I denne Hadoop tutorial , vil vi give dig en detaljeret beskrivelse af Hadoop Combiner. Først og fremmest vil vi se, hvad der er MapReduce Combiner, hvad der er nøglerollen for Combiner i MapReduce.
Derefter vil vi diskutere eksemplet med MapReduce-programmet med og uden combiner i Hadoop. Til sidst vil vi også se nogle fordele og ulemper ved Combiner i MapReduce.
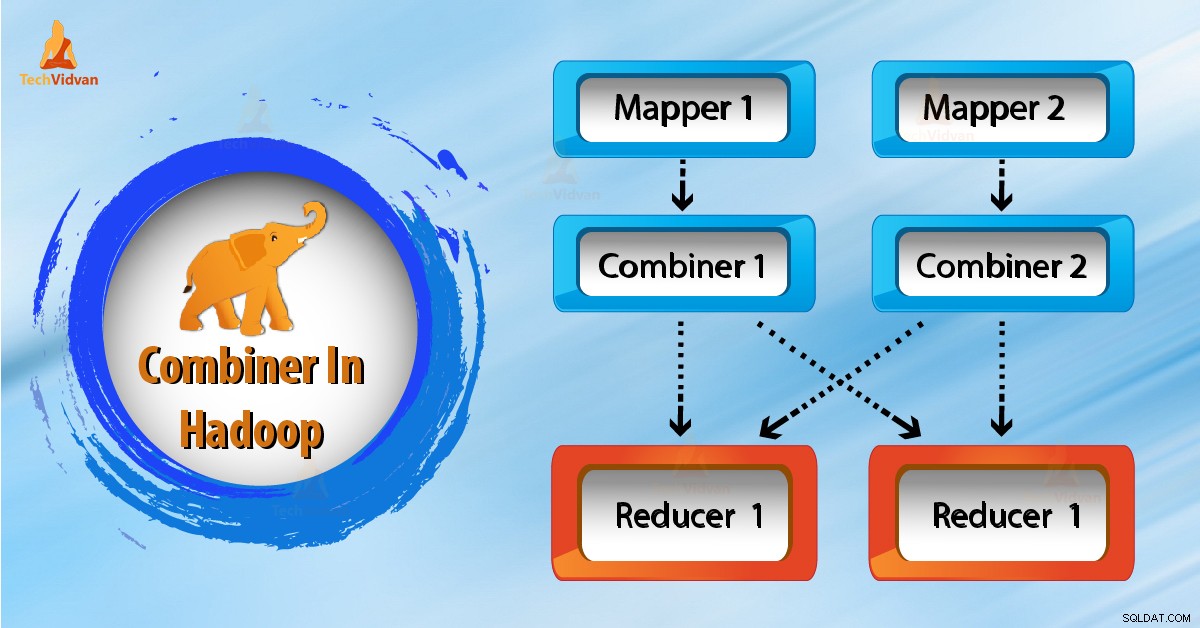
Hvad er Hadoop Combiner?
Kombinator er også kendt som "Mini-Reducer ”, der opsummerer Mapper output record med den samme nøgle, før du går til Reducer .
På et stort datasæt, når vi kører MapReduce job. Så Mapper genererer store bidder af mellemliggende data. Derefter sender frameworket disse mellemliggende data til Reduceren til yderligere behandling.
Dette fører til enorm overbelastning af netværket. Hadoop-rammen giver en funktion kendt som Combiner der spiller en nøglerolle i at reducere overbelastning af netværket.
Den primære opgave for Combiner en "Mini-Reducer er at behandle outputdata fra Mapper, før de overføres til Reducer. Den kører efter kortlæggeren og før reducereren. Dens brug er valgfri.
Hvordan fungerer Combiner i Hadoop?
Lad os nu lære, hvordan tingene ændrer sig, når vi bruger combineren i MapReduce?

Som vi ser i ovenstående diagram, er der ingen kombinator. Input er opdelt i to kortlæggere. Rammen genererer 9 nøgler fra kortlæggerne.
Så nu har vi (9 nøgle/værdi) mellemdata. Yderligere mapper sender denne nøgleværdi direkte til reduktionsgearet. Mens den sender data til reducereren, bruger den noget netværksbåndbredde. Det tager længere tid at overføre data til reducering, hvis datastørrelsen er stor.

Nu fra ovenstående diagram, hvis vi bruger en combiner mellem mapper og reducer. Så vil combiner blande 9 nøgle/værdi, før den sendes til reduceringen. Og genererer derefter 4 nøgle/værdipar som output.
Nu behøver Reducer kun at behandle 4 nøgle/værdi par data, som er genereret fra 2 kombinerere. Derfor udføres reducer kun 4 gange for at producere det endelige output. Dette øger således den samlede ydeevne.
Fordele ved Combiner i MapReduce
Lad os nu diskutere fordelene ved Hadoop Combiner i MapReduce.
- Brug af combiner reducerer den tid, det tager for dataoverførsel mellem mapper og reducer.
- Kombinator forbedrer reduktionens overordnede ydeevne.
- Det reducerer mængden af data, som reducer skal behandle.
Ulemper ved Combiner i MapReduce
Der er også nogle ulemper ved Hadoop Combiner. Lad os nu diskutere det samme.
- I det lokale filsystem, når Hadoop gemmer nøgleværdi-parrene og kører combineren senere, vil dette forårsage dyr disk IO.
- MapReduce-job kan ikke afhænge af combiner-udførelsen, da der ikke er nogen garanti for dens udførelse.
Konklusion
Derfor spiller Hadoop Combiner en nøglerolle i at reducere overbelastning af netværket. Det forbedrer reducererens overordnede ydeevne ved at opsummere output fra Mapper.
Jeg håber, at du nu har en klar forståelse af Hadoop Combiner. Hvis du stadig har spørgsmål, så lad os det vide, og læg en kommentar i et afsnit nedenfor.