I den første del af denne blog nævnte vi nogle vigtige begreber relateret til et godt PostgreSQL-replikeringsmiljø. Lad os nu se, hvordan man kombinerer alle disse ting på en nem måde ved hjælp af ClusterControl. Til dette vil vi antage, at du har ClusterControl installeret, men hvis ikke, kan du gå til det officielle websted eller henvise til den officielle dokumentation for at installere det.
Implementering af PostgreSQL Streaming Replication
For at udføre en implementering af en PostgreSQL-klynge fra ClusterControl skal du vælge indstillingen Deploy og følge instruktionerne, der vises.
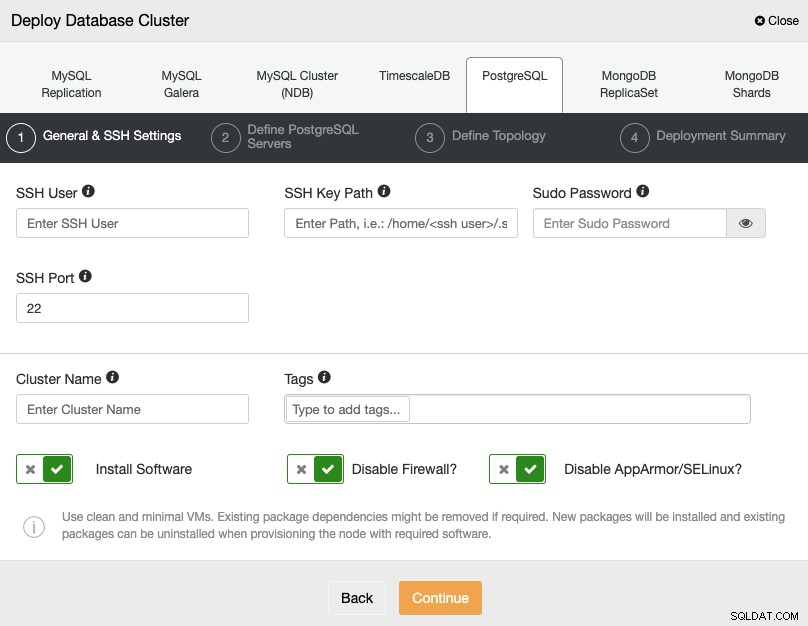
Når du vælger PostgreSQL, skal du angive brugeren, nøglen eller adgangskoden og Port for at forbinde med SSH til dine servere. Du kan også tilføje et navn til din nye klynge og angive, om du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
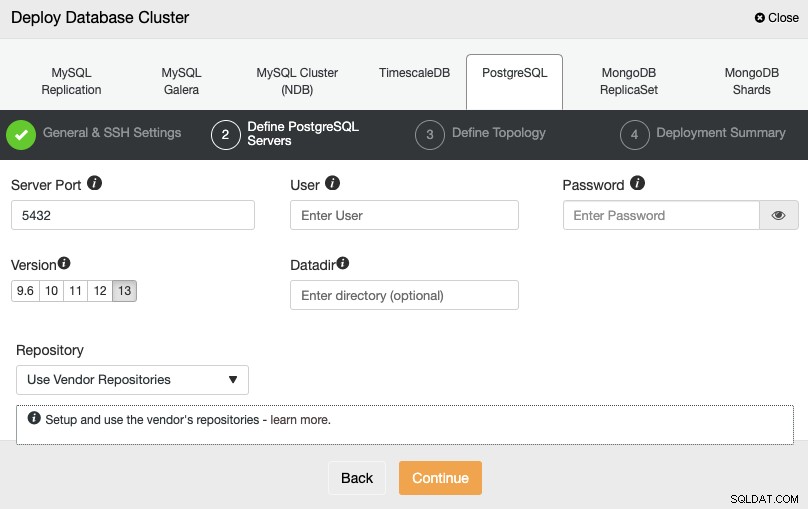
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaselegitimationsoplysningerne , version og datadir (valgfrit). Du kan også angive, hvilket lager der skal bruges.
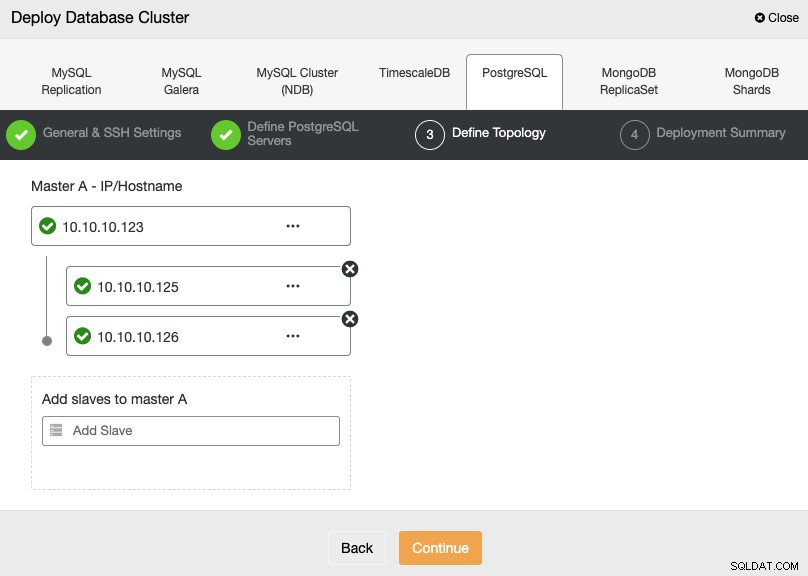
I næste trin skal du tilføje dine servere til den klynge, som du vil oprette ved hjælp af IP-adressen eller værtsnavnet.
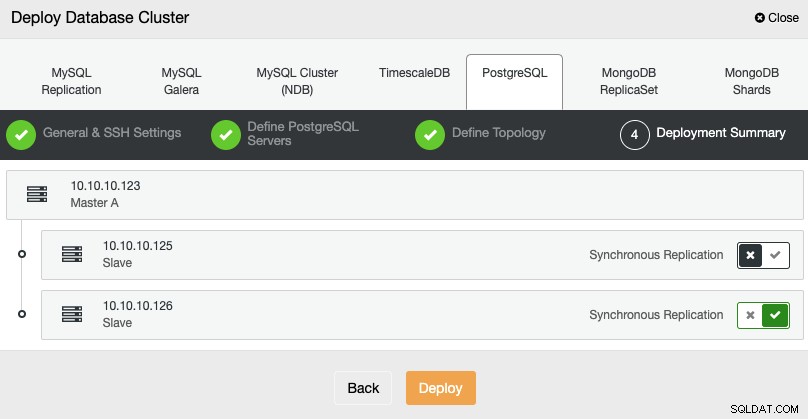
I det sidste trin kan du vælge, om din replikering skal være Synkron eller Asynkron, og tryk så bare på Deploy.
Når opgaven er færdig, kan du se din nye PostgreSQL-klynge i hovedskærmen ClusterControl.

Nu har du oprettet din klynge, du kan udføre flere opgaver på den, som at tilføje en belastningsbalancer (HAProxy), forbindelsespooler (PgBouncer) eller en ny synkron eller asynkron replikeringsslave.
Tilføjelse af synkrone og asynkrone replikeringsslaver
Gå til ClusterControl -> Cluster Actions -> Tilføj replikeringsslave.
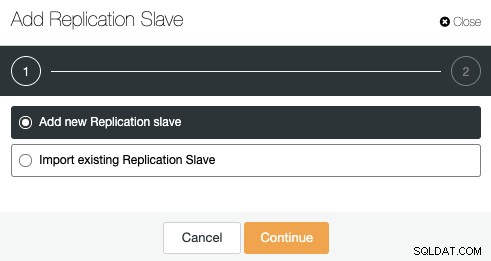
Du kan tilføje en ny replikeringsslave eller endda importere en eksisterende. Lad os vælge den første mulighed og fortsætte.
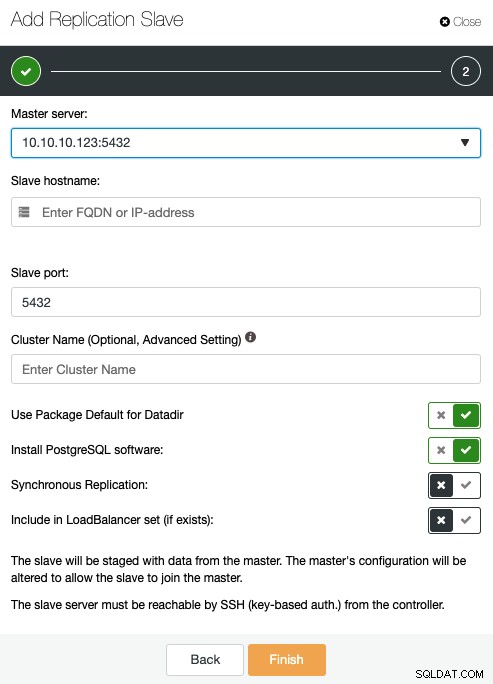
Her skal du angive masterserveren, IP-adressen eller værtsnavnet for den nye replikeringsslave, port, og hvis du ønsker ClusterControl, skal du installere softwaren, eller inkludere denne node i en eksisterende load balancer. Du kan også konfigurere replikeringen til at være synkron eller asynkron.
Nu har du din PostgreSQL-klynge på plads med de tilsvarende replikaer, lad os se, hvordan du forbedrer ydeevnen ved at tilføje en forbindelsespooler.
PgBouncer-implementering
Gå til ClusterControl -> Vælg PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer -> PgBouncer. Her kan du implementere en ny PgBouncer-node, der vil blive implementeret i den valgte databasenode, eller endda importere en eksisterende PgBouncer.
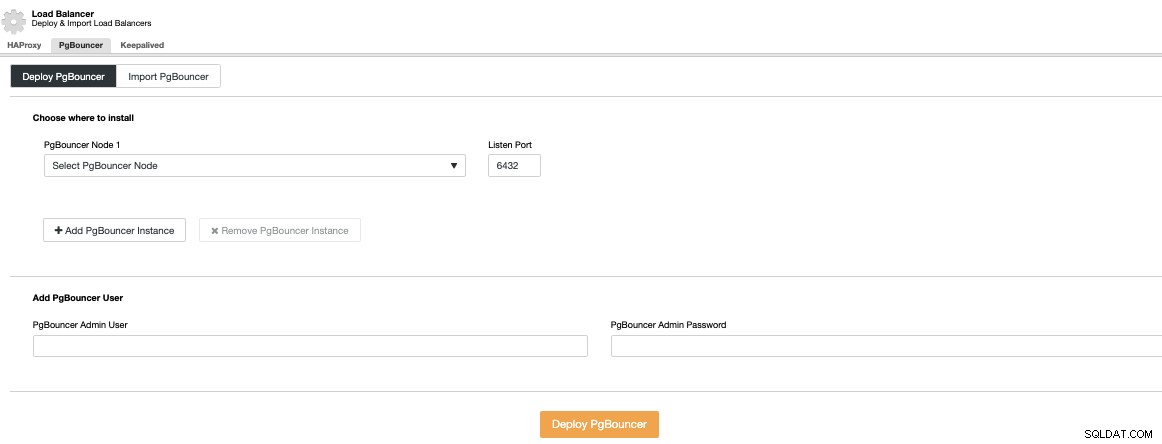
Du skal angive en IP-adresse eller værtsnavn, lytteporten og PgBouncer-legitimationsoplysninger. Når du trykker på Deploy PgBouncer, vil ClusterControl få adgang til noden, installere og konfigurere alt uden nogen manuel indgriben.
Du kan overvåge fremskridtene i ClusterControl-aktivitetssektionen. Når den er færdig, skal du oprette den nye pool. For dette, gå til ClusterControl -> Vælg PostgreSQL Cluster -> Noder -> PgBouncer node.
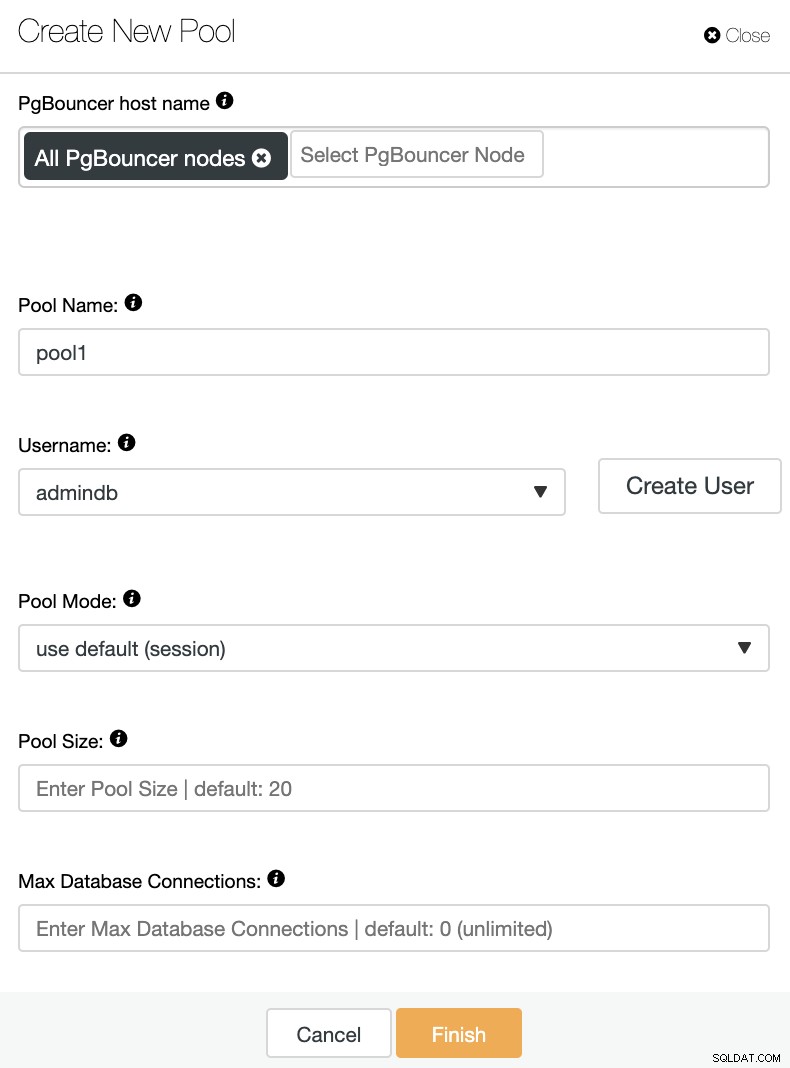
Du skal tilføje følgende oplysninger:
-
PgBouncer-værtsnavn:Vælg nodeværterne for at oprette forbindelsespuljen.
-
Poolnavn:Pool- og databasenavne skal være de samme.
-
Brugernavn: Vælg en bruger fra PostgreSQL primære node, eller opret en ny.
-
Puljetilstand:Det kan være:session (standard), transaktion eller pooling af kontoudtog.
-
Poolstørrelse:Maksimal størrelse af pools for denne database. Standardværdien er 20.
-
Maks. databaseforbindelser:Konfigurer et maksimum for hele databasen. Standardværdien er 0, hvilket betyder ubegrænset.
Nu skulle du være i stand til at se puljen i Node-sektionen.
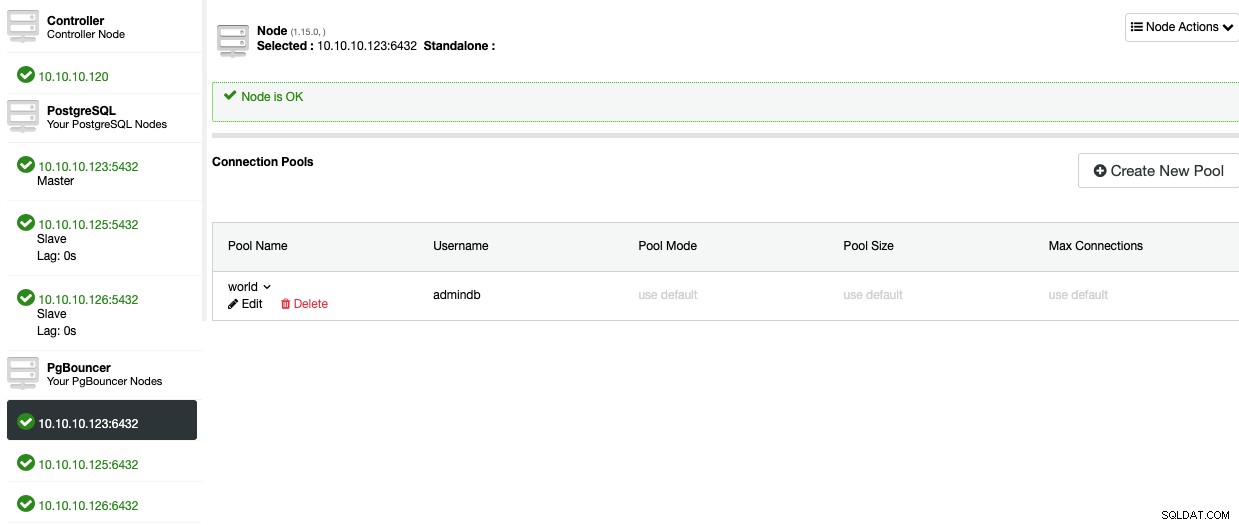
For at tilføje High Availability til din PostgreSQL-database, lad os se, hvordan du implementerer en belastningsbalancer.
Load Balancer-implementering
For at udføre en load balancer-implementering skal du vælge indstillingen Tilføj load balancer i menuen Cluster Actions og udfylde de anmodede oplysninger.
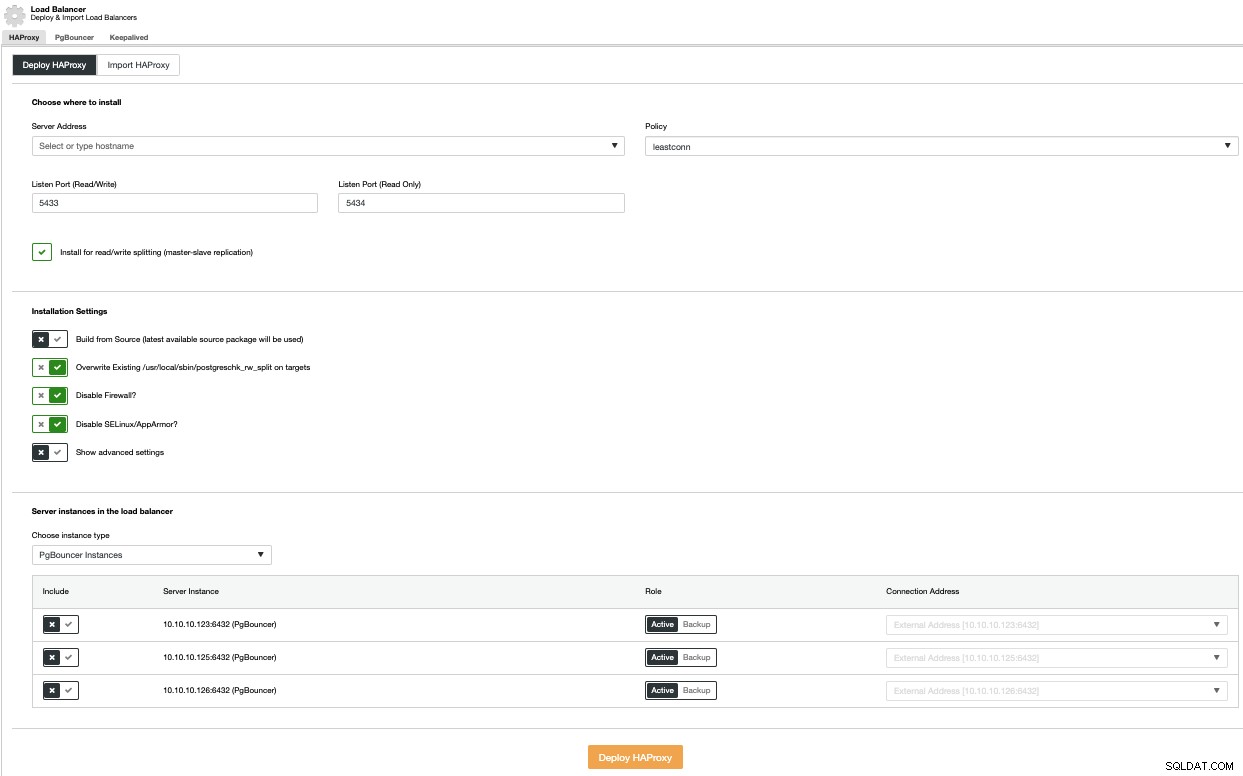
Du skal tilføje IP eller værtsnavn, port, politik og noderne du skal bruge. Hvis du bruger PgBouncer, kan du vælge det i kombinationsboksen for eksempeltype.
For at undgå et enkelt fejlpunkt bør du implementere mindst to HAProxy-noder og bruge Keepalved, som giver dig mulighed for at bruge en virtuel IP-adresse i din applikation, som er tildelt den aktive HAProxy-knude. Hvis denne node fejler, vil den virtuelle IP-adresse blive migreret til den sekundære load balancer, så din applikation stadig kan fungere som normalt.
Keelived implementering
For at udføre en Keepalive-implementering skal du vælge indstillingen Tilføj Load Balancer i menuen Cluster Actions og derefter gå til fanen Keepalived.
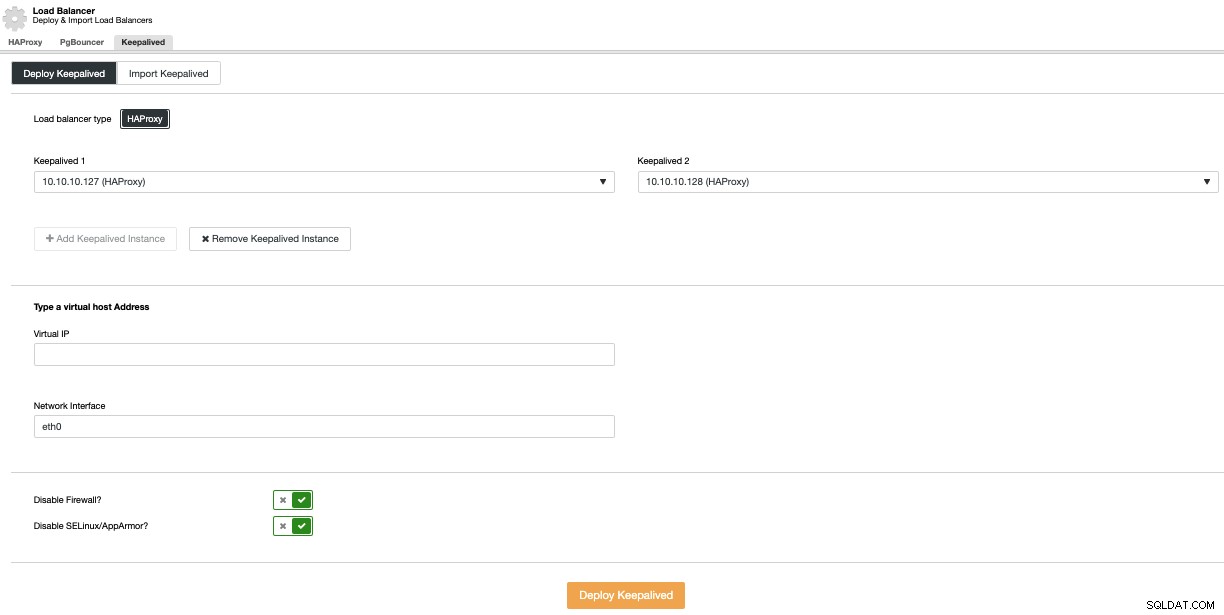
Her skal du vælge HAProxy-noder og angive den virtuelle IP-adresse, der vil bruges til at få adgang til databasen (eller forbindelsespooleren).
I øjeblikket bør du have følgende topologi:
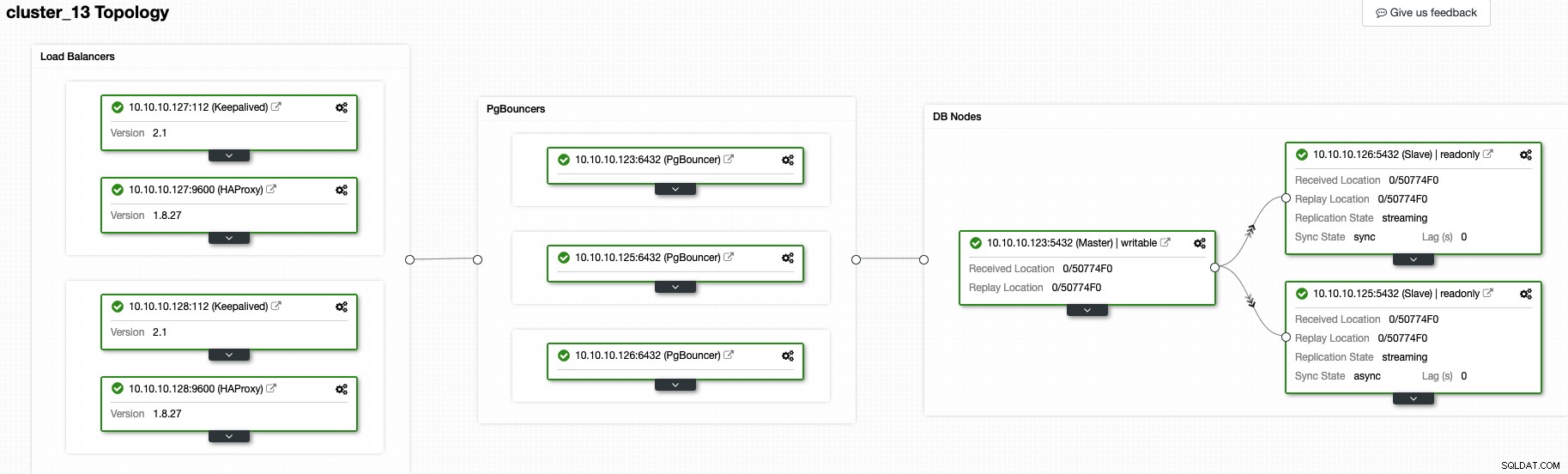
Og det betyder:HAProxy + Keepalived -> PgBouncer -> PostgreSQL-databasenoder , det er en god topologi til din PostgreSQL-klynge.
ClusterControl Autogendannelsesfunktion
I tilfælde af fejl vil ClusterControl fremme den mest avancerede standby-knude til primær samt give dig besked om problemet. Det mislykkes også over resten af standby-noden at replikere fra den nye primære server.
Som standard er HAProxy konfigureret med to forskellige porte:read-write og read-only. I læse-skriveporten har du din primære database (eller PgBouncer) node som online og resten af noderne som offline, og i den skrivebeskyttede port har du både den primære og standby node online.
Når HAProxy registrerer, at en af dine noder ikke er tilgængelig, markerer den den automatisk som offline og tager den ikke i betragtning for at sende trafik til den. Detektion udføres af sundhedstjekscripts, der er konfigureret af ClusterControl på tidspunktet for implementeringen. Disse kontrollerer, om forekomsterne er oppe, om de er under gendannelse eller er skrivebeskyttede.
Når ClusterControl promoverer en standby-node, markerer HAProxy den gamle primære som offline for begge porte og sætter den promoverede node online i læse-skrive-porten.
Hvis din aktive HAProxy, som er tildelt en virtuel IP-adresse, som dine systemer forbinder til, fejler, migrerer Keepalved denne IP-adresse til din passive HAProxy automatisk. Det betyder, at dine systemer så kan fortsætte med at fungere normalt.
Konklusion
Som du kan se, er det nemt at have en god PostgreSQL-topologi, hvis du bruger ClusterControl, og hvis du følger de grundlæggende bedste praksis-koncepter for PostgreSQL-replikering. Det bedste miljø afhænger selvfølgelig af arbejdsbyrden, hardware, applikation osv., men du kan bruge det som eksempel og flytte brikkerne efter behov.