Høj tilgængelighed er et krav for stort set alle virksomheder rundt om i verden, der bruger PostgreSQL. Det er velkendt, at PostgreSQL bruger Streaming Replication som replikeringsmetode. PostgreSQL Streaming Replikering er som standard asynkron, så det er muligt at have nogle transaktioner begået i den primære node, som endnu ikke er blevet replikeret til standby-serveren. Det betyder, at der er mulighed for potentielt datatab.
Denne forsinkelse i commit-processen formodes at være meget lille... hvis standby-serveren er kraftig nok til at holde trit med belastningen. Hvis denne lille risiko for tab af data ikke er acceptabel i virksomheden, kan du også bruge synkron replikering i stedet for standarden.
I synkron replikering vil hver commit af en skrivetransaktion vente, indtil bekræftelsen af, at commit er blevet skrevet til skrive-ahead-log på disken på både den primære server og standby-serveren.
Denne metode minimerer muligheden for tab af data. For at tabe data skal ske, skal både den primære og standbyen mislykkes på samme tid.
Ulempen ved denne metode er den samme for alle synkrone metoder, da svartiden for hver skrivetransaktion med denne metode øges. Dette skyldes behovet for at vente, indtil alle bekræftelser på, at transaktionen blev begået. Heldigvis vil skrivebeskyttede transaktioner ikke blive påvirket af dette, men; kun skrivetransaktionerne.
I denne blog viser du dig, hvordan du installerer en PostgreSQL-klynge fra bunden, konverterer den asynkrone replikering (standard) til en synkron. Jeg vil også vise dig, hvordan du ruller tilbage, hvis responstiden ikke er acceptabel, da du nemt kan gå tilbage til den tidligere tilstand. Du vil se, hvordan du nemt kan implementere, konfigurere og overvåge en PostgreSQL synkron replikering ved hjælp af ClusterControl ved kun at bruge ét værktøj til hele processen.
Installation af en PostgreSQL-klynge
Lad os begynde at installere og konfigurere en asynkron PostgreSQL-replikering, det er den sædvanlige replikeringstilstand, der bruges i en PostgreSQL-klynge. Vi vil bruge PostgreSQL 11 på CentOS 7.
PostgreSQL-installation
I overensstemmelse med den officielle PostgreSQL installationsvejledning er denne opgave ret enkel.
Installer først depotet:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstaller PostgreSQL-klienten og serverpakkerne:
$ yum install postgresql11 postgresql11-serverInitialiser databasen:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11På standby-noden kan du undgå den sidste kommando (start databasetjenesten), da du vil gendanne en binær sikkerhedskopi for at oprette streamingreplikeringen.
Lad os nu se den konfiguration, der kræves af en asynkron PostgreSQL-replikering.
Konfiguration af asynkron PostgreSQL-replikering
Opsætning af primær node
I den primære PostgreSQL-knude skal du bruge følgende grundlæggende konfiguration for at oprette en Async-replikering. Filerne, der vil blive ændret, er postgresql.conf og pg_hba.conf. Generelt er de i databiblioteket (/var/lib/pgsql/11/data/), men du kan bekræfte det på databasesiden:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Rediger eller tilføj følgende parametre i postgresql.conf-konfigurationsfilen.
Her skal du tilføje den eller de IP-adresser, hvor du kan lytte til. Standardværdien er 'localhost', og i dette eksempel bruger vi '*' for alle IP-adresser på serveren.
listen_addresses = '*' Indstil serverporten, hvor der skal lyttes. Som standard 5432.
port = 5432 Beslut, hvor meget information der skrives til WAL'erne. De mulige værdier er minimale, replika eller logiske. Hot_standby-værdien er knyttet til replika, og den bruges til at bevare kompatibiliteten med tidligere versioner.
wal_level = hot_standby Indstil det maksimale antal walsender-processer, som styrer forbindelsen med en standby-server.
max_wal_senders = 16Indstil minimumsmængden af WAL-filer, der skal opbevares i pg_wal-mappen.
wal_keep_segments = 32Ændring af disse parametre kræver en genstart af databasetjenesten.
$ systemctl restart postgresql-11Pg_hba.conf
Rediger eller tilføj følgende parametre i pg_hba.conf-konfigurationsfilen.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Som du kan se, skal du her tilføje brugeradgangstilladelsen. Den første kolonne er forbindelsestypen, der kan være vært eller lokal. Derefter skal du angive database (replikering), bruger, kilde-IP-adresse og godkendelsesmetode. Ændring af denne fil kræver en genindlæsning af databasetjenesten.
$ systemctl reload postgresql-11Du bør tilføje denne konfiguration i både primære og standby-noder, da du får brug for den, hvis standby-knuden forfremmes til master i tilfælde af fejl.
Nu skal du oprette en replikeringsbruger.
Replikeringsrolle
ROLEN (brugeren) skal have REPLICATION-rettigheder for at bruge den i streaming-replikeringen.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEEfter konfiguration af de tilsvarende filer og brugeroprettelse, skal du oprette en konsekvent sikkerhedskopi fra den primære node og gendanne den på standby-knuden.
Opsætning af standby node
På standby-knudepunktet, gå til /var/lib/pgsql/11/-biblioteket og flyt eller fjern det aktuelle datakatalog:
$ cd /var/lib/pgsql/11/
$ mv data data.bkKør derefter kommandoen pg_basebackup for at hente den aktuelle primære datadir og tildele den korrekte ejer (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataNu skal du bruge følgende grundlæggende konfiguration for at oprette en Asynkron replikering. Filen, der vil blive ændret, er postgresql.conf, og du skal oprette en ny recovery.conf-fil. Begge vil være placeret i /var/lib/pgsql/11/.
Recovery.conf
Specificer, at denne server vil være en standby-server. Hvis den er tændt, vil serveren fortsætte med at gendanne ved at hente nye WAL-segmenter, når slutningen af arkiveret WAL er nået.
standby_mode = 'on'Angiv en forbindelsesstreng, der skal bruges til, at standbyserveren kan oprette forbindelse til den primære node.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Angiv gendannelse til en bestemt tidslinje. Standarden er at gendanne langs den samme tidslinje, som var aktuel, da den grundlæggende backup blev taget. Indstilling af dette til "senest" gendannes til den seneste tidslinje fundet i arkivet.
recovery_target_timeline = 'latest'Angiv en triggerfil, hvis tilstedeværelse afslutter gendannelsen i standby.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Rediger eller tilføj følgende parametre i postgresql.conf-konfigurationsfilen.
Beslut hvor meget information der skrives til WAL'erne. De mulige værdier er minimale, replika eller logiske. Hot_standby-værdien er knyttet til replika, og den bruges til at bevare kompatibiliteten med tidligere versioner. Ændring af denne værdi kræver en genstart af tjenesten.
wal_level = hot_standbyTillad forespørgslerne under gendannelse. Ændring af denne værdi kræver en genstart af tjenesten.
hot_standby = onStarter Standby Node
Nu har du al den nødvendige konfiguration på plads, du skal bare starte databasetjenesten på standby-knuden.
$ systemctl start postgresql-11Og tjek databasens logfiler i /var/lib/pgsql/11/data/log/. Du burde have noget som dette:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Du kan også kontrollere replikeringsstatussen i den primære node ved at køre følgende forespørgsel:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Som du kan se, bruger vi en asynkron replikering.
Konvertering af asynkron PostgreSQL-replikering til synkron replikering
Nu er det tid til at konvertere denne asynkron-replikering til en synkronisering, og til dette skal du konfigurere både den primære og standby-knuden.
Primær node
I den primære PostgreSQL-knude skal du bruge denne grundlæggende konfiguration ud over den tidligere asynkrone konfiguration.
Postgresql.conf
Angiv en liste over standby-servere, der kan understøtte synkron replikering. Dette standby-servernavn er indstillingen application_name i standbyens recovery.conf-fil.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Specificerer, om transaktionsbekræftelse vil vente på, at WAL-poster bliver skrevet til disken, før kommandoen returnerer en "succes"-indikation til klienten. De gyldige værdier er on, remote_apply, remote_write, local og off. Standardværdien er slået til.
synchronous_commit = onOpsætning af standby node
I PostgreSQL standby-noden skal du ændre filen recovery.conf ved at tilføje 'application_name-værdien i parameteren primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Genstart databasetjenesten i både den primære og i standby-knuden:
$ service postgresql-11 restartNu skulle du have din synkroniseringsstreamingreplikering op at køre:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Tilbageføring fra synkron til asynkron PostgreSQL-replikering
Hvis du har brug for at gå tilbage til asynkron PostgreSQL-replikering, skal du blot rulle de ændringer, der er udført i postgresql.conf-filen på den primære node:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onOg genstart databasetjenesten.
$ service postgresql-11 restartSå nu skulle du have asynkron replikering igen.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Sådan installeres en PostgreSQL Synchronous Replikation ved hjælp af ClusterControl
Med ClusterControl kan du udføre installations-, konfigurations- og overvågningsopgaverne alt-i-én fra det samme job, og du vil være i stand til at administrere det fra den samme brugergrænseflade.
Vi antager, at du har ClusterControl installeret, og at den kan få adgang til databasenoderne via SSH. For mere information om, hvordan du konfigurerer ClusterControl-adgangen, se venligst vores officielle dokumentation.
Gå til ClusterControl og brug muligheden "Deploy" til at oprette en ny PostgreSQL-klynge.
Når du vælger PostgreSQL, skal du angive bruger, nøgle eller adgangskode og en port for at forbinde med SSH til vores servere. Du skal også have et navn til din nye klynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
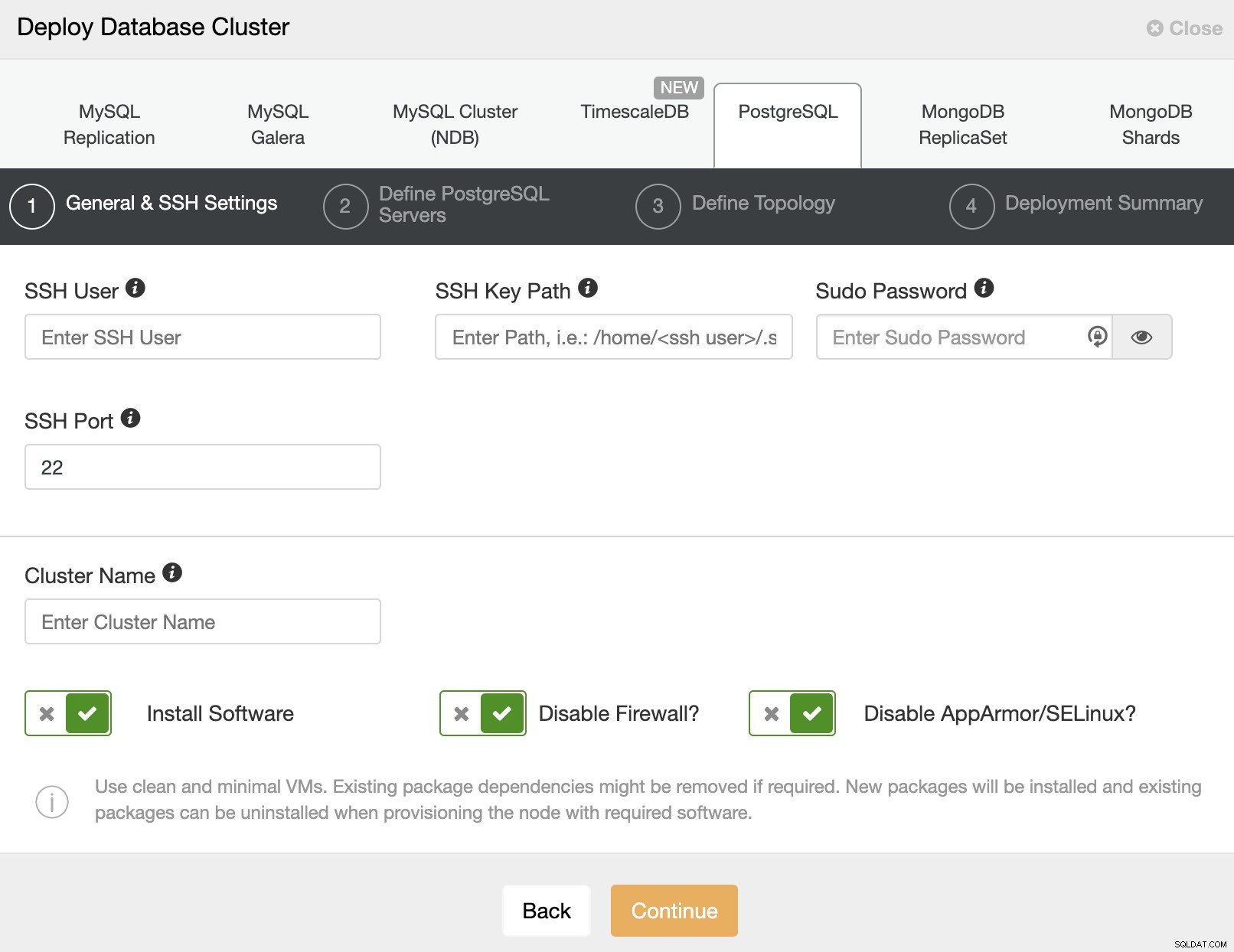
Efter opsætning af SSH-adgangsoplysningerne skal du indtaste dataene for at få adgang din database. Du kan også angive, hvilket lager der skal bruges.
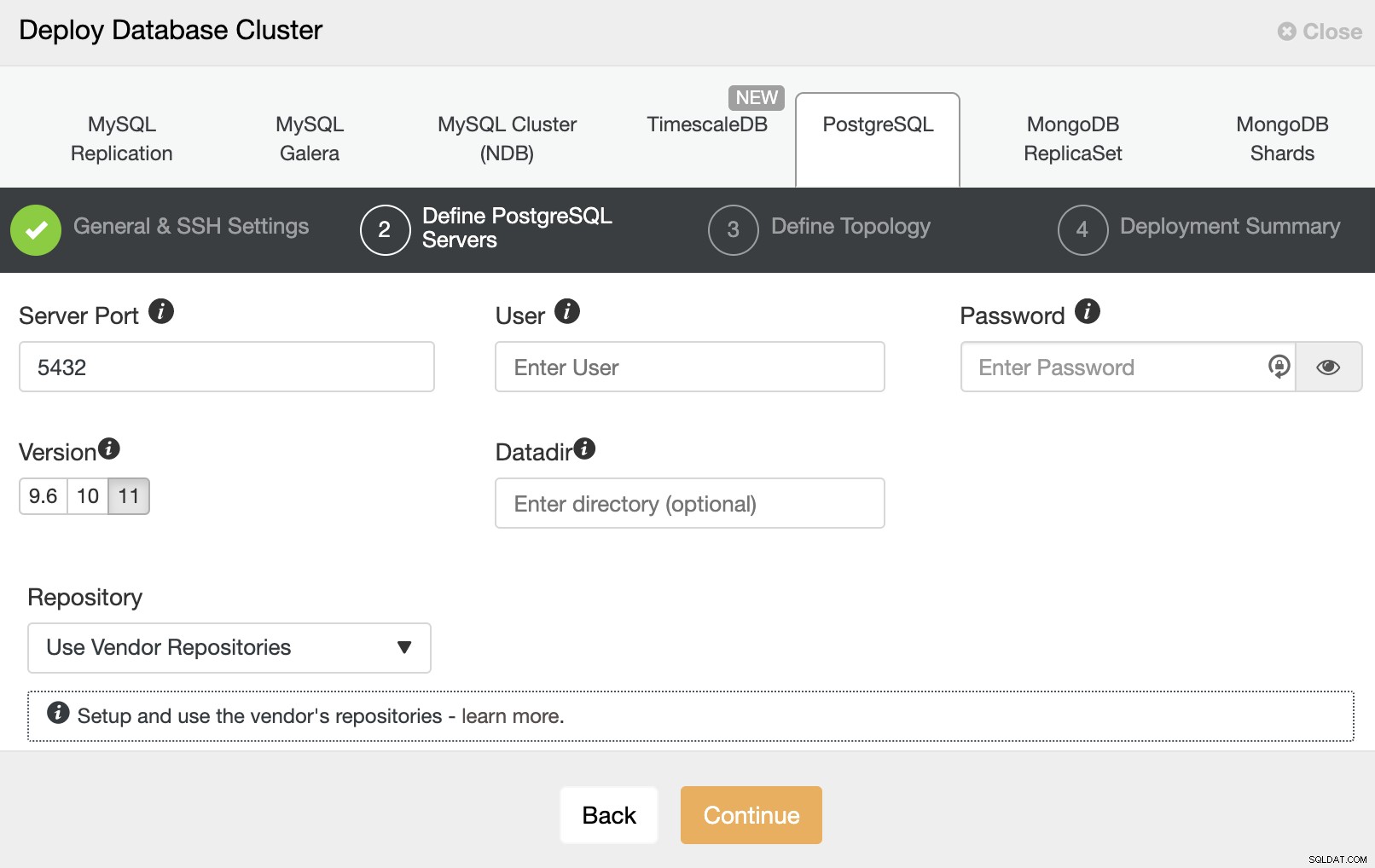
I næste trin skal du tilføje dine servere til klyngen, der du kommer til at skabe. Når du tilføjer dine servere, kan du indtaste IP eller værtsnavn.
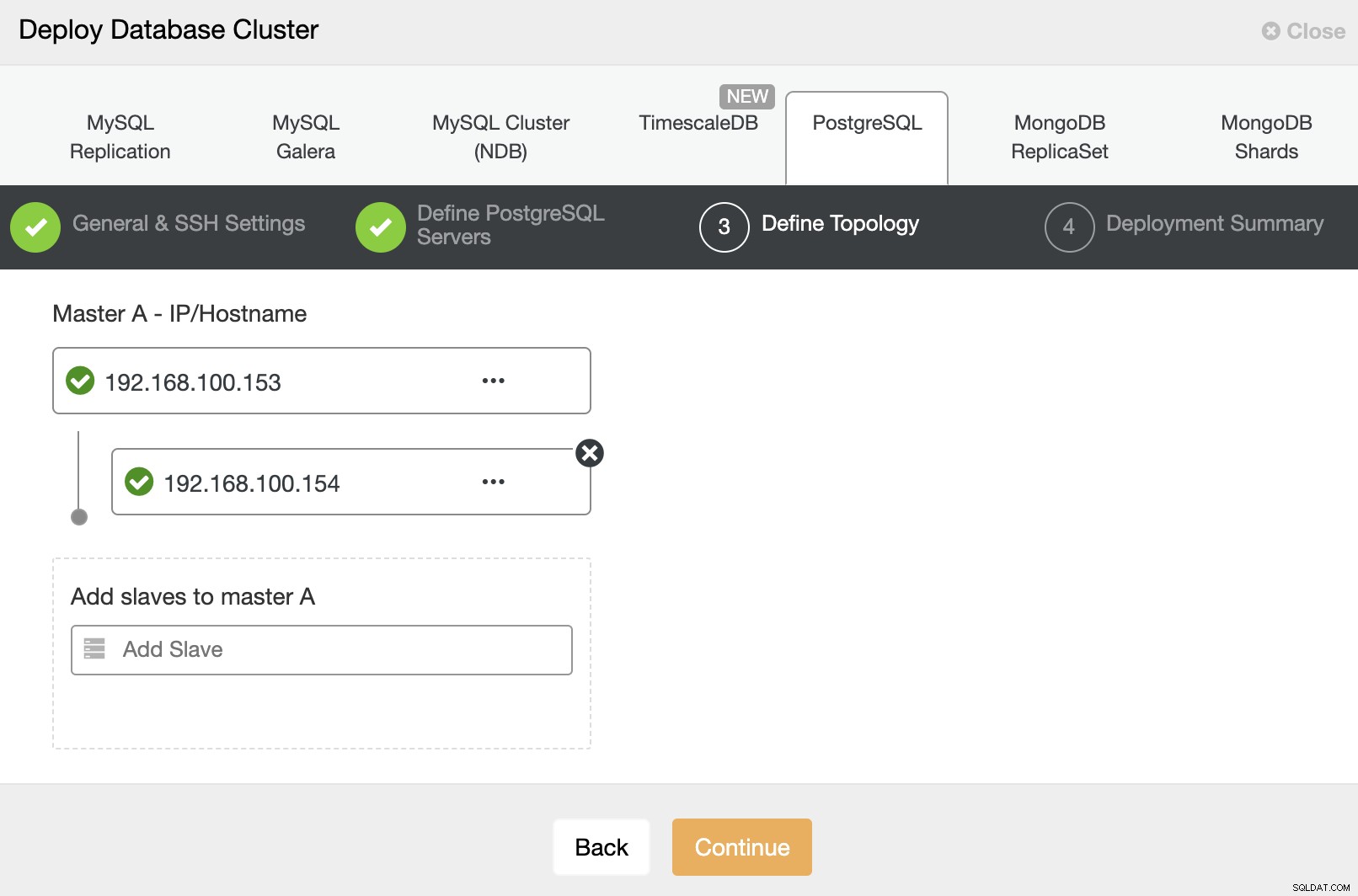
Og til sidst, i det sidste trin, kan du vælge replikeringsmetoden, som kan være asynkron eller synkron replikering.
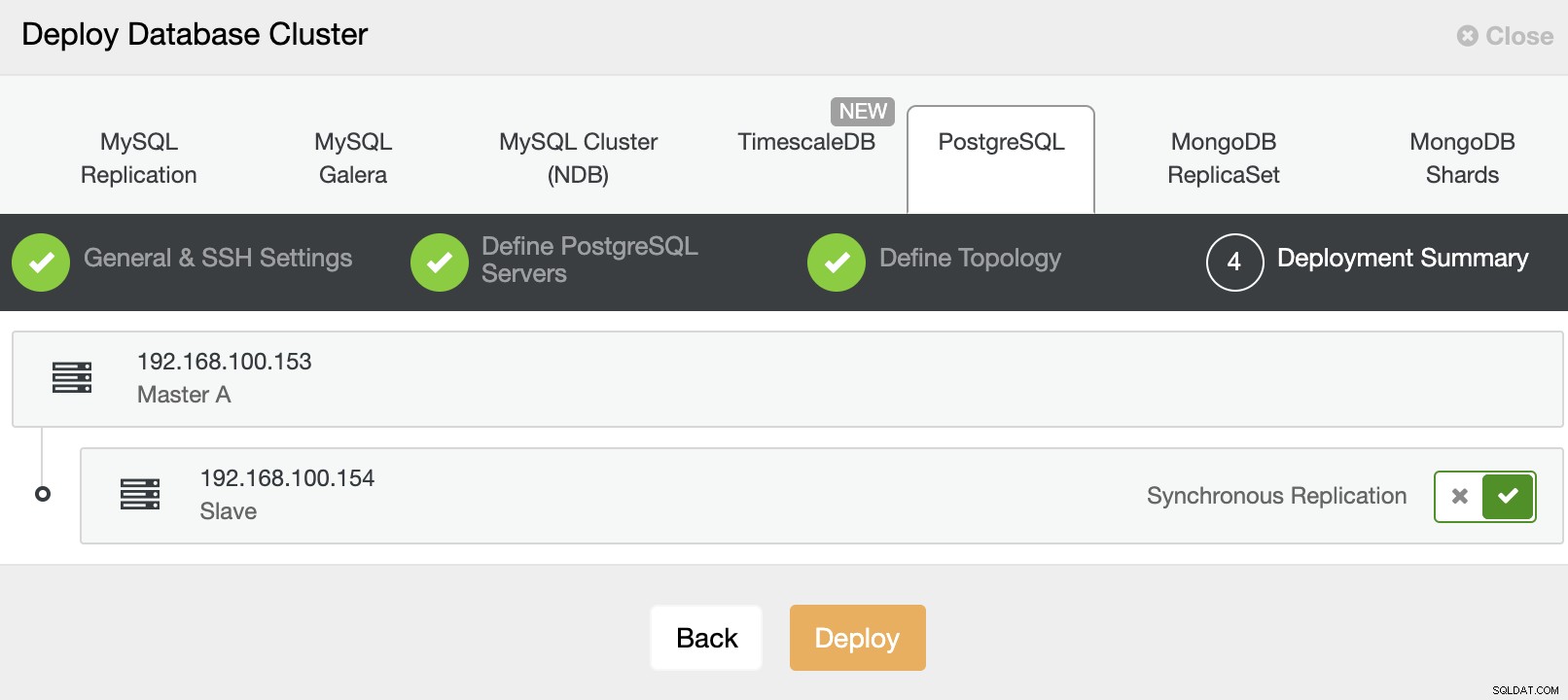
Det var det. Du kan overvåge jobstatus i afsnittet ClusterControl-aktivitet.
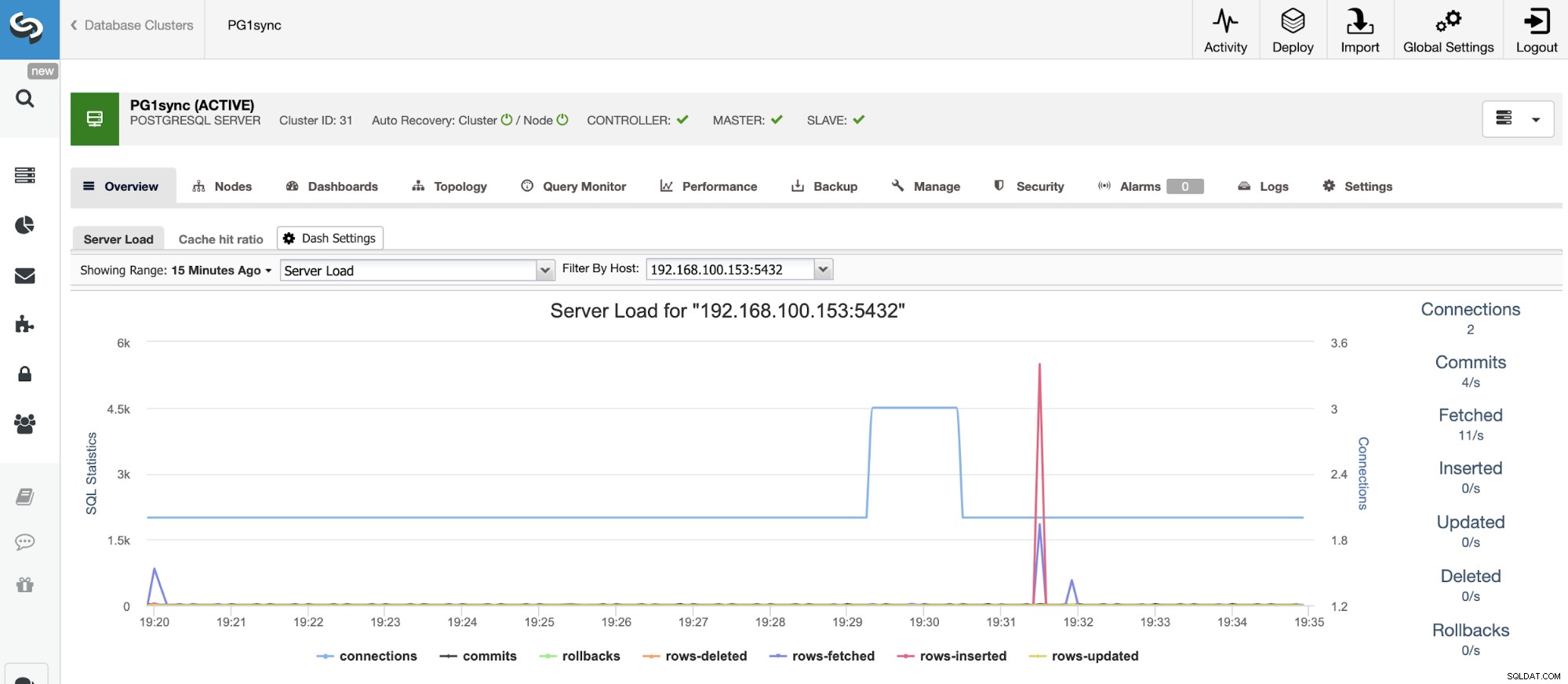
Og når dette job er færdigt, vil du have din PostgreSQL synkrone klynge installeret, konfigureret og overvåget af ClusterControl.
Konklusion
Som vi nævnte i begyndelsen af denne blog, er høj tilgængelighed et krav for alle virksomheder, så du bør kende de tilgængelige muligheder for at opnå det for hver teknologi, der bruges. For PostgreSQL kan du bruge synkron streaming-replikering som den sikreste måde at implementere det på, men denne metode virker ikke for alle miljøer og arbejdsbelastninger.
Vær forsigtig med den forsinkelse, der genereres ved at vente på bekræftelsen af hver transaktion, der kunne være et problem i stedet for en High Availability-løsning.