Brug af replikering til dine PostgreSQL-databaser kan være nyttigt, ikke kun for at have et høj tilgængelighed og fejltolerant miljø, men også for at forbedre ydeevnen på dit system ved at balancere trafikken mellem standby-knudepunkterne. I denne første del af den todelte blog skal vi se nogle koncepter relateret til PostgreSQL-replikeringen.
Replikeringsmetoder i PostgreSQL
Der er forskellige metoder til at replikere data i PostgreSQL, men her vil vi fokusere på de to hovedmetoder:Streaming replikering og logisk replikering.
Streamende replikering
PostgreSQL-streamingreplikering, den mest almindelige PostgreSQL-replikering, er en fysisk replikering, der replikerer ændringerne på et byte-for-byte-niveau, hvilket skaber en identisk kopi af databasen på en anden server. Det er baseret på logforsendelsesmetoden. WAL-posterne flyttes direkte fra en databaseserver til en anden for at blive anvendt. Vi kan sige, at det er en slags kontinuerlig PITR.
Denne WAL-overførsel udføres på to forskellige måder, ved at overføre WAL-records én fil (WAL-segment) ad gangen (filbaseret logforsendelse) og ved at overføre WAL-poster (en WAL-fil består af WAL-poster) på farten (rekordbaseret logforsendelse), mellem en primær server og en eller flere end på standby-servere, uden at vente på, at WAL-filen bliver udfyldt.
I praksis vil en proces kaldet WAL-modtager, der kører på standby-serveren, oprette forbindelse til den primære server ved hjælp af en TCP/IP-forbindelse. I den primære server findes en anden proces, kaldet WAL-afsender, og den er ansvarlig for at sende WAL-registre til standby-serveren, efterhånden som de sker.
En grundlæggende streamingreplikering kan repræsenteres som følgende:
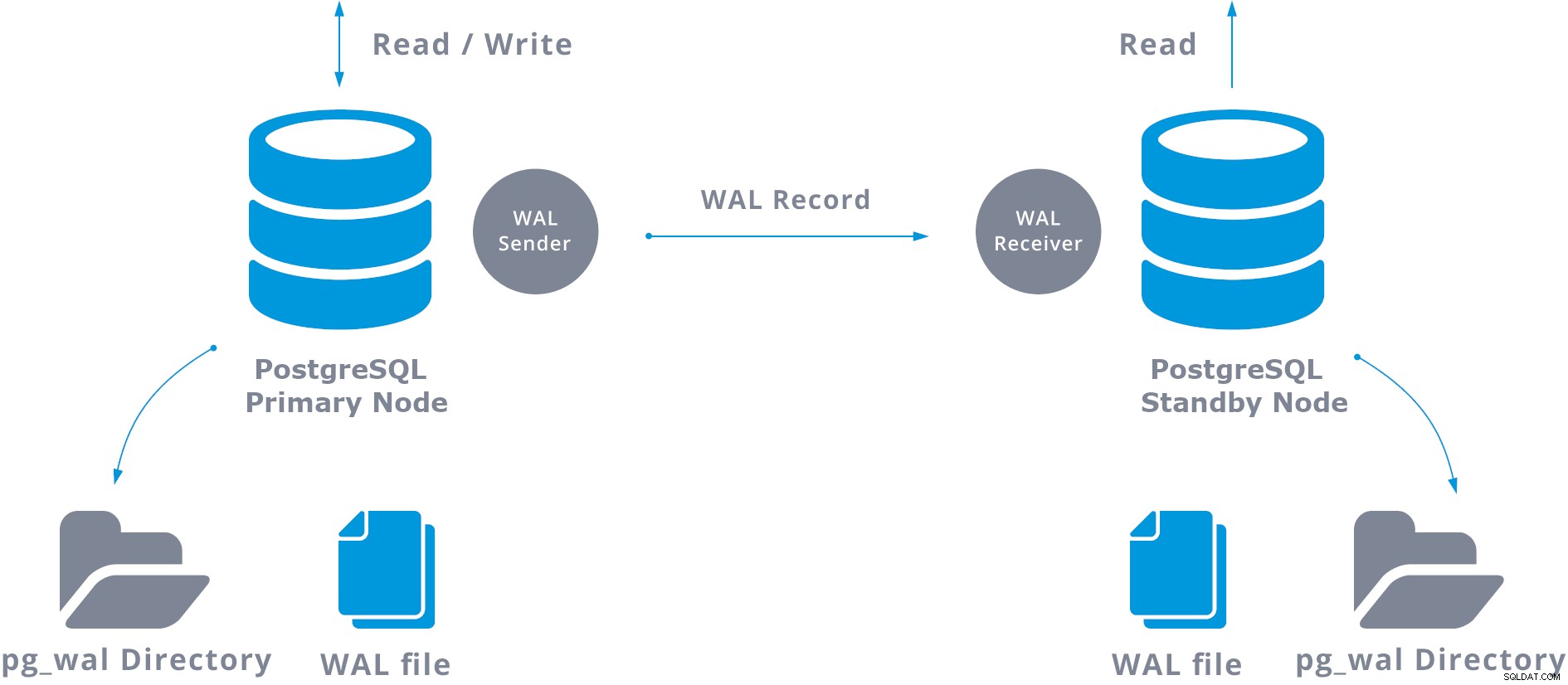
Når du konfigurerer streamingreplikering, har du mulighed for at aktivere WAL-arkivering. Dette er ikke obligatorisk, men er ekstremt vigtigt for robust replikeringsopsætning, da det er nødvendigt at undgå, at hovedserveren genbruger gamle WAL-filer, som endnu ikke er blevet anvendt på standby-serveren. Hvis dette sker, bliver du nødt til at genskabe replikaen fra bunden.
Logisk replikering
PostgreSQL logisk replikering er en metode til at replikere dataobjekter og deres ændringer baseret på deres replikeringsidentitet (normalt en primær nøgle). Den er baseret på en udgivelses- og abonnenttilstand, hvor en eller flere abonnenter abonnerer på en eller flere publikationer på en udgivernode.
En publikation er et sæt ændringer genereret fra en tabel eller en gruppe af tabeller. Noden, hvor en publikation er defineret, omtales som udgiver. Et abonnement er downstream-siden af logisk replikering. Noden, hvor et abonnement er defineret, omtales som abonnenten, og det definerer forbindelsen til en anden database og et sæt publikationer (en eller flere), som den ønsker at abonnere på. Abonnenter henter data fra de publikationer, de abonnerer på.
Logisk replikering er bygget med en arkitektur, der ligner fysisk streamingreplikering. Det er implementeret af "walsender" og "anvend" processer. Walsender-processen starter logisk afkodning af WAL og indlæser standard logisk afkodningsplugin. Pluginnet transformerer de læste ændringer fra WAL til den logiske replikeringsprotokol og filtrerer dataene i henhold til publikationsspecifikationen. Dataene overføres derefter løbende ved hjælp af streaming-replikeringsprotokollen til appliceringsarbejderen, som kortlægger dataene til lokale tabeller og anvender de individuelle ændringer, efterhånden som de modtages, i en korrekt transaktionsrækkefølge.
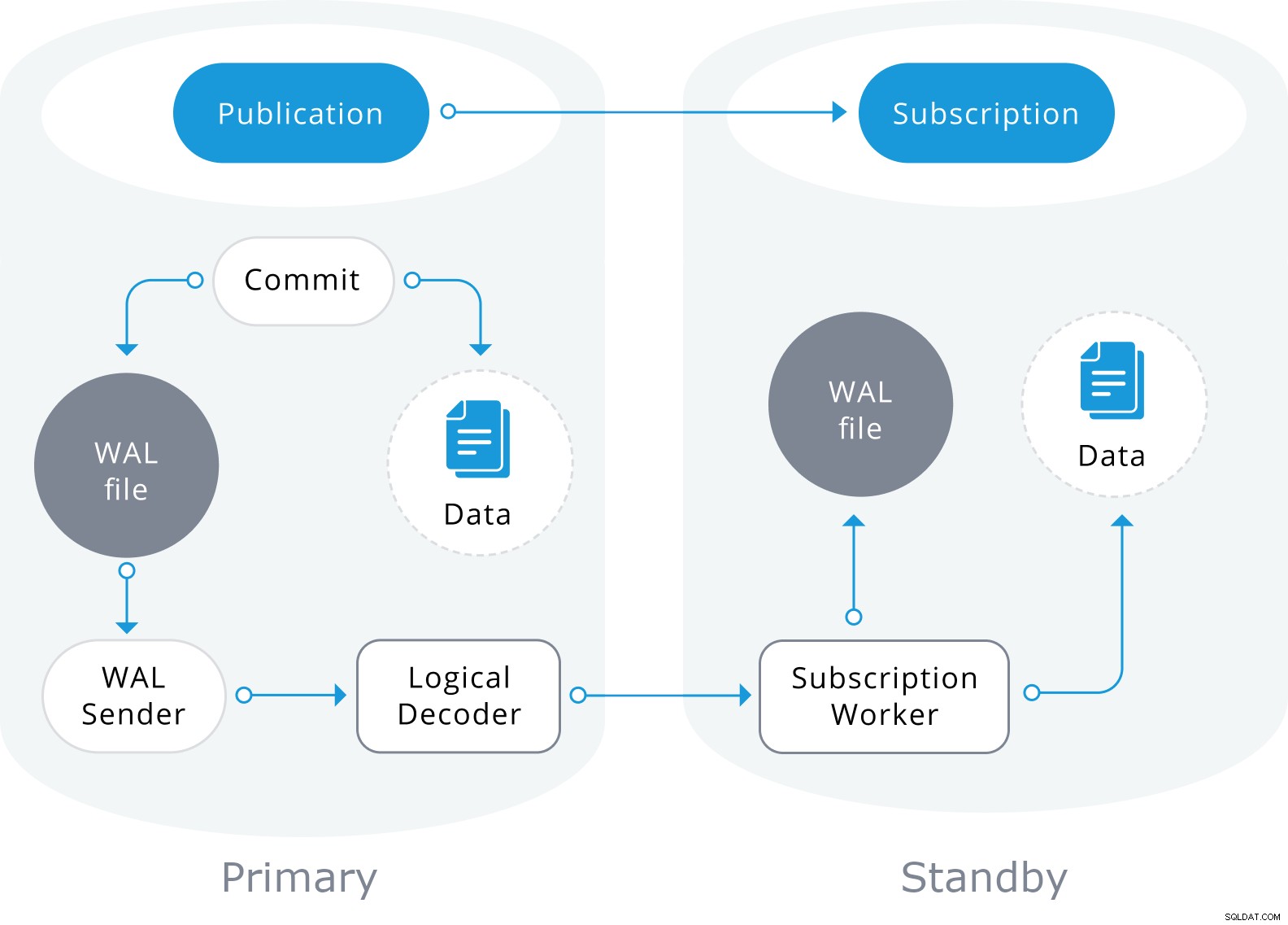
Logisk replikering starter med at tage et øjebliksbillede af dataene i udgiverdatabasen og kopiere det til abonnenten. De indledende data i de eksisterende tilmeldte tabeller tages snapshots og kopieres i en parallel instans af en særlig form for ansøgningsproces. Denne proces vil oprette sin egen midlertidige replikeringsplads og kopiere de eksisterende data. Når de eksisterende data er kopieret, går arbejderen i synkroniseringstilstand, som sikrer, at tabellen bringes op til en synkroniseret tilstand med hovedanvendelsesprocessen ved at streame ændringer, der skete under den indledende datakopiering, ved hjælp af standard logisk replikering. Når synkroniseringen er udført, bliver kontrollen over replikeringen af tabellen givet tilbage til hovedanvendelsesprocessen, hvor replikeringen fortsætter som normalt. Ændringerne på udgiveren sendes til abonnenten, efterhånden som de sker i realtid.
replikeringstilstande i PostgreSQL
Replikeringen i PostgreSQL kan være synkron eller asynkron.
Asynkron replikering
Det er standardtilstanden. Her er det muligt at få foretaget nogle transaktioner i den primære node, som endnu ikke er replikeret til standby-serveren. Dette betyder, at der er mulighed for et potentielt datatab. Denne forsinkelse i commit-processen formodes at være meget lille, hvis standby-serveren er kraftig nok til at holde trit med belastningen. Hvis denne lille risiko for tab af data ikke er acceptabel i virksomheden, kan du bruge synkron replikering i stedet.
Synkron replikering
Hver commit af en skrivetransaktion vil vente indtil bekræftelsen af, at commit er blevet skrevet til skrive-ahead-log på disken på både den primære og standby-server. Denne metode minimerer muligheden for tab af data. For at tabe data skal ske, skal både den primære og standbyen mislykkes på samme tid.
Ulempen ved denne metode er den samme for alle synkrone metoder, da svartiden for hver skrivetransaktion med denne metode øges. Dette skyldes behovet for at vente, indtil alle bekræftelser på, at transaktionen blev begået. Heldigvis vil skrivebeskyttede transaktioner ikke blive påvirket af dette, men; kun skrivetransaktionerne.
Høj tilgængelighed til PostgreSQL-replikering
Høj tilgængelighed er et krav for mange systemer, uanset hvilken teknologi vi bruger, og der er forskellige tilgange til at opnå dette ved hjælp af forskellige værktøjer.
Belastningsbalancering
Load balancers er værktøjer, der kan bruges til at styre trafikken fra din applikation for at få mest muligt ud af din databasearkitektur. Ikke alene er det nyttigt til at afbalancere belastningen af vores databaser, det hjælper også applikationer med at blive omdirigeret til de tilgængelige/sunde noder og endda specificere porte med forskellige roller.
HAProxy er en belastningsbalancer, der distribuerer trafik fra én oprindelse til en eller flere destinationer og kan definere specifikke regler og/eller protokoller for denne opgave. Hvis en af destinationerne holder op med at svare, markeres den som offline, og trafikken sendes til resten af de tilgængelige destinationer. Kun én Load Balancer-knude vil generere et enkelt fejlpunkt, så for at undgå dette bør du implementere mindst to HAProxy-noder og konfigurere Keepalved mellem dem.
Keelived er en tjeneste, der giver os mulighed for at konfigurere en virtuel IP inden for en aktiv/passiv gruppe af servere. Denne virtuelle IP er tildelt en aktiv server. Hvis denne server fejler, migreres IP'en automatisk til den "Sekundære" passive server, så den kan fortsætte med at arbejde med den samme IP på en gennemsigtig måde for systemerne.
Forbedring af ydeevne på PostgreSQL-replikering
Ydeevne er altid vigtig i ethvert system. Du bliver nødt til at gøre god brug af de tilgængelige ressourcer for at sikre den bedst mulige responstid, og der er forskellige måder at gøre dette på. Hver forbindelse til en database bruger ressourcer, så en af måderne til at forbedre ydeevnen på din PostgreSQL-database er ved at have en god forbindelsespooler mellem din applikation og databaseserverne.
Connection Poolers
En forbindelsespooling er en metode til at skabe en pulje af forbindelser og genbruge dem, så man undgår at åbne nye forbindelser til databasen hele tiden, hvilket vil øge ydeevnen af dine applikationer betydeligt. PgBouncer er en populær forbindelsespooler designet til PostgreSQL.
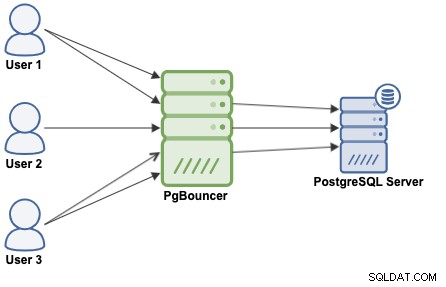
PgBouncer fungerer som en PostgreSQL-server, så du skal bare have adgang til din database ved at bruge PgBouncer-oplysningerne (IP-adresse/værtsnavn og port), og PgBouncer vil oprette en forbindelse til PostgreSQL-serveren, eller den vil genbruge en, hvis den findes.
Når PgBouncer modtager en forbindelse, udfører den godkendelsen, som afhænger af metoden specificeret i konfigurationsfilen. PgBouncer understøtter alle de godkendelsesmekanismer, som PostgreSQL-serveren understøtter. Herefter søger PgBouncer for en cache-forbindelse med den samme brugernavn+databasekombination. Hvis der findes en cachelagret forbindelse, returnerer den forbindelsen til klienten, hvis ikke, opretter den en ny forbindelse. Afhængigt af PgBouncer-konfigurationen og antallet af aktive forbindelser, kan det være muligt, at den nye forbindelse er i kø, indtil den kan oprettes eller endda afbrydes.
Med alle disse nævnte koncepter vil vi i anden del af denne blog se, hvordan du kan kombinere dem for at få et godt replikeringsmiljø i PostgreSQL.