Lær om den næsten realtids-dataindtagelsesarkitektur til at transformere og berige datastrømme ved hjælp af Apache Flume, Apache Kafka og RocksDB i Santander UK.
Cloudera Professional Services har arbejdet sammen med Santander UK om at bygge et næsten realtid (NRT) transaktionsanalysesystem på Apache Hadoop. Målet er at fange, transformere, berige, tælle og gemme en transaktion inden for få sekunder efter, at et kortkøb har fundet sted. Systemet modtager bankens detailkundekorttransaktioner og beregner de tilhørende trendoplysninger aggregeret af kontohaver og over en række dimensioner og taksonomier. Disse oplysninger leveres derefter sikkert til Santanders "Spendlytics"-app (se nedenfor) for at give kunderne mulighed for at analysere deres seneste forbrugsmønstre.
Apache HBase blev valgt som den underliggende lagringsløsning på grund af dens evne til at understøtte tilfældige skrivninger med høj gennemstrømning og tilfældige læsninger med lav latens. NRT-kravet udelukkede dog at udføre transformationer og berigelse af transaktionerne i batch, så disse skal udføres, mens transaktionerne streames ind i HBase. Dette omfatter transformation af meddelelser fra XML til Avro og berigelse af dem med trendvenlig information, såsom brand- og sælgeroplysninger.
Dette indlæg beskriver, hvordan Santander bruger Apache Flume, Apache Kafka og RocksDB til at transformere, berige og streame transaktioner til HBase. Dette er en implementering af NRT-hændelsesbehandling med ekstern kontekst streamingmønster beskrevet af Ted Malaska i dette indlæg.
Flafka
Den første beslutning Santander skulle tage var, hvordan man bedst kunne streame data til HBase. Flume er næsten altid det bedste valg til streaming af indtagelse i Hadoop i betragtning af dets enkelhed, pålidelighed, rige vifte af kilder og dræn og iboende skalerbarhed.
For nylig er fremragende integration til Kafka blevet tilføjet, hvilket fører til den uundgåeligt navngivne Flafka. Flume kan naturligt levere garanteret begivenhedslevering gennem sin filkanal, men evnen til at afspille begivenheder og den ekstra fleksibilitet og fremtidssikret Kafka bringer var nøgledriverne for integrationen.
I denne arkitektur bruger Santander Kafka-kanaler til at levere en pålidelig, selvbalancerende og skalerbar indtagelsesbuffer, hvor alle transformationer og behandling er repræsenteret i kædede Kafka-emner. Især gør vi udstrakt brug af Flafkas kilde og sink, og Flumes evne til at udføre behandling under flyvningen ved hjælp af interceptorer. Dette forhindrede os i at skulle kode vores egen Kafka-producent og forbruger og gjorde det muligt for Santander at drage fuld fordel af Cloudera Manager til at konfigurere, implementere og overvåge agenter og mæglere.
Transformation
Transaktioner, der fanges af kernebanksystemerne, leveres til Flume som XML-meddelelser, efter at de er blevet læst fra kildedatabasen via logreplikering. (At hale en databaselog ind i Kafka-emner på denne måde er et mere og mere almindeligt mønster, og kombineret med logkomprimering kan det give en "nyeste visning" af databasen for brugssager til ændring af datafangst.)
Flume gemmer disse XML-meddelelser i et "rå" Kafka-emne. Herfra, og som en forløber for al anden behandling, blev det besluttet at transformere den semi-strukturerede XML til strukturerede binære poster for at lette standardiseret downstream-behandling. Denne behandling udføres af en brugerdefineret Flume Interceptor, der transformerer XML-meddelelserne til en generisk Avro-repræsentation, der anvender specifikke typer, hvor det er relevant, og falder tilbage til en strengrepræsentation, hvor det ikke er tilfældet. Al efterfølgende NRT-behandling gemmer derefter afledte resultater i Avro i dedikerede Kafka-emner, hvilket gør det nemt at få adgang til strømmen og få et begivenhedsfeed på et hvilket som helst tidspunkt i behandlingskæden.
Hvis mere kompleks hændelsesbehandling var påkrævet – for eksempel sammenlægninger med Spark Streaming – ville det være en triviel sag at forbruge et eller flere af disse emner og udgive til nye afledte emner. (Apache Avro er et naturligt valg til dette format:det er en kompakt binær protokol, der understøtter skemaudvikling, har en fleksibel skemadefinition og understøttes i hele Hadoop-stakken. Avro er hurtigt ved at blive en de facto standard for midlertidig og generel datalagring i en virksomhedsdatahub og er perfekt placeret til transformation til Apache Parquet til analysearbejdsbelastninger.)
Berigelse
Inspirationen til designet af streamingberigelsesløsningen kom fra et O'Reilly Radar-indlæg skrevet af Jay Kreps. I sit indlæg beskriver Jay fordelene ved at bruge en lokal butik til at gøre det muligt for en stream-processor at forespørge eller ændre en lokal stat som svar på dens input, i modsætning til at foretage fjernopkald til en distribueret database.
Hos Santander tilpassede vi dette mønster for at give lokale referencebutikker, der bruges til at forespørge og berige transaktioner, mens de streamer gennem Flume. Hvorfor ikke bare bruge HBase som referencebutik? Nå, et typisk mønster for denne type problemer er simpelthen at gemme tilstanden i HBase og få berigelsesmekanismen til at forespørge den direkte. Vi har valgt at afvise denne tilgang af et par grunde. For det første er referencedataene relativt små og ville passe ind i en enkelt HBase-region, hvilket sandsynligvis forårsager et område-hotspot. For det andet betjener HBase den kundevendte Spendlytics-app, og Santander ønskede ikke, at den ekstra belastning skulle påvirke app-forsinkelsen eller omvendt. Dette er også grunden til, at vi besluttede ikke at bruge HBase til selv at bootstrap de lokale butikker ved opstart.
Så ved at give hver Flume Agent en hurtig lokal butik til at berige begivenheder under flyvningen, er Santander i stand til at give bedre præstationsgarantier for både berigelse under flyvningen og Spendlytics-appen. Vi besluttede at bruge RocksDB til at implementere de lokale butikker, fordi det er i stand til at give hurtig adgang til store mængder off-heap data (hvilket eliminerer byrden på GC), og det faktum, at det har en Java API, der gør det nemmere at bruge fra en brugerdefineret Flume Interceptor. Denne tilgang reddede os fra at skulle kode vores egen off-heap butik. RocksDB kan nemt skiftes ud med en anden lokal butiksimplementering, men i dette tilfælde passede det perfekt til Santanders brugssag.
Den brugerdefinerede Flume-berigelse Interceptor-implementering behandler hændelser fra det opstrøms "transformerede" emne, forespørger i dens lokale butik for at berige dem og skriver resultaterne til downstream Kafka-emner afhængigt af resultatet. Denne proces er illustreret mere detaljeret nedenfor.
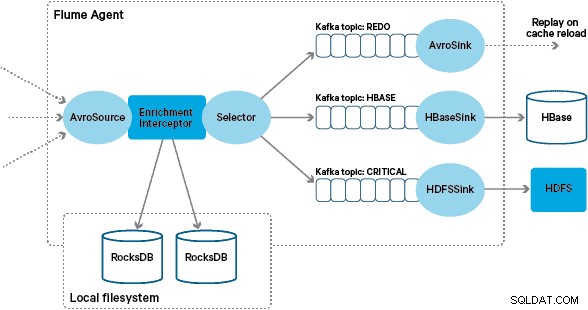
På dette tidspunkt undrer du dig måske:Uden vedholdenhed leveret af HBase, hvordan genereres lokale butikker? Referencedataene omfatter en række forskellige datasæt, der skal sammenføjes. Disse datasæt opdateres i HDFS på daglig basis og danner input til en planlagt Apache Spark-applikation, som genererer RocksDB-butikkerne. Nygenererede RocksDB-butikker iscenesættes i HDFS, indtil de downloades af Flume Agents for at sikre, at begivenhedsstrømmen beriges med den seneste information.
Ideelt set ville vi ikke skulle vente på, at disse datasæt alle er tilgængelige i HDFS, før de kunne behandles. Hvis dette var tilfældet, kunne referencedataopdateringer streames gennem Flafka-pipelinen for løbende at opretholde den lokale referencedatatilstand.
I vores oprindelige design havde vi planlagt at skrive og planlægge via cron et script til at polle HDFS for at tjekke efter nye versioner af RocksDB-butikkerne, og downloade dem fra HDFS, når de er tilgængelige. Selvom på grund af de interne kontroller og styring af Santanders produktionsmiljøer, skulle denne mekanisme inkorporeres i den samme Flume Interceptor, som bruges til at udføre berigelsen (den tjekker for opdateringer en gang i timen, så det er ikke en dyr operation). Når en ny version af butikken er tilgængelig, sendes en opgave til en arbejdstråd for at downloade den nye butik fra HDFS og indlæse den i RocksDB. Denne proces sker i baggrunden, mens berigelsesinterceptoren fortsætter med at behandle strømmen. Når den nye version af butikken er indlæst i RocksDB, skifter Interceptor til den nyeste version, og den udløbne butik slettes. Den samme mekanisme bruges til at bootstrap RocksDB-butikkerne fra en kold opstart, før Interceptor begynder at forsøge at berige begivenheder.
Beskeder, der er beriget med succes, skrives til et Kafka-emne for at blive skrevet idempotent til HBase ved hjælp af HBaseEventSerializer.
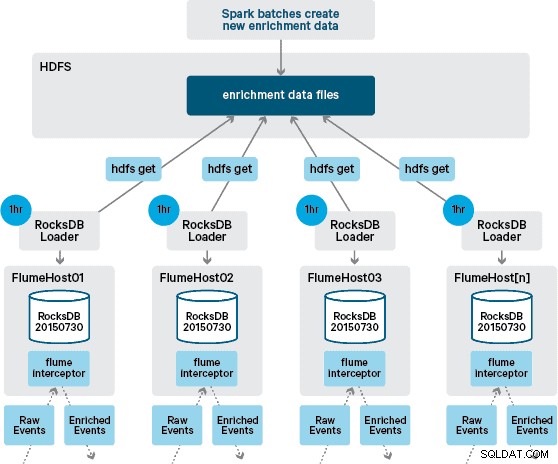
Mens hændelsesstrømmen behandles på en kontinuerlig basis, kan nye versioner af den lokale butik kun genereres dagligt. Umiddelbart efter at en ny version af den lokale butik er blevet indlæst af Flume, anses den for at være frisk,” selvom den bliver mere og mere forældet før tilgængeligheden af en ny version. Følgelig stiger antallet af "cache-misser", indtil en nyere version af den lokale butik er tilgængelig. For eksempel kan nye og opdaterede brand- og købmandsoplysninger tilføjes referencedataene, men indtil de er gjort tilgængelige for Flumes berigelse, kan Interceptor-transaktioner ikke beriges eller beriges med forældede oplysninger, som senere skal afstemt efter at den er blevet fastholdt i HBase.
For at håndtere denne sag bliver cache-misser (begivenheder, der ikke bliver beriget) skrevet til et "redo" Kafka-emne ved hjælp af en Flume Selector. Gentag-emnet afspilles derefter tilbage i berigelsesinterceptorens kildeemne, når en ny lokal butik er tilgængelig.
For at forhindre "giftmeddelelser" (begivenheder, der konstant mislykkes med berigelse), besluttede vi at tilføje en tæller til en begivenheds header, før vi føjer den til gentag-emnet. Begivenheder, der gentagne gange optræder om dette emne, omdirigeres til sidst til et "kritisk" emne, som skrives til HDFS for senere inspektion og afhjælpning. Denne tilgang er illustreret i det første diagram.
Konklusion
For at opsummere de vigtigste take-away-punkter fra dette indlæg:
- At bruge en kæde af Kafka-emner til at gemme delte mellemliggende data som en del af din indtagelsespipeline er et effektivt mønster.
- Du har flere muligheder for at fortsætte og forespørge om tilstands- eller referencedata i din NRT-indtagelsespipeline. Foretræk HBase til dette formål som det almindelige mønster, når de supplerende data er store, men overvej brugen af indlejrede lokale lagre (såsom RocksDB) eller JVM-hukommelse, for når du bruger HBase, er det ikke praktisk.
- Handling af fejl er vigtig. (Se #1 for at få hjælp til det.)
I et opfølgende indlæg vil vi beskrive, hvordan vi gør brug af HBase-coprocessorer til at levere per-kunde-aggregeringer af historiske købstendenser, og hvordan offline transaktioner behandles i batch ved hjælp af (Cloudera Labs-projekt) SparkOnHBase (som for nylig blev indgået i HBase trunk). Vi vil også beskrive, hvordan løsningen blev designet til at opfylde kundens krav til høj tilgængelighed på tværs af datacentre.
James Kinley, Ian Buss og Rob Siwicki er Solution Architects hos Cloudera.