I denneHadoop-tutorial , vil vi give dig en komplet introduktion af HDFS Federation. I dette selvstudie vil vi diskutere HDFS-arkitektur, begrænsninger af den nuværende arkitektur af HDFS.
Derefter vil vi dække HDFS Federation-arkitekturen i detaljer sammen med deres fordele i Hadoop-rammeværket.
Hvad er HDFS Federation?
Federation forbedrer en eksisterende Hadoop HDFS arkitektur. Tidligere HDFS-arkitektur tillader et enkelt navneområde for hele klyngen. I den arkitektur administrerer enkelt NameNode navneområdet.
Hvis NameNode fejler, vil hele klyngen være ude af drift. Og klyngen vil være utilgængelig, indtil NameNode genstarter eller bringes på en separat maskine.
HDFS Federation blev introduceret for at overvinde denne begrænsning. Det overvinder dette ved at tilføje understøttelse af mange NameNode/Namespaces til HDFS.
Nuværende HDFS-arkitektur
HDFS har to hovedlag angivet nedenfor:
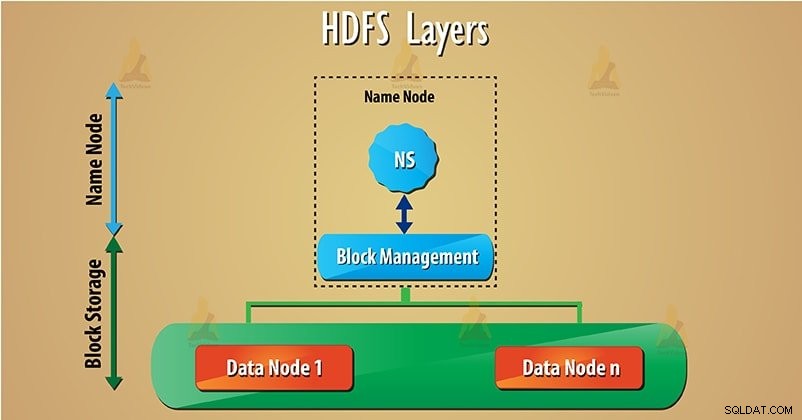
a) Navneområde – Dette lag administrerer filer, mapper og blokke . Dette lag understøtter grundlæggende filsystemdrift, såsom oprettelse, sletning af filer.
b) Bloker lagring – Den har to dele-
- Blokeradministration – Det understøtter blokrelateret operation såsom oprettelse, sletning af blokkene. Den administrerer dataknudepunkter i klyngen og tager sig af replikeringsstyring.
- Fysisk lagerplads – Dette gemmer blokkene på det lokale filsystem og giver adgang til læse- eller skriveoperationer. Følg dette link for at lære at læse og skrive HDFS-data.
Denne nuværende HDFS fungerer fint til mindre opsætninger. Men for store organisationer, hvor vi skal tage os af den enorme mængde data, har en vis begrænsning. Hadoop federation håndterer disse begrænsninger.
Begrænsning af nuværende HDFS-arkitektur
Begrænsning af nuværende HDFS-arkitektur er angivet nedenfor:
1. Tæt koblet bloklager og navneområde
Navneområdelag og lagerlag er tæt forbundet. Det gør alternativ implementering af namenode vanskelig. Og det begrænser andre tjenester til at bruge bloklagring.
2. Skalerbarhed for navneområde
Navnerummet er ikke skalerbart ligesom datanode. Skalering i HDFS-klynge er vandret ved at tilføje datanoder. Men vi kan ikke tilføje mere navneområde til en eksisterende klynge. Vi kan skalere navnerum lodret på en enkelt navnenod.
3. Ydeevne
Hele Hadoop-ydelsen afhænger af gennemstrømningen af namenode. En drift af det nuværende filsystem afhænger af gennemløbet af en enkelt navnenod. NameNode understøtter i øjeblikket 60.000 samtidige opgaver.
Kommende MapReduce vil have support til mere end 1.00.000 samtidige opgaver. Og dette vil kræve mere navneknude.
4. Isolering
Der er ingen adskillelse af navneområdet. Så der er ingen isolation blandt lejerorganisationer, der bruger klyngen.
HDFS Federation Architecture
Federation bruger mange uafhængige Namenode/navneområder til at skalere navnetjenesten vandret. Nederst i HDFS Federation Architecture er datanoder til stede. Og datanoder bruges som fælles lager for blokke af alle navnenoder.
Hver datanode registreres med alle navnenoder i klyngen. Disse datanoder sender periodiske hjerteslag, blokerer, rapporterer og håndterer kommandoer fra navnenoderne.
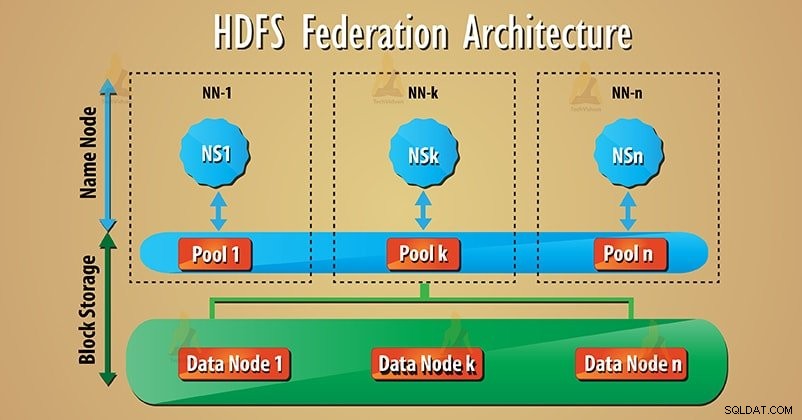
Mange navnenoder (NN1, NN2…, NNn) administrerer henholdsvis mange navnerum (NS1, NS2…, NSn). Hvert navneområde har sin egen blokpulje (NS1 Har pulje 1 og så videre). Blok fra pulje 1 er gemt på datanode 1 og så videre.
1. Bloker pool
Sæt af blokke er Blokpulje der hører til et enkelt navneområde. Der er en samling af puljer i HDFS føderationsarkitektur. Og hver blok styres fra den anden.
Dette giver et navneområde mulighed for at oprette et blok-id for nye blokke uden koordinering med et andet navneområde. Alle datanoder gemmer datablokke i alle blokpuljer.
2. Navneområdevolumen
Navneområde sammen med dets blokpulje er navneområdevolumen . Mange navnerumsvolumener er der i HDFS federation. Derfor fungerer hvert navnerumsvolumen uafhængigt. Når vi sletter navnenod eller navneområde, vil den tilsvarende blokpulje, der er til stede på datanoderne, også blive slettet.
Fordele ved HDFS Federation
HDFS Federation overvinder begrænsningerne ved tidligere HDFS-arkitektur. Derfor giver den:
- Isolation – Der er ingen isolation i en enkelt navneknude i et flerbrugermiljø. I HDFS federation kan forskellige kategorier af applikationer og brugere isoleres til forskellige navnerum ved at bruge mange navnenoder.
- Skalerbarhed for navneområde – I føderation skalerer mange navnenoder vandret op i filsystemets navneområde.
- Ydeevne – Vi kan forbedre læse-/skrivedriftsgennemstrømningen ved at tilføje flere navnenoder.
Konklusion
Som konklusion til HDFS Federation kan vi sige, at det overvinder begrænsningen af enkelt node HDFS-arkitektur. I tidligere HDFS-arkitektur tillader en hel klynge kun et enkelt navneområde. Mens Federation bruger mange uafhængige Namenode/navneområder til at skalere navnetjenesten vandret.
Det adskiller også navneområdet og lageret lag. Giver derfor isolation, skalerbarhed og enkelt design.
Hvis du har nogen forespørgsler eller forslag relateret til Federation i Hadoop HDFS, så lad os det vide ved at efterlade en kommentar.