Hvis du vil vide alt om Hadoop MapReduce, er du landet det rigtige sted. Denne MapReduce Tutorial giver dig den komplette guide om alt og alt i Hadoop MapReduce.
I denne MapReduce-introduktion vil du udforske, hvad Hadoop MapReduce er, hvordan MapReduce-rammen fungerer. Artiklen dækker også MapReduce DataFlow, forskellige faser i MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sortering, Data Locality og mange flere.
Vi har også benyttet os af fordelene ved MapReduce-rammen.
Lad os først undersøge, hvorfor vi har brug for Hadoop MapReduce.
Hvorfor MapReduce?
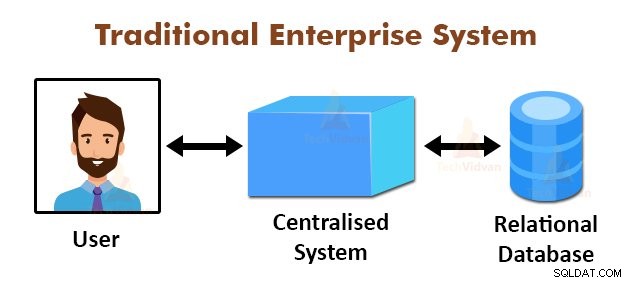
Ovenstående figur viser det skematiske billede af de traditionelle virksomhedssystemer. De traditionelle systemer har normalt en centraliseret server til lagring og behandling af data. Denne model er ikke egnet til at behandle enorme mængder skalerbare data.
Desuden kunne denne model ikke rummes af standarddatabaseservere. Derudover skaber det centraliserede system for mange flaskehalse, mens flere filer behandles samtidigt.
Ved at bruge MapReduce-algoritmen løste Google dette flaskehalsproblem. MapReduce-rammen opdeler opgaven i små dele og tildeler opgaver til mange computere.
Senere samles resultaterne på en fællesplads og integreres derefter for at danne resultatdatasættet.
Introduktion til MapReduce Framework
MapReduce er behandlingslaget i Hadoop. Det er en softwareramme designet til at behandle enorme mængder data parallelt ved at opdele opgaven i et sæt af uafhængige opgaver.
Vi skal bare lægge forretningslogikken i den måde, MapReduce fungerer på, og rammen vil tage sig af resten. MapReduce-rammen fungerer ved at opdele jobbet i små opgaver og tildele disse opgaver til slaverne.
MapReduce-programmerne er skrevet i en bestemt stil påvirket af de funktionelle programmeringskonstruktioner, specifikke idiomer til behandling af datalister.
I MapReduce er inputs i form af en liste og output fra frameworket er også i form af en liste. MapReduce er hjertet af Hadoop. Hadoops effektivitet og kraft skyldes MapReduce-rammernes parallelle behandling.
Lad os nu undersøge, hvordan Hadoop MapReduce virker.
Hvordan virker Hadoop MapReduce?
Hadoop MapReduce-rammen fungerer ved at opdele et job i uafhængige opgaver og udføre disse opgaver på slavemaskiner. MapReduce-jobbet udføres i to trin, der er kort- og reduceringsfasen.
Input til og output fra begge faser er nøgleværdipar. MapReduce-rammen er baseret på datalokalitetsprincippet (omtales senere), hvilket betyder, at den sender beregningen til de noder, hvor data findes.
- Kortfase − I kortfasen behandler den brugerdefinerede kortfunktion inputdataene. I kortfunktionen lægger brugeren forretningslogikken. Outputtet fra kortfasen er de mellemliggende output og er lagret på den lokale disk.
- Reducer fase – Denne fase er kombinationen af shuffle-fasen og reduktionsfasen. I Reducer-fasen sendes output fra kortfasen til Reducer, hvor de aggregeres. Outputtet fra Reducer-fasen er det endelige output. I Reducer-fasen behandler den brugerdefinerede reduktionsfunktion Mappers-outputtet og genererer de endelige resultater.
Under MapReduce-jobbet sender Hadoop-rammen kortopgaverne og reduktionsopgaverne til passende maskiner i klyngen.
Selve rammen administrerer alle detaljerne i dataoverførslen, såsom udstedelse af opgaver, verificering af opgaveafslutningen og kopiering af data mellem noderne omkring klyngen. Opgaverne foregår på de noder, hvor data opholder sig for at reducere netværkstrafikken.
MapReduce Data Flow
I vil måske alle vide, hvordan disse nøgleværdipar genereres, og hvordan MapReduce behandler inputdataene. Dette afsnit besvarer alle disse spørgsmål.
Lad os se, hvordan data skal flyde fra forskellige faser i Hadoop MapReduce for at håndtere kommende data på en parallel og distribueret måde.
1. Inputfiler
Inputdatasættet, som skal behandles af MapReduce-programmet, gemmes i InputFile. Inputfilen er gemt i Hadoop Distributed File System.
2. InputSplit
Posten i InputFiles er opdelt i den logiske model. Splitstørrelsen er generelt lig med HDFS-blokstørrelsen. Hver opdeling behandles af den enkelte Mapper.
3. InputFormat
InputFormat angiver filinputspecifikationen. Det definerer vejen til RecordReader, hvor posten fra InputFile konverteres til nøgleværdiparrene.
4. RecordReader
RecordReader læser data fra InputSplit og konverterer poster til nøgle, værdipar og præsenterer dem for kortlæggerne.
5. Kortlæggere
Kortlæggere tager nøgle- og værdipar som input fra RecordReader og behandler dem ved at implementere brugerdefineret kortfunktion. I hver Mapper behandles en enkelt opdeling ad gangen.
Udvikleren satte forretningslogikken i kortfunktionen. Outputtet fra alle kortlæggere er det mellemliggende output, som også er i form af et nøgle-værdipar.
6. Bland og sorter
Det mellemliggende output, der genereres af Mappers, sorteres, før det sendes til Reducer for at reducere overbelastning af netværket. De sorterede mellemudgange blandes derefter til Reducer over netværket.
7. Reducer
Reducer-processen og aggregerer Mapper-output ved at implementere brugerdefineret reduktionsfunktion. Reducers output er det endelige output og lagres i Hadoop Distributed File System (HDFS).
Lad os nu studere nogle terminologier og avancere koncepter i Hadoop MapReduce-rammen.
Nøgle-værdi-par i MapReduce
MapReduce-rammen fungerer på nøgleværdiparrene, fordi den omhandler det ikke-statiske skema. Det tager data i form af nøgle, værdipar, og genereret output er også i form af en nøgle, værdipar.
MapReduce-nøgleværdiparret er en registreringsenhed, der modtages af MapReduce-jobbet til udførelsen. I et nøgle-værdi-par:
- Nøglen er linjeforskydningen fra begyndelsen af linjen i filen.
- Værdi er linjeindholdet, eksklusive linjeafslutningerne.
MapReduce Partitioner
Hadoop MapReduce Partitioner opdeler tasterummet. Partitionering af nøglerum i MapReduce angiver, at alle værdierne for hver nøgle blev grupperet sammen, og det sikrer, at alle værdierne for den enkelte nøgle skal gå til den samme Reducer.
Denne partitionering muliggør jævn fordeling af mappers output over Reducer ved at sikre, at den rigtige nøgle går til den rigtige Reducer.
Standard MapReducer partitioner er Hash Partitioner, som opdeler nøglerummene på basis af hash-værdien.
MapReduce Combiner
MapReduce Combiner er også kendt som "Semi-Reducer". Det spiller en stor rolle i at reducere overbelastning af netværket. MapReduce-rammen giver funktionaliteten til at definere Combiner, som kombinerer det mellemliggende output fra Mappers, før de overføres til Reducer.
Sammenlægningen af Mapper-output, før de overføres til Reducer, hjælper rammeværket med at blande små mængder data, hvilket fører til lav netværksoverbelastning.
Combinerens hovedfunktion er at opsummere output fra Mappers med den samme nøgle og videregive det til Reducer. Combiner-klassen bruges mellem Mapper-klassen og Reducer-klassen.
Datalokalitet i MapReduce
Datalokalitet henviser til "Flytning af beregning tættere på dataene i stedet for at flytte data til beregningen." Det er meget mere effektivt, hvis den beregning, applikationen anmoder om, udføres på den maskine, hvor de anmodede data findes.
Dette er meget sandt i det tilfælde, hvor datastørrelsen er enorm. Det er fordi det minimerer overbelastningen af netværket og øger systemets samlede gennemløb.
Den eneste antagelse bag dette er, at det er bedre at flytte beregning tættere på den maskine, hvor data er til stede, i stedet for at flytte data til den maskine, hvor applikationen kører.
Apache Hadoop arbejder på en enorm mængde data, så det er ikke effektivt at flytte så store data over netværket. Derfor kom rammeværket med det mest innovative princip, nemlig datalokalitet, som flytter beregningslogik til data i stedet for at flytte data til beregningsalgoritmer. Dette kaldes datalokalitet.
Fordele ved MapReduce
1. Skalerbarhed: MapReduce-rammen er meget skalerbar. Det gør det muligt for organisationer at køre applikationer fra store sæt maskiner, hvilket kan involvere brugen af tusindvis af terabyte data.
2. Fleksibilitet: MapReduce-rammen giver organisationen fleksibilitet til at behandle data af enhver størrelse og ethvert format, enten struktureret, semi-struktureret eller ustruktureret.
3. Sikkerhed og godkendelse: MapReduce programmeringsmodel giver høj sikkerhed. Det beskytter enhver uautoriseret adgang til dataene og forbedrer klyngesikkerheden.
4. Omkostningseffektiv: Rammen behandler data på tværs af klyngen af råvarehardware, som er billige maskiner. Det er således meget omkostningseffektivt.
5. Hurtigt: MapReduce behandler data parallelt, hvilket gør det meget hurtigt. Det tager kun minutter at behandle terabytes af data.
6. En simpel model til programmering: MapReduce-programmerne kan skrives på ethvert sprog, såsom Java, Python, Perl, R osv. Så alle kan nemt lære og skrive MapReduce-programmer og opfylde deres behov for databehandling.
Brug af MapReduce
1. Loganalyse: MapReduce bruges grundlæggende til at analysere logfiler. Rammerne deler de store logfiler op i opdelingen og en mappesøgning efter de forskellige websider, der blev tilgået.
Hver gang, når der findes en webside i loggen, sendes et nøgle-værdi-par til reduceringen, hvor nøglen er websiden, og værdien er "1". Efter at have udsendt et nøgleværdipar til Reducer, samler Reducererne antallet af for visse websider.
Det endelige resultat vil være det samlede antal hits for hver webside.
2. Fuldtekstindeksering: MapReduce bruges også til at udføre fuldtekstindeksering. Kortlæggeren i MapReduce vil knytte hver sætning eller ord i ét dokument til dokumentet. Reduceren vil skrive disse tilknytninger til et indeks.
3. Google bruger MapReduce til at beregne deres Pagerank.
4. Omvendt weblink-graf: MapReduce bruges også i Reverse Web-Link GRAph. Kortfunktionen udlæser URL-målet og kilden ved at tage input fra websiden (kilde).
Reduceringsfunktionen sammenkæder derefter listen over alle kilde-URL'er, der er knyttet til den givne mål-URL, og den returnerer målet og listen over kilder.
5. Ordantal i et dokument: MapReduce framework kan bruges til at tælle antallet af gange ordet optræder i et dokument.
Oversigt
Det hele handler om Hadoop MapReduce Tutorial. Rammen behandler enorme mængder data parallelt på tværs af klyngen af råvarehardware. Den opdeler jobbet i uafhængige opgaver og udfører dem parallelt på forskellige noder i klyngen.
MapReduce overvinder flaskehalsen i det traditionelle virksomhedssystem. Rammen fungerer på nøglen, værdipar. Brugeren definerer de to funktioner, der er kortfunktion og reduceringsfunktion.
Forretningslogikken lægges ind i kortfunktionen. Artiklen havde forklaret forskellige avancerede koncepter i MapReduce-rammerne.