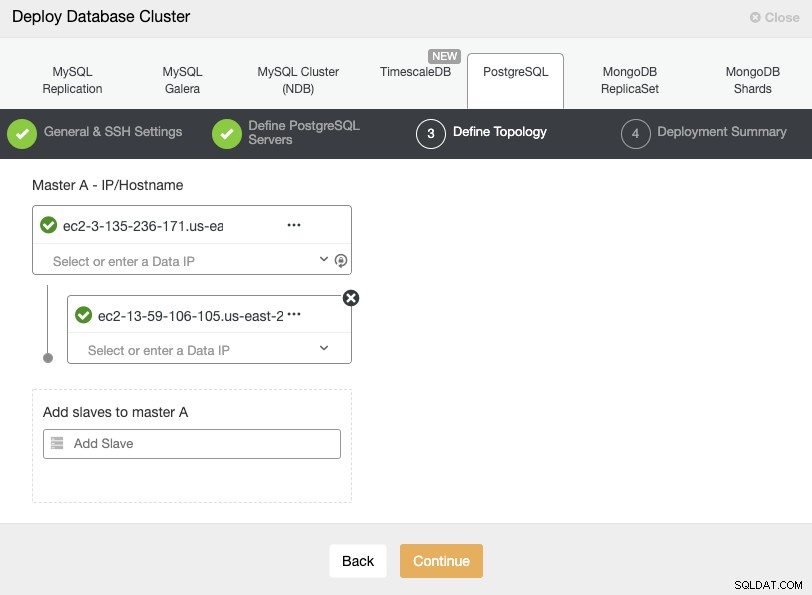
Når du tilføjer dine servere, kan du indtaste IP eller værtsnavn. I dette trin kan du også tilføje noden placeret i den sekundære Cloud Provider, da ClusterControl ikke har nogen begrænsninger for det netværk, der skal bruges, men for at gøre det mere klart, tilføjer vi det i næste afsnit. Det eneste krav her er at have SSH-adgang til noden.
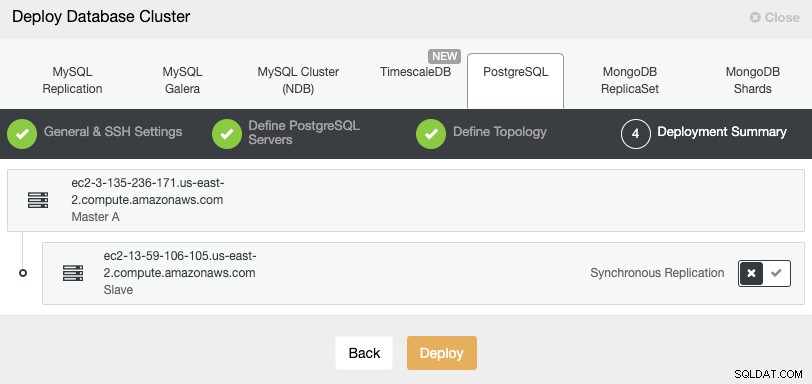
I det sidste trin kan du vælge, om din replikering skal være Synkron eller Asynkron.
Hvis du tilføjer din fjernknude her, er det vigtigt at bruge asynkron replikering, hvis ikke, kan din klynge blive påvirket af latens- eller netværksproblemer.
Du kan overvåge oprettelsesstatus i ClusterControl-aktivitetsmonitoren.
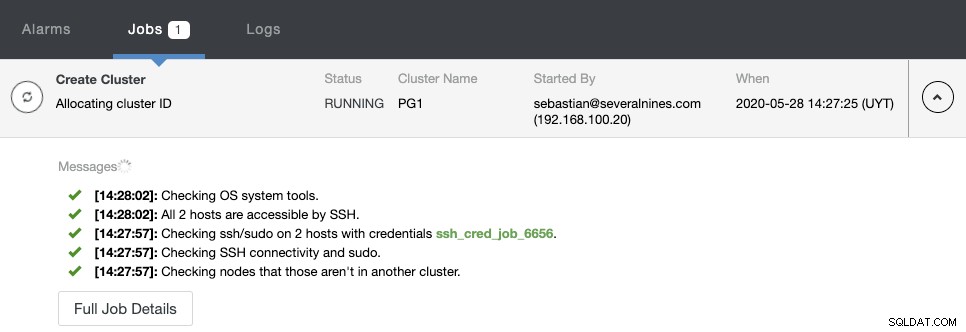
Når opgaven er færdig, kan du se din nye PostgreSQL-klynge i hovedskærmen ClusterControl.

Tilføjelse af en fjernslaveknude i skyen
Når du har oprettet din klynge, kan du udføre flere opgaver på den, f.eks. implementere/importere en belastningsbalancer eller en replikeringsslaveknude.
Gå til klyngehandlinger, og vælg "Tilføj replikeringsslave":
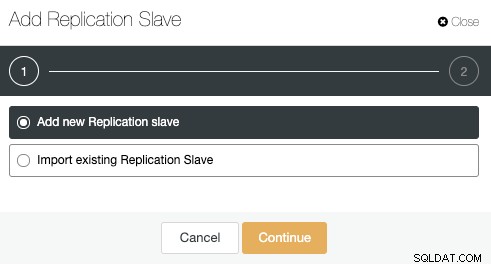
Lad os bruge "Tilføj ny replikeringsslave", da vi antager, at fjernknuden er en ny installation, hvis ikke, kan du bruge "Importer eksisterende replikeringsslave"-indstillingen i stedet.
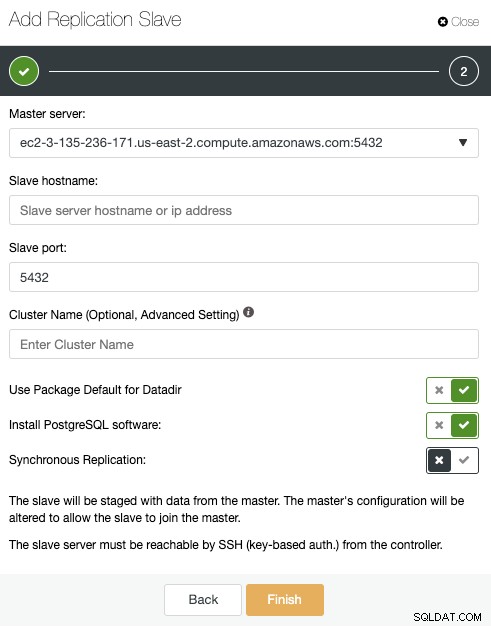
Her skal du kun vælge din masterserver, indtast IP-adressen for din nye slaveserver og databaseporten. Derefter kan du vælge, om du vil have ClusterControl til at installere softwaren, og om replikeringsslaven skal være Synchronous eller Asynchronous. Igen, hvis du tilføjer en node i et andet datacenter, bør du bruge asynkron replikering for at undgå problemer relateret til netværkets ydeevne.
På denne måde kan du tilføje lige så mange replikaer, du vil, og sprede læst trafik mellem dem ved hjælp af en load balancer, som du også kan implementere med ClusterControl.
Du kan overvåge oprettelsen af replikeringsslaven i ClusterControl-aktivitetsmonitoren.
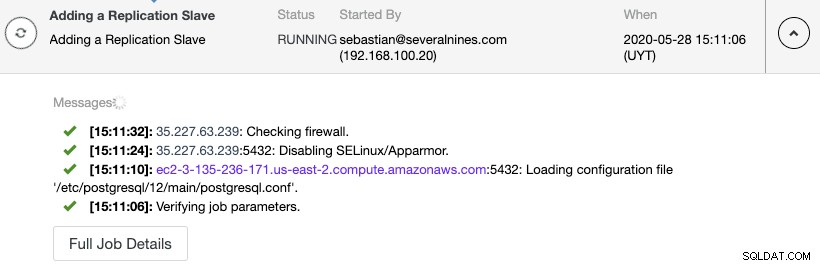
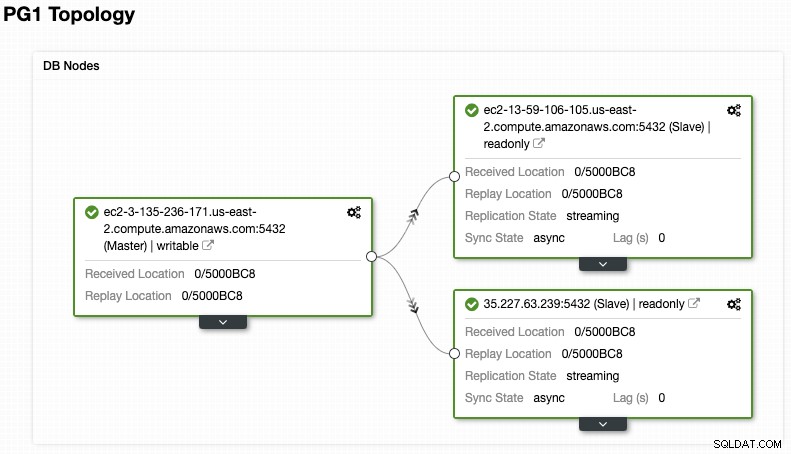
Og tjek din endelige topologi i Topologivisningssektionen.
Klynge-til-klynge-replikering i skyen
I stedet for at bruge muligheden "Tilføj replikeringsslave" til at have et multi-cloud-miljø, kan du bruge ClusterControl Cluster-to-Cluster-replikeringsfunktionen til at tilføje en fjernklynge. I øjeblikket har denne funktion en begrænsning for PostgreSQL, der tillader dig kun at have én fjernknude, så den ligner ret meget på den tidligere måde, men vi arbejder på at fjerne den begrænsning snart i en fremtidig udgivelse.
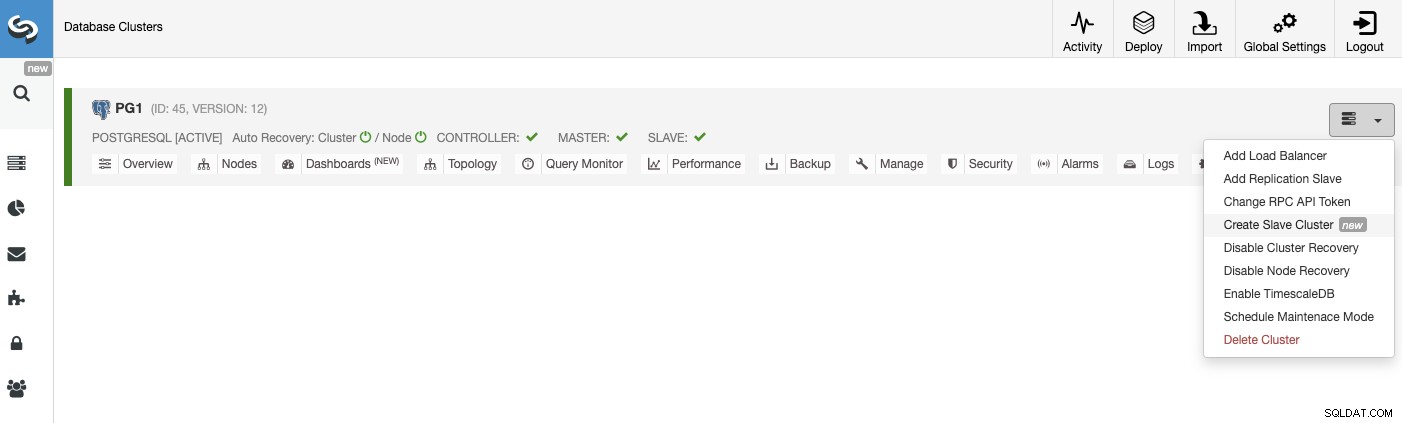
For at oprette en ny slaveklynge skal du gå til ClusterControl -> Vælg Cluster -> Cluster Actions -> Create Slave Cluster.
Slaveklyngen vil blive oprettet ved at streame data fra den aktuelle masterklynge.
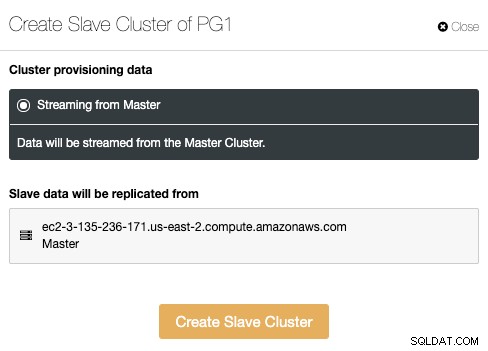
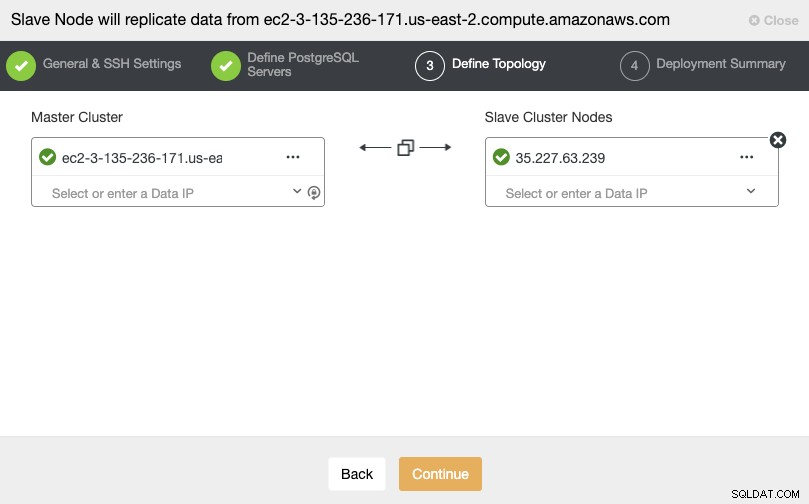
I dette afsnit skal du vælge masterknudepunktet for den aktuelle klynge fra hvor dataene vil blive replikeret.
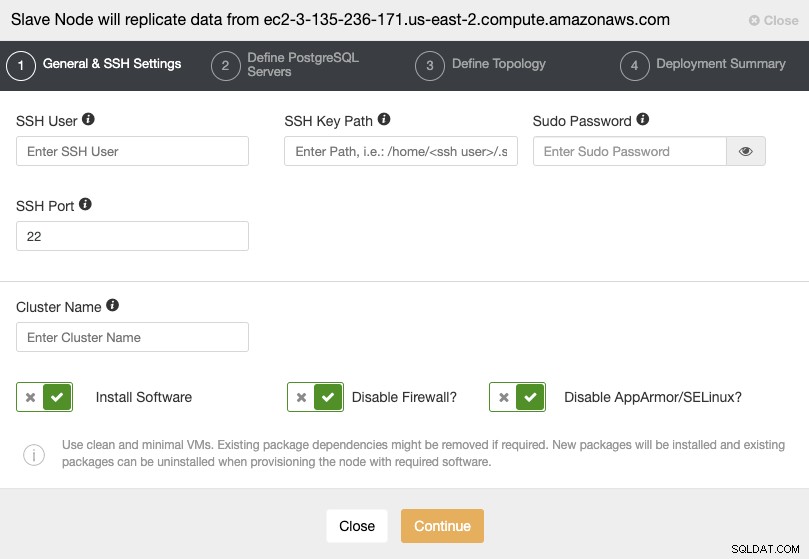
Når du går til næste trin, skal du angive Bruger, Nøgle eller Adgangskode og port for at forbinde med SSH til dine servere. Du skal også have et navn til din slaveklynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaseversionen, datadir, port og administratorlegitimationsoplysninger. Da det vil bruge streamingreplikering, skal du sørge for at bruge den samme databaseversion og legitimationsoplysninger, som bruges i Master Cluster. Du kan også angive, hvilket lager der skal bruges.
I dette trin skal du tilføje serveren til den nye slaveklynge . Til denne opgave kan du indtaste både IP-adressen eller værtsnavnet for databasenoden.
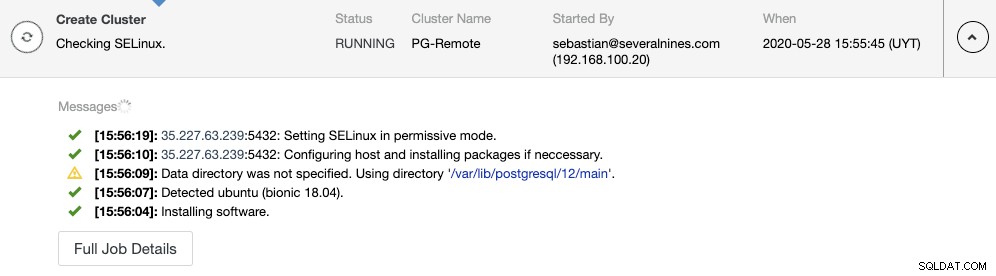
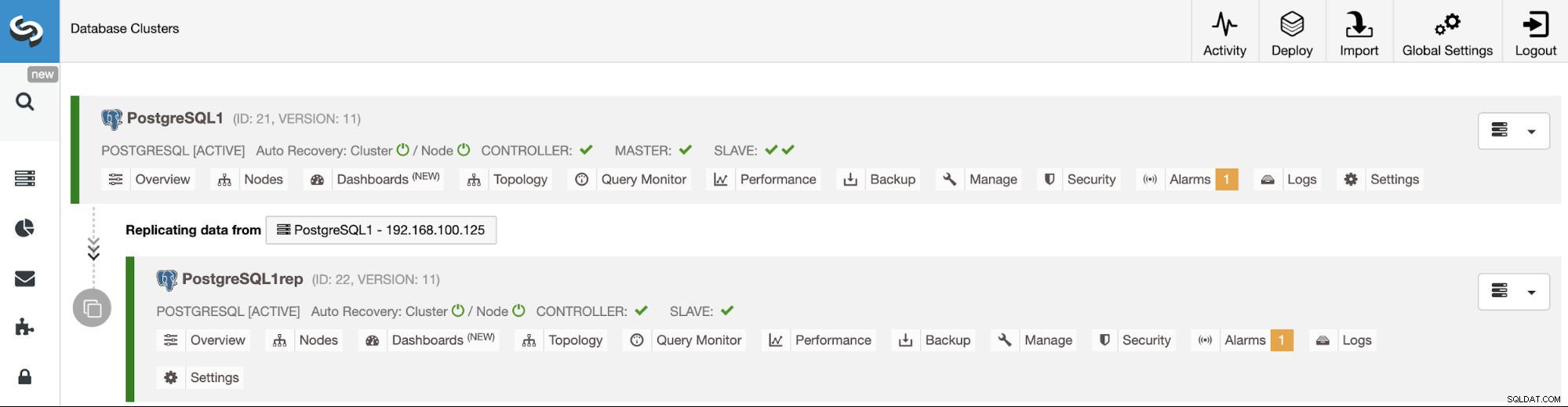
Du kan overvåge oprettelsen af slaveklyngen i ClusterControl-aktivitetsmonitoren. Når opgaven er færdig, kan du se klyngen på hovedskærmen til ClusterControl.
Konklusion
Disse ClusterControl-funktioner giver dig mulighed for hurtigt at opsætte replikering mellem forskellige Cloud-udbydere til en PostgreSQL-database (og forskellige teknologier) og administrere opsætningen på en nem og venlig måde. Om kommunikationen mellem Cloud-udbyderne skal du af sikkerhedsmæssige årsager kun begrænse trafikken fra kendte kilder, altså kun fra Cloud-udbyder 1 til Cloud-udbyder 2 og omvendt.