Hovedmålet med denneHadoop Tutorial er at give dig en detaljeret beskrivelse af hver komponent, der bruges i Hadoop-arbejde. I denne tutorial skal vi dække Partitioner i Hadoop.
Hvad er Hadoop Partitioner, hvad er behovet for Partitioner i Hadoop, Hvad er standardpartitioner i MapReduce, hvor mange MapReduce Partitioner bruges i Hadoop?
Vi vil besvare alle disse spørgsmål i denne MapReduce-tutorial.
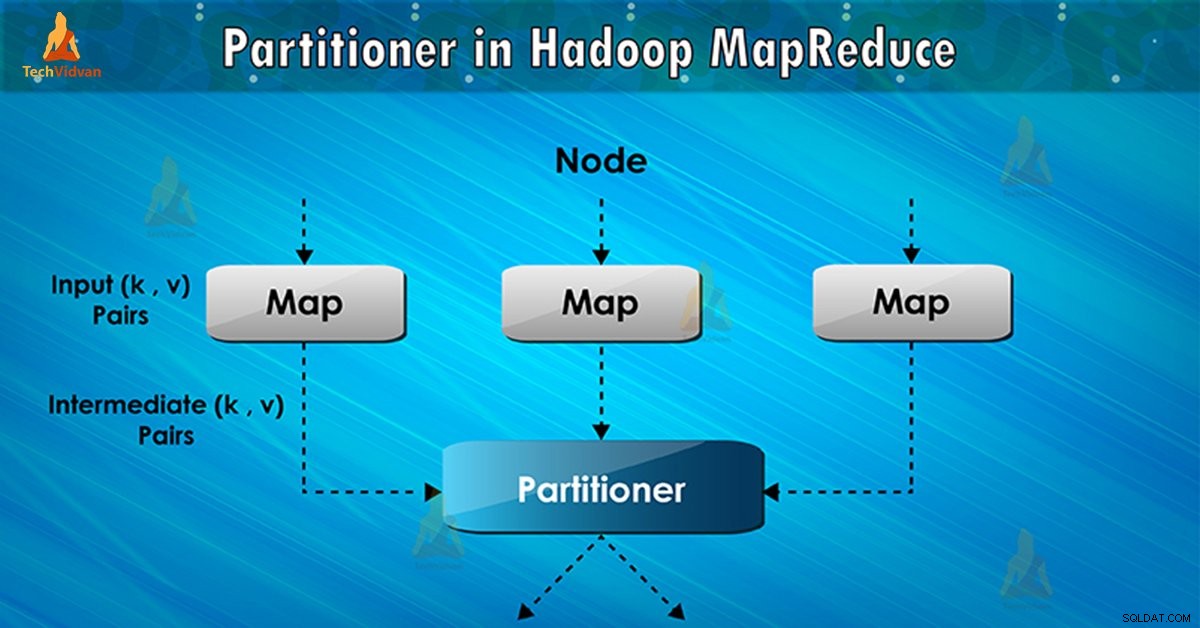
Hvad er Hadoop Partitioner?
Partitioner i MapReduce-jobkørsel styrer partitioneringen af nøglerne til de mellemliggende kortudgange. Ved hjælp af hash-funktionen udleder nøglen (eller en delmængde af nøglen) partitionen. Det samlede antal partitioner er lig med antallet af reducerede opgaver.
På baggrund af nøgleværdi , framework-partitioner, hvermapper produktion. Poster, der har den samme nøgleværdi, går ind i den samme partition (inden for hver mapper). Derefter sendes hver partition til en reducer .
Partitionsklassen bestemmer, hvilken partition et givet (nøgle, værdi) par vil gå til. Opdelingsfasen i MapReduce dataflow finder sted efter kortfasen og før reduceringsfasen.
Behov for MapReduce Partitioner i Hadoop
I MapReduce-jobkørsel tager den et inputdatasæt og producerer listen over nøgleværdipar. Disse nøgleværdi-par er resultatet af kortfasen. I hvilke inputdata er opdelt, og hver opgave behandler opdelingen, og hvert kort udlæser listen over nøgleværdipar.
Derefter sender framework kortets output for at reducere opgaven. Reducer processer den brugerdefinerede reduktionsfunktion på kortudgange. Inden reduktionsfasen sker opdeling af kortets output på basis af nøglen.
Hadoop Partitioning specificerer, at alle værdierne for hver nøgle er grupperet sammen. Det sørger også for, at alle værdierne af en enkelt nøgle går til den samme reducer. Dette tillader en jævn fordeling af kortets output over reducereren.
Partitioner i et MapReduce-job omdirigerer mapper-output til reducer ved at bestemme, hvilken reducer der håndterer den bestemte nøgle.
Hadoop Default Partitioner
Hash Partitioner er standardpartitioner. Den beregner en hashværdi for nøglen. Den tildeler også partitionen baseret på dette resultat.
Hvor mange partitioner i Hadoop?
Det samlede antal partitioner afhænger af antallet af reduktionselementer. Hadoop Partitioner opdeler dataene i henhold til antallet af reducering. Det er indstillet af JobConf.setNumReduceTasks() metode.
Således behandler den enkelte reducering dataene fra en enkelt partitioner. Det vigtige at bemærke er, at rammen kun opretter partitioner, når der er mange reducering.
Dårlig partitionering i Hadoop MapReduce
Hvis der er indlæst data i MapReduce-job, vises én tast mere end nogen anden tast. I sådanne tilfælde bruger vi to mekanismer til at sende data til partitionen:
- Nøglen, der vises flere gange, sendes til én partition.
- Alle de andre nøgler vil blive sendt til partitioner på basis af deres hashCode() .
Hvis hashCode() metoden distribuerer ikke andre nøgledata over partitionsområdet. Så vil data ikke blive sendt til reduktionsgearene.
Dårlig opdeling af data betyder, at nogle reducerere vil have mere datainput sammenlignet med andre. De vil have mere arbejde at gøre end andre reduktionsapparater. Derfor skal hele jobbet vente på, at en reduktionsanordning afslutter sin ekstra store del af belastningen.
Hvordan overvinder man dårlig partitionering i MapReduce?
For at overvinde dårlig partitionering i Hadoop MapReduce kan vi oprette Custom partitioner. Dette gør det muligt at dele arbejdsbyrden på tværs af forskellige reducering.
Konklusion
Som konklusion tillader Partitioner ensartet fordeling af kortets output over reducereren. I MapReducer Partitioner foregår partitionering af kortoutput på basis af nøglen og værdien.
Derfor har vi dækket den komplette oversigt over Partitioner i denne blog. Håber du kunne lide det. Hvis du er i tvivl om Hadoop Partitioner, så glem ikke at dele med os.