Den mest intuitive måde at opgradere databasen på, er at generere en replika i en ny version og udføre en failover af applikationen ind i den, og faktisk fungerer den perfekt i andre motorer. Med PostgreSQL plejede dette at være umuligt på en indbygget måde. For at opnå opgraderinger var du nødt til at tænke på andre måder at opgradere på, såsom at bruge pg_upgrade, dumping og gendannelse, eller bruge nogle tredjepartsværktøjer som Slony eller Bucardo, som alle har deres egne forbehold. Dette er på grund af den måde, PostgreSQL brugte til at implementere replikering.
PostgreSQL-streamingreplikering (den almindelige PostgreSQL-replikering) er en fysisk replikering, der replikerer ændringerne på et byte-for-byte-niveau, hvilket skaber en identisk kopi af databasen på en anden server. Denne metode har mange begrænsninger, når du tænker på en opgradering, da du simpelthen ikke kan oprette en replika i en anden serverversion eller endda i en anden arkitektur.
Siden PostgreSQL 10 har den implementeret indbygget logisk replikering, som i modsætning til fysisk replikering kan replikere mellem forskellige større versioner af PostgreSQL. Dette åbner selvfølgelig en ny dør for opgraderingsstrategier.
I denne blog vil vi se, hvordan du kan opgradere din PostgreSQL 11 til PostgreSQL 12 uden nedetid ved hjælp af logisk replikering.
Logisk PostgreSQL-replikering
Logisk replikering er en metode til at replikere dataobjekter og deres ændringer baseret på deres replikeringsidentitet (normalt en primær nøgle). Den er baseret på en udgivelses- og abonnenttilstand, hvor en eller flere abonnenter abonnerer på en eller flere publikationer på en udgivernode.
En publikation er et sæt ændringer genereret fra en tabel eller en gruppe af tabeller (også kaldet et replikeringssæt). Noden, hvor en publikation er defineret, omtales som udgiver. Et abonnement er downstream-siden af logisk replikering. Noden, hvor et abonnement er defineret, omtales som abonnenten, og det definerer forbindelsen til en anden database og et sæt publikationer (en eller flere), som den ønsker at abonnere på. Abonnenter henter data fra de publikationer, de abonnerer på.
Logisk replikering er bygget med en arkitektur, der ligner fysisk streamingreplikering. Det er implementeret af "walsender" og "anvend" processer. Walsender-processen starter logisk afkodning af WAL og indlæser standard logisk afkodningsplugin. Pluginnet transformerer de læste ændringer fra WAL til den logiske replikeringsprotokol og filtrerer dataene i henhold til publikationsspecifikationen. Dataene overføres derefter løbende ved hjælp af streaming-replikeringsprotokollen til appliceringsarbejderen, som kortlægger dataene til lokale tabeller og anvender de individuelle ændringer, efterhånden som de modtages, i en korrekt transaktionsrækkefølge.
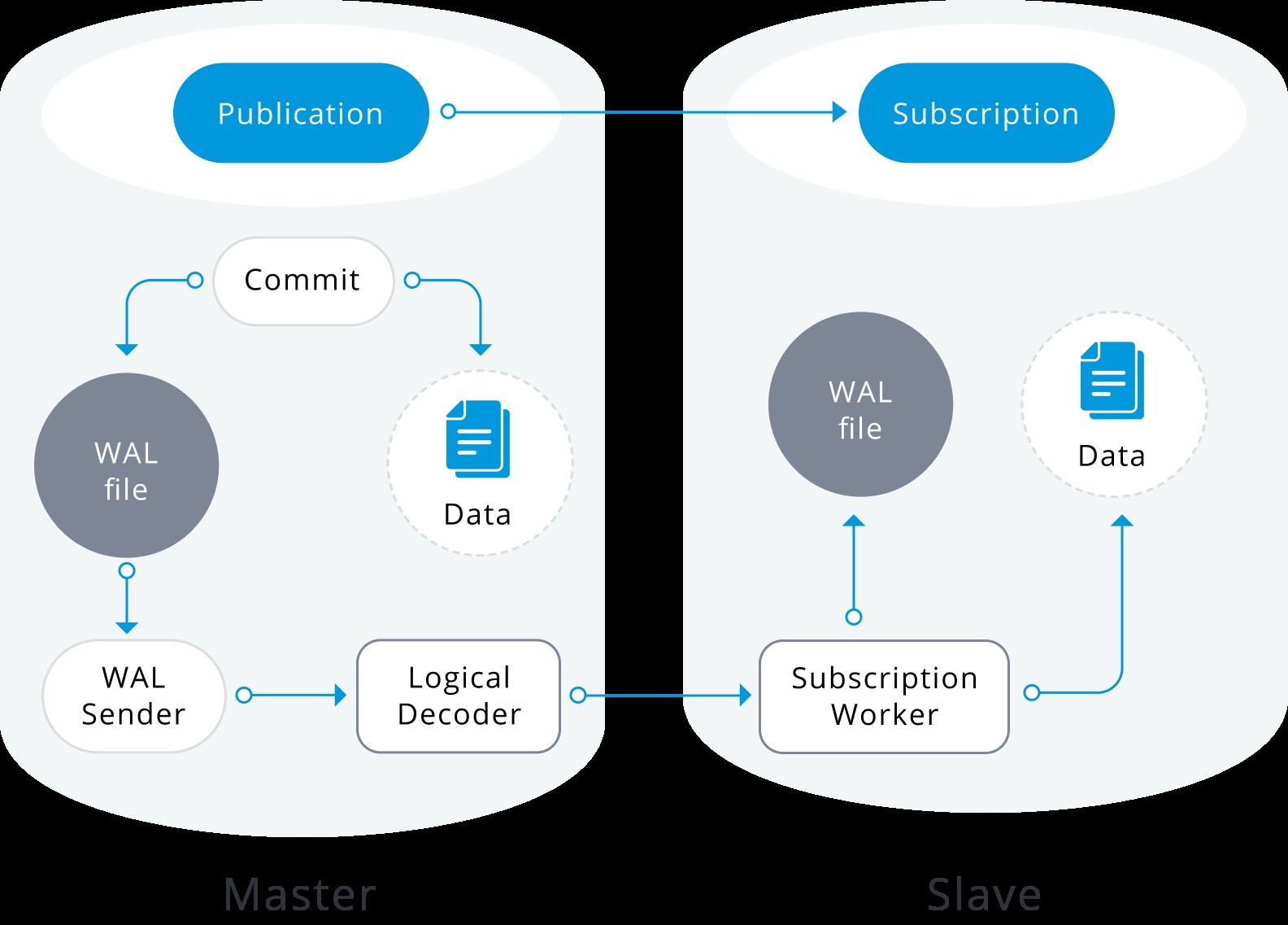
Logisk replikering starter med at tage et øjebliksbillede af dataene i udgiverdatabasen og kopiere det til abonnenten. De indledende data i de eksisterende tilmeldte tabeller tages snapshots og kopieres i en parallel instans af en særlig form for ansøgningsproces. Denne proces vil oprette sin egen midlertidige replikeringsplads og kopiere de eksisterende data. Når de eksisterende data er kopieret, går arbejderen i synkroniseringstilstand, som sikrer, at tabellen bringes op til en synkroniseret tilstand med hovedanvendelsesprocessen ved at streame ændringer, der skete under den indledende datakopiering, ved hjælp af standard logisk replikering. Når synkroniseringen er udført, bliver kontrollen over replikeringen af tabellen givet tilbage til hovedanvendelsesprocessen, hvor replikeringen fortsætter som normalt. Ændringerne på udgiveren sendes til abonnenten, efterhånden som de sker i realtid.
Sådan opgraderer du PostgreSQL 11 til PostgreSQL 12 ved hjælp af logisk replikering
Vi skal konfigurere logisk replikering mellem to forskellige større versioner af PostgreSQL (11 og 12), og selvfølgelig, når du har fået dette til at virke, er det kun et spørgsmål om at udføre en applikations-failover i database med den nyere version.
Vi skal udføre følgende trin for at få logisk replikering til at fungere:
- Konfigurer udgivernoden
- Konfigurer abonnentknudepunktet
- Opret abonnentbrugeren
- Opret en publikation
- Opret tabelstrukturen i abonnenten
- Opret abonnementet
- Tjek replikeringsstatussen
Så lad os starte.
På udgiversiden vil vi konfigurere følgende parametre i postgresql.conf-filen:
- lytteadresser: Hvilke(n) IP-adresse(r) skal man lytte på. Vi bruger '*' for alle.
- wal_level: Bestemmer, hvor meget information der skrives til WAL. Vi vil indstille det til "logisk".
- max_replication_slots :Angiver det maksimale antal replikeringspladser, som serveren kan understøtte. Den skal som minimum indstilles til det antal abonnementer, der forventes at forbinde, plus en vis reserve til bordsynkronisering.
- max_wal_senders: Angiver det maksimale antal samtidige forbindelser fra standby-servere eller streaming-base backup-klienter. Den skal være indstillet til mindst det samme som max_replication_slots plus antallet af fysiske replikaer, der er forbundet på samme tid.
Husk, at nogle af disse parametre krævede en genstart af PostgreSQL-tjenesten for at kunne anvendes.
pg_hba.conf-filen skal også justeres for at tillade replikering. Du skal tillade replikeringsbrugeren at oprette forbindelse til databasen.
Så baseret på dette, lad os konfigurere udgiveren (i dette tilfælde PostgreSQL 11-serveren) som følger:
postgresql.conf:
listen_addresses = '*'
wal_level = logical
max_wal_senders = 8
max_replication_slots = 4pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host all rep1 10.10.10.131/32 md5
Du skal ændre brugeren (i dette eksempel rep1), som vil blive brugt til replikering, og IP-adressen 10.10.10.131/32 for den IP, der svarer til din PostgreSQL 12-node.
På abonnentsiden kræver det også, at max_replication_slots er indstillet. I dette tilfælde skal den indstilles til mindst antallet af abonnementer, der vil blive tilføjet til abonnenten.
De andre parametre, der også skal indstilles her, er:
- max_logical_replication_workers :Angiver det maksimale antal logiske replikeringsarbejdere. Dette inkluderer både anvende arbejdere og tabelsynkroniseringsarbejdere. Logiske replikeringsarbejdere tages fra puljen defineret af max_worker_processes. Den skal som minimum indstilles til antallet af abonnementer, igen plus en vis reserve til bordsynkronisering.
- max_worker_processes :Indstiller det maksimale antal baggrundsprocesser, som systemet kan understøtte. Den skal muligvis justeres for at imødekomme replikeringsarbejdere, mindst max_logical_replication_workers + 1. Denne parameter kræver en PostgreSQL-genstart.
Så du skal konfigurere abonnenten (i dette tilfælde PostgreSQL 12-serveren) som følger:
postgresql.conf:
listen_addresses = '*'
max_replication_slots = 4
max_logical_replication_workers = 4
max_worker_processes = 8Da denne PostgreSQL 12 snart bliver den nye primære node, bør du overveje at tilføje parametrene wal_level og archive_mode i dette trin for at undgå en ny genstart af tjenesten senere.
wal_level = logical
archive_mode = onDisse parametre vil være nyttige, hvis du vil tilføje en ny replika eller til at bruge PITR-sikkerhedskopier.
I udgiveren skal du oprette den bruger, som abonnenten vil oprette forbindelse til:
world=# CREATE ROLE rep1 WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEDen rolle, der bruges til replikeringsforbindelsen, skal have attributten REPLICATION. Adgang til rollen skal konfigureres i pg_hba.conf, og den skal have LOGIN-attributten.
For at kunne kopiere de oprindelige data skal den rolle, der bruges til replikeringsforbindelsen, have SELECT-privilegiet på en offentliggjort tabel.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep1;
GRANTVi opretter publikation 1 i udgivernoden for alle tabellerne:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONBrugeren, der vil oprette en publikation, skal have CREATE-privilegiet i databasen, men for at oprette en publikation, der udgiver alle tabeller automatisk, skal brugeren være en superbruger.
For at bekræfte den oprettede publikation vil vi bruge pg_publication-kataloget. Dette katalog indeholder information om alle publikationer, der er oprettet i databasen.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+-----
pubname | pub1
pubowner | 10
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | t
pubtruncate | tKolonnebeskrivelser:
- pubnavn :Navn på publikationen.
- udstedsejer :Ejer af publikationen.
- publikumsborde :Hvis det er sandt, inkluderer denne publikation automatisk alle tabeller i databasen, inklusive dem, der vil blive oprettet i fremtiden.
- pubinsert :Hvis sandt, replikeres INSERT-operationer for tabeller i publikationen.
- pubupdate :Hvis sandt, replikeres UPDATE-handlinger for tabeller i publikationen.
- pubdelete :Hvis sandt, replikeres DELETE-handlinger for tabeller i publikationen.
- pubtruncate :Hvis sandt, replikeres TRUNCATE-operationer for tabeller i publikationen.
Da skemaet ikke er replikeret, skal du tage en sikkerhedskopi i PostgreSQL 11 og gendanne den i din PostgreSQL 12. Sikkerhedskopien tages kun for skemaet, da informationen vil blive replikeret i den indledende overførsel.
I PostgreSQL 11:
$ pg_dumpall -s > schema.sqlI PostgreSQL 12:
$ psql -d postgres -f schema.sqlNår du har dit skema i PostgreSQL 12, skal du oprette abonnementet og erstatte værdierne for vært, dbname, bruger og adgangskode med dem, der svarer til dit miljø.
PostgreSQL 12:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=10.10.10.130 dbname=world user=rep1 password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONOvenstående starter replikeringsprocessen, som synkroniserer det indledende tabelindhold i tabellerne i publikationen og derefter begynder at replikere trinvise ændringer af disse tabeller.
Brugeren, der opretter et abonnement, skal være en superbruger. Abonnementsanvendelsesprocessen vil køre i den lokale database med privilegier som en superbruger.
For at bekræfte det oprettede abonnement kan du bruge pg_stat_subscription-kataloget. Denne visning vil indeholde én række pr. abonnement for hovedarbejderen (med null PID, hvis arbejderen ikke kører), og yderligere rækker for arbejdere, der håndterer den indledende datakopi af de tilmeldte tabeller.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16422
subname | sub1
pid | 476
relid |
received_lsn | 0/1771668
last_msg_send_time | 2020-09-29 17:40:34.711411+00
last_msg_receipt_time | 2020-09-29 17:40:34.711533+00
latest_end_lsn | 0/1771668
latest_end_time | 2020-09-29 17:40:34.711411+00Kolonnebeskrivelser:
- subid :OID for abonnementet.
- undernavn :Navn på abonnementet.
- pid :Proces-id for abonnementsarbejderprocessen.
- relid :OID for den relation, som arbejderen synkroniserer; null for hovedansøgeren.
- received_lsn :Sidste fremskrivningslogplacering modtaget, startværdien af dette felt er 0.
- sidste_msg_send_time :Sendetidspunkt for sidste besked modtaget fra oprindelig WAL-afsender.
- sidste_msg_receipt_time :Modtagelsestidspunkt for sidste besked modtaget fra oprindelig WAL-afsender.
- latest_end_lsn :Sidste fremskrivningslogplacering rapporteret til den oprindelige WAL-afsender.
- seneste_sluttid :Tidspunkt for sidste fremskrivningslogplacering rapporteret til den oprindelige WAL-afsender.
For at verificere status for replikering i den primære node kan du bruge pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 527
usesysid | 16428
usename | rep1
application_name | sub1
client_addr | 10.10.10.131
client_hostname |
client_port | 35570
backend_start | 2020-09-29 17:40:04.404905+00
backend_xmin |
state | streaming
sent_lsn | 0/1771668
write_lsn | 0/1771668
flush_lsn | 0/1771668
replay_lsn | 0/1771668
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncKolonnebeskrivelser:
- pid :Proces-id for en WAL-afsenderproces.
- usesysid :OID for den bruger, der er logget på denne WAL-afsenderproces.
- brugsnavn :Navnet på den bruger, der er logget på denne WAL-afsenderproces.
- application_name :Navnet på den applikation, der er forbundet til denne WAL-afsender.
- client_addr :IP-adressen på den klient, der er tilsluttet denne WAL-afsender. Hvis dette felt er null, angiver det, at klienten er forbundet via en Unix-socket på servermaskinen.
- client_hostname :Værtsnavn på den tilsluttede klient, som rapporteret af et omvendt DNS-opslag af client_addr. Dette felt vil kun være ikke-nul for IP-forbindelser, og kun når log_hostname er aktiveret.
- client_port :TCP-portnummer, som klienten bruger til kommunikation med denne WAL-afsender, eller -1, hvis der bruges en Unix-socket.
- backend_start :Tidspunkt, hvor denne proces blev startet.
- backend_xmin :Denne standbys xmin-horisont rapporteret af hot_standby_feedback.
- tilstand :Aktuel WAL-afsendertilstand. De mulige værdier er:start, catchup, streaming, backup og stop.
- sent_lsn :Sidste fremskrivningslogplacering sendt på denne forbindelse.
- write_lsn :Sidste fremskrivningslogplacering skrevet til disken af denne standby-server.
- flush_lsn :Sidste fremskrivningslogplacering blev tømt til disken af denne standby-server.
- replay_lsn :Sidste fremskrivningslogplacering afspillet i databasen på denne standby-server.
- write_lag :Der gik tid mellem tømning af seneste WAL lokalt og modtagelse af meddelelse om, at denne standby-server har skrevet den (men endnu ikke tømt den eller anvendt den).
- flush_lag :Der gik tid mellem tømning af seneste WAL lokalt og modtagelse af meddelelse om, at denne standby-server har skrevet og tømt den (men endnu ikke anvendt den).
- replay_lag :Der er gået tid mellem tømning af seneste WAL lokalt og modtagelse af meddelelse om, at denne standby-server har skrevet, tømt og anvendt den.
- sync_priority :Prioritet for denne standbyserver for at blive valgt som synkron standby i en prioritetsbaseret synkron replikering.
- sync_state :Synkron tilstand for denne standby-server. De mulige værdier er async, potential, sync, quorum.
For at kontrollere, hvornår den første overførsel er afsluttet, kan du tjekke PostgreSQL-loggen på abonnenten:
2020-09-29 17:40:04.403 UTC [476] LOG: logical replication apply worker for subscription "sub1" has started
2020-09-29 17:40:04.411 UTC [477] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2020-09-29 17:40:04.422 UTC [478] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2020-09-29 17:40:04.516 UTC [477] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2020-09-29 17:40:04.522 UTC [479] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2020-09-29 17:40:04.570 UTC [478] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2020-09-29 17:40:04.676 UTC [479] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedEller kontrollerer srsubstate-variablen på pg_subscription_rel-kataloget. Dette katalog indeholder tilstanden for hver replikeret relation i hvert abonnement.
world=# SELECT * FROM pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+-----------
16422 | 16386 | r | 0/1771630
16422 | 16392 | r | 0/1771630
16422 | 16399 | r | 0/1771668
(3 rows)Kolonnebeskrivelser:
- srsubid :Reference til abonnement.
- srrelid :Reference til relation.
- srsubstate :Tilstandskode:i =initialisere, d =data bliver kopieret, s =synkroniseret, r =klar (normal replikering).
- srsublsn :Afslut LSN for s- og r-tilstande.
Du kan indsætte nogle testposter i din PostgreSQL 11 og validere, at du har dem i din PostgreSQL 12:
PostgreSQL 11:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 12:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)På dette tidspunkt har du alt klar til at pege din ansøgning til din PostgreSQL 12.
For dette skal du først og fremmest bekræfte, at du ikke har replikeringsforsinkelse.
På den primære node:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0Og nu behøver du kun at ændre dit slutpunkt fra din applikation eller belastningsbalancer (hvis du har en) til den nye PostgreSQL 12-server.
Hvis du har en load balancer som HAProxy, kan du konfigurere den ved at bruge PostgreSQL 11 som aktiv og PostgreSQL 12 som backup på denne måde:
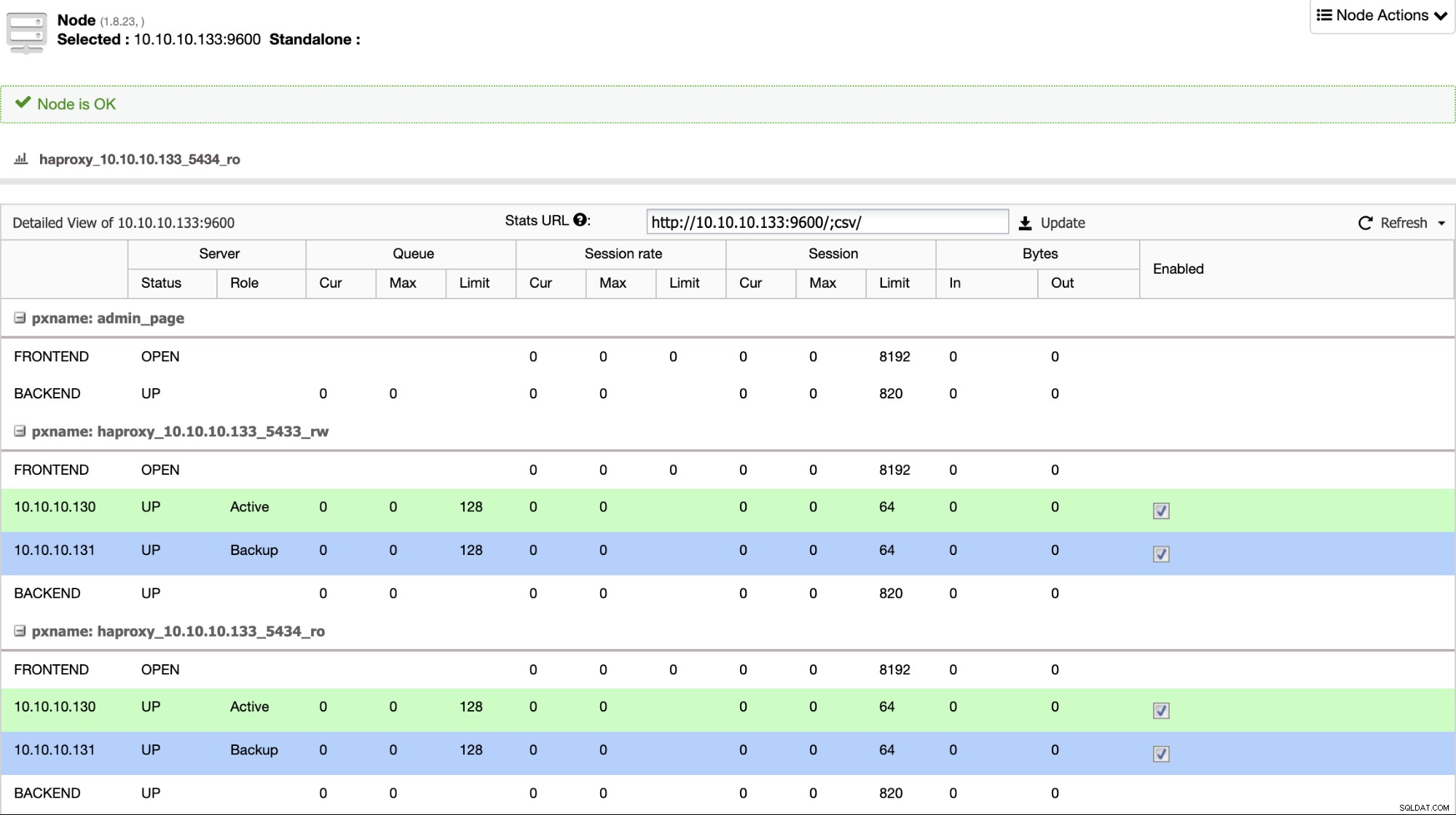
Så hvis du bare lukker den gamle primære node i PostgreSQL 11, backup-serveren, i dette tilfælde i PostgreSQL 12, begynder at modtage trafikken på en gennemsigtig måde for brugeren/applikationen.
Ved afslutningen af migreringen kan du slette abonnementet i din nye primære node i PostgreSQL 12:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONOg bekræft, at den er fjernet korrekt:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Begrænsninger
Inden du bruger den logiske replikering, skal du huske følgende begrænsninger:
- Databaseskemaet og DDL-kommandoer er ikke replikeret. Det indledende skema kan kopieres ved hjælp af pg_dump --schema-only.
- Sekvensdata er ikke replikeret. Dataene i serie- eller identitetskolonner understøttet af sekvenser vil blive replikeret som en del af tabellen, men selve sekvensen vil stadig vise startværdien på abonnenten.
- Replikering af TRUNCATE-kommandoer er understøttet, men der skal udvises en vis forsigtighed ved trunkering af grupper af tabeller forbundet med fremmednøgler. Når du replikerer en trunkeringshandling, vil abonnenten trunkere den samme gruppe af tabeller, som blev afkortet på udgiveren, enten eksplicit specificeret eller implicit indsamlet via CASCADE, minus tabeller, der ikke er en del af abonnementet. Dette vil fungere korrekt, hvis alle berørte tabeller er en del af det samme abonnement. Men hvis nogle tabeller, der skal afkortes på abonnenten, har fremmednøglelinks til tabeller, der ikke er en del af det samme (eller noget) abonnement, vil anvendelsen af trunkeringshandlingen på abonnenten mislykkes.
- Store objekter replikeres ikke. Der er ingen løsning på det, udover at gemme data i normale tabeller.
- Replikering er kun mulig fra basistabeller til basistabeller. Det vil sige, at tabellerne på publikationen og på abonnementssiden skal være normale tabeller, ikke visninger, materialiserede visninger, partitionsrodtabeller eller fremmede tabeller. I tilfælde af partitioner kan du replikere et partitionshierarki en-til-en, men du kan i øjeblikket ikke replikere til en anderledes partitioneret opsætning.
Konklusion
At holde din PostgreSQL-server opdateret ved at udføre regelmæssige opgraderinger har været en nødvendig, men vanskelig opgave indtil PostgreSQL 10-versionen. Heldigvis er det nu en anden historie takket være logisk replikering.
I denne blog har vi lavet en kort introduktion til logisk replikering, en PostgreSQL-funktion introduceret indbygget i version 10, og vi har vist dig, hvordan den kan hjælpe dig med at opnå denne opgradering fra PostgreSQL 11 til PostgreSQL 12-udfordring med en strategi uden nedetid.