Dette Hadoop selvstudie handler om MapReduce Shuffling og Sortering. Her giver vi dig en detaljeret beskrivelse af Hadoop-blandings- og sorteringsfasen.
Først vil vi diskutere, hvad der er MapReduce Shuffling, derefter med MapReduce Sorting, derefter vil vi dække MapReduce sekundære sorteringsfase i detaljer.
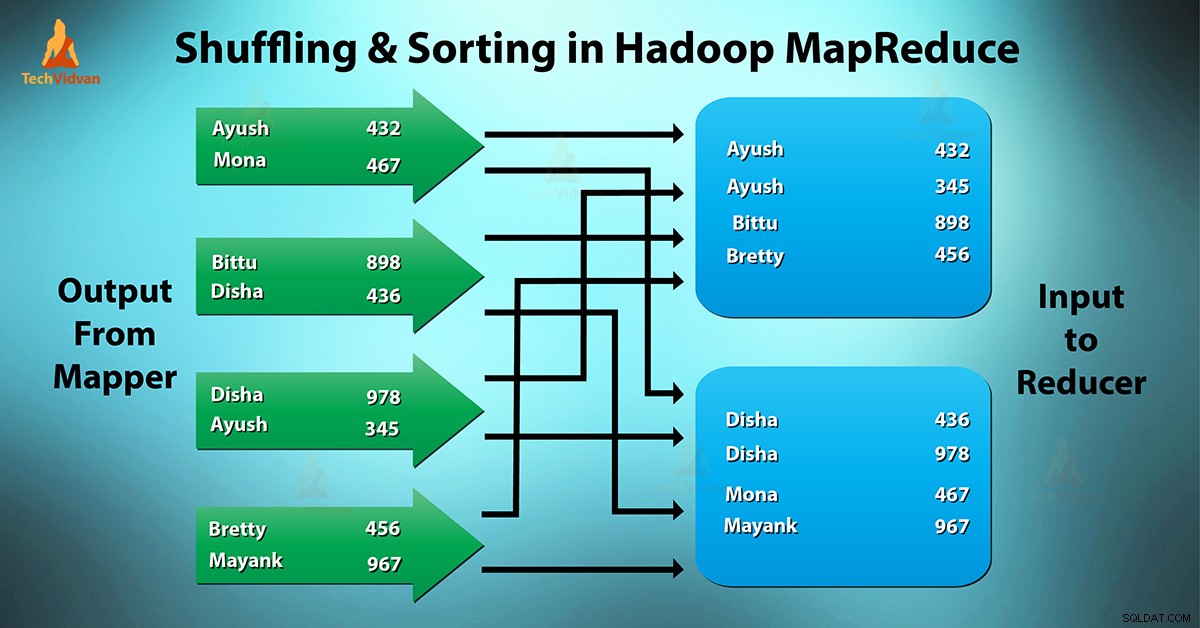
Hvad er MapReduce Blanding og sortering?
Blander er den proces, hvorved den overførerkortlæggere mellemudgang til reduceren. Reducer får 1 eller flere nøgler og tilhørende værdier på basis af reducers.
Den mellemliggende nøgle – værdi genereret af mapper sorteres automatisk efter nøgle. I Sorter fase sker sammensmeltning og sortering af kortoutput.
Blanding og sortering i Hadoop foregår samtidigt.
Blander i MapReduce
Processen med at overføre data fra kortlæggerne til reduceringerne blander sig. Det er også den proces, hvorved systemet udfører sorteringen. Derefter overfører den kortudgangen til reducereren som input. Dette er grunden til, at shuffle-fasen er nødvendig for reduceringerne.
Ellers ville de ikke have noget input (eller input fra hver mapper). Da shuffling kan starte, selv før kortfasen er afsluttet. Så dette sparer noget tid og fuldfører opgaverne på kortere tid.
Sortering i MapReduce
MapReduce Framework sorterer automatisk de nøgler, der er genereret af mapperen. Før start af reducering bliver alle mellemliggende nøgle-værdi-par således sorteret efter nøgle og ikke efter værdi. Den sorterer ikke værdier, der sendes til hver reducering. De kan være i enhver rækkefølge.
Sortering i et MapReduce-job hjælper reducer med nemt at skelne, hvornår en ny reduktionsopgave skal starte.
Dette sparer tid for reduktionen. Reducer i MapReduce starter en ny reduktionsopgave, når den næste nøgle i de sorterede inputdata er anderledes end den forrige. Hver reduktionsopgave tager nøgleværdipar som input og genererer nøgleværdipar som output.
Det vigtige at bemærke er, at blanding og sortering i Hadoop MapReduce er slet ikke vil finde sted, hvis du angiver nul-reducere (setNumReduceTasks(0)).
Hvis reducering er nul, stopper MapReduce-jobbet ved kortfasen. Og kortfasen inkluderer ikke nogen form for sortering (selv kortfasen er hurtigere).
Sekundær sortering i MapReduce
Hvis vi ønsker at sortere reduktionsværdier, så bruger vi en sekundær sorteringsteknik. Denne teknik gør det muligt for os at sortere værdierne (i stigende eller faldende rækkefølge), der sendes til hver reducering.
Konklusion
Som konklusion sker MapReduce Shuffling og Sortering samtidigt for at opsummere Mapper-mellemoutputtet. Hadoop Shuffling-Sorting vil ikke finde sted, hvis du angiver nul-reducere (setNumReduceTasks (0)).
Framework sorterer alle mellemliggende nøgleværdipar efter nøgle, ikke efter værdi. Den bruger sekundær sortering til sortering efter værdi. Hvis du har forslag eller forespørgsler relateret til MapReduce Shuffling and Sorting fase, så skriv venligst en kommentar i et kommentarfelt.
Vi vil med glæde løse dem.