Ofte, når vi skriver en lagret procedure, ønsker vi, at den skal opføre sig på forskellige måder baseret på brugerinput. Lad os se på følgende eksempel:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Denne lagrede procedure, som jeg oprettede i AdventureWorks2017-databasen, har to parametre:@CustomerID og @SortOrder. Den første parameter, @CustomerID, påvirker de rækker, der skal returneres. Hvis et specifikt kunde-id overføres til den lagrede procedure, returnerer det alle ordrer (top 10) for denne kunde. Ellers, hvis den er NULL, returnerer den lagrede procedure alle ordrer (top 10), uanset kunden. Den anden parameter, @SortOrder, bestemmer, hvordan dataene vil blive sorteret – efter OrderDate eller SalesOrderID. Bemærk, at kun de første 10 rækker vil blive returneret i henhold til sorteringsrækkefølgen.
Så brugere kan påvirke forespørgslens adfærd på to måder – hvilke rækker der skal returneres, og hvordan de sorteres. For at være mere præcis er der 4 forskellige adfærdsformer for denne forespørgsel:
- Returner de øverste 10 rækker for alle kunder sorteret efter OrderDate (standardadfærd)
- Returner de øverste 10 rækker for en specifik kunde sorteret efter ordredato
- Returner de øverste 10 rækker for alle kunder sorteret efter SalesOrderID
- Returner de øverste 10 rækker for en specifik kunde sorteret efter SalesOrderID
Lad os teste den lagrede procedure med alle 4 muligheder og undersøge eksekveringsplanen og statistik-IO.
Returner de 10 bedste rækker for alle kunder sorteret efter ordredato
Følgende er koden til at udføre den lagrede procedure:
EXECUTE Sales.GetOrders; GO
Her er udførelsesplanen:
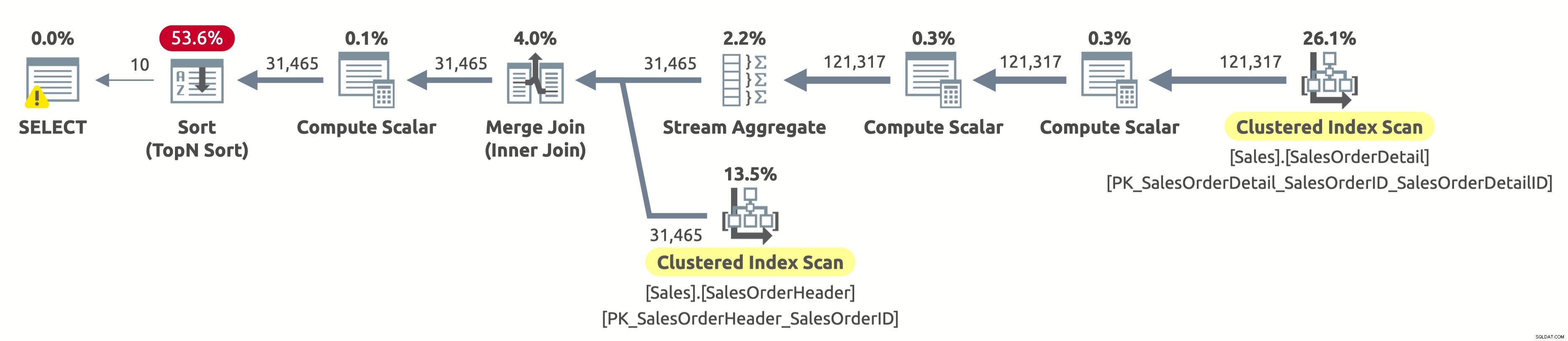
Da vi ikke har filtreret efter kunde, skal vi scanne hele tabellen. Optimizeren valgte at scanne begge tabeller ved hjælp af indekser på SalesOrderID, hvilket muliggjorde en effektiv Stream Aggregate samt en effektiv Merge Join.
Hvis du tjekker egenskaberne for Clustered Index Scan-operatoren i Sales.SalesOrderHeader-tabellen, vil du finde følgende prædikat:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] som [SalesOrders].[CustomerID]=[ @CustomerID] ELLER [@CustomerID] ER NULL. Forespørgselsprocessoren skal evaluere dette prædikat for hver række i tabellen, hvilket ikke er særlig effektivt, fordi det altid vil evaluere til sandt.
Vi mangler stadig at sortere alle data efter OrderDate for at returnere de første 10 rækker. Hvis der var et indeks på OrderDate, så ville optimeringsværktøjet sandsynligvis kun have brugt det til kun at scanne de første 10 rækker fra Sales.SalesOrderHeader, men der er ikke et sådant indeks, så planen virker fin i betragtning af de tilgængelige indekser.
Her er output af statistik IO:
- Tabel 'SalesOrderHeader'. Scanning tæller 1, logisk læser 689
- Tabel 'SalesOrderDetail'. Scanning tæller 1, logisk læser 1248
Hvis du spørger, hvorfor der er en advarsel på SELECT-operatøren, så er det en overdreven bevillingsadvarsel. I dette tilfælde er det ikke, fordi der er et problem i udførelsesplanen, men snarere fordi forespørgselsprocessoren anmodede om 1.024 KB (hvilket er minimum som standard) og kun brugte 16 KB.
Nogle gange er plancaching ikke så god en idé
Dernæst vil vi teste scenariet med at returnere de øverste 10 rækker for en specifik kunde sorteret efter OrderDate. Nedenfor er koden:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Udførelsesplanen er nøjagtig den samme som før. Denne gang er planen meget ineffektiv, fordi den kun scanner begge tabeller for at returnere 3 ordrer. Der er meget bedre måder at udføre denne forespørgsel på.
Årsagen, i dette tilfælde, er plancaching. Udførelsesplanen blev genereret i den første udførelse baseret på parameterværdierne i den specifikke udførelse - en metode kendt som parametersniffing. Denne plan blev gemt i plancachen til genbrug, og fra nu af vil hvert kald til denne lagrede procedure genbruge den samme plan.
Dette er et eksempel, hvor plancaching ikke er så god en idé. På grund af arten af denne lagrede procedure, som har 4 forskellige adfærd, forventer vi at få en anden plan for hver adfærd. Men vi sidder fast med en enkelt plan, som kun er god for en af de 4 muligheder, baseret på den mulighed, der blev brugt i den første udførelse.
Lad os deaktivere plancaching for denne lagrede procedure, bare så vi kan se den bedste plan, som optimizeren kan komme med for hver af de andre 3 adfærd. Vi vil gøre dette ved at tilføje WITH RECOMPILE til kommandoen EXECUTE.
Returner de 10 bedste rækker til en specifik kunde sorteret efter ordredato
Følgende er koden til at returnere de øverste 10 rækker for en specifik kunde sorteret efter ordredato:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Følgende er udførelsesplanen:
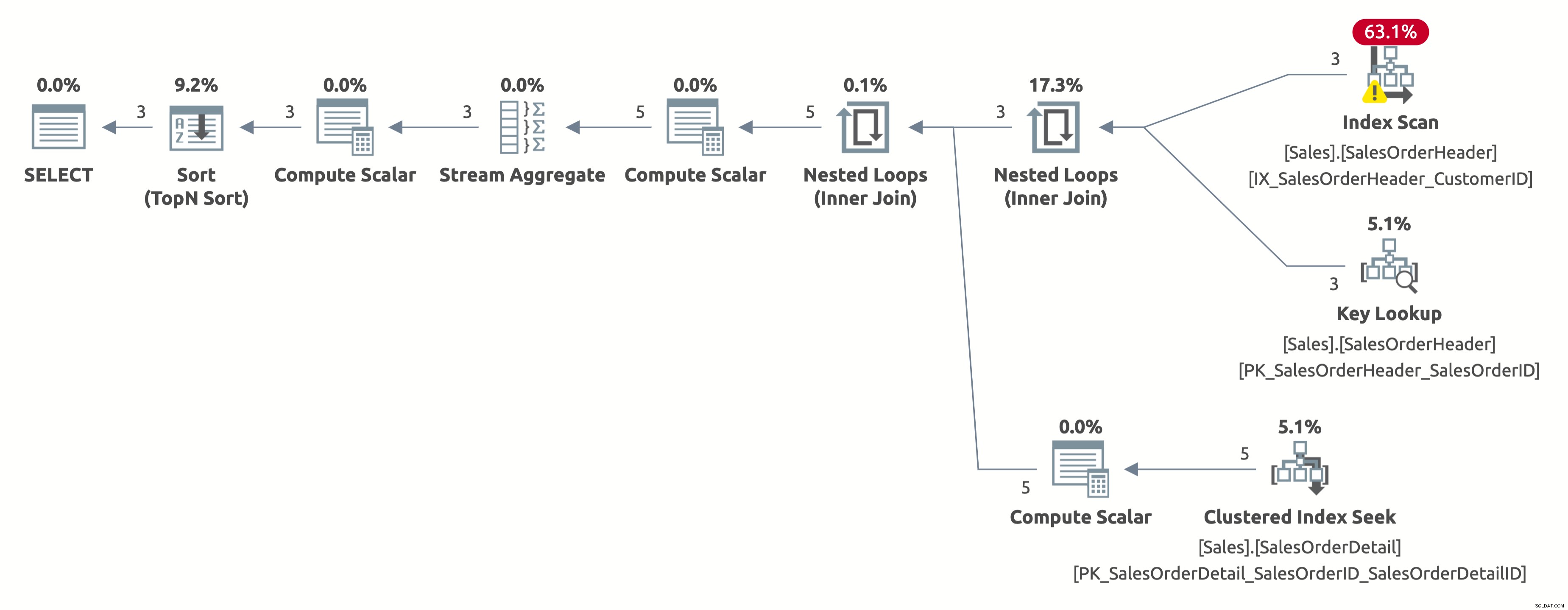
Denne gang får vi en bedre plan, som bruger et indeks på KundeID. Optimizeren estimerer korrekt 2,6 rækker for Kunde-ID =11006 (det faktiske tal er 3). Men bemærk, at den udfører en indeksscanning i stedet for en indekssøgning. Den kan ikke udføre en indekssøgning, fordi den skal evaluere følgende prædikat for hver række i tabellen:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] som [SalesOrders].[CustomerID]=[@CustomerID ] ELLER [@CustomerID] ER NULL.
Her er output af statistik IO:
- Tabel 'SalesOrderDetail'. Scanning tæller 3, logisk læser 9
- Tabel 'SalesOrderHeader'. Scanning tæller 1, logisk læser 66
Returner de 10 bedste rækker for alle kunder sorteret efter SalesOrderID
Følgende er koden til at returnere de øverste 10 rækker for alle kunder sorteret efter SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Følgende er udførelsesplanen:
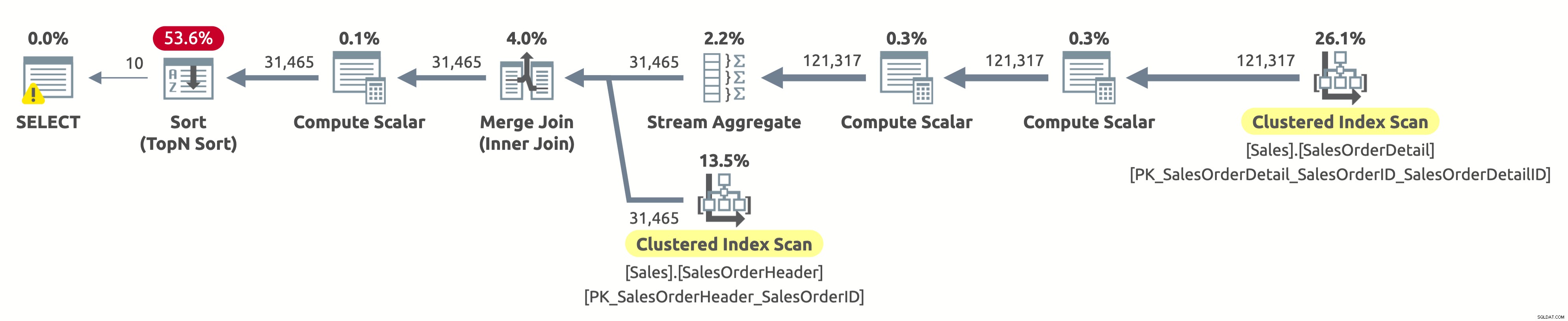
Hej, dette er den samme udførelsesplan som i den første mulighed. Men denne gang er der noget galt. Vi ved allerede, at de klyngede indekser på begge tabeller er sorteret efter SalesOrderID. Vi ved også, at planen scanner dem begge i den logiske rækkefølge for at bevare sorteringsrækkefølgen (egenskaben Ordnet er sat til True). Merge Join-operatøren bevarer også sorteringsrækkefølgen. Fordi vi nu beder om at sortere resultatet efter SalesOrderID, og det allerede er sorteret på den måde, hvorfor skal vi så betale for en dyr sorteringsoperatør?
Tja, hvis du tjekker Sorter-operatoren, vil du bemærke, at den sorterer dataene efter Expr1004. Og hvis du tjekker Compute Scalar-operatoren til højre for Sort-operatoren, vil du opdage, at Expr1004 er som følger:

Det er ikke et kønt syn, jeg ved det. Dette er det udtryk, vi har i ORDER BY-klausulen i vores forespørgsel. Problemet er, at optimeringsværktøjet ikke kan evaluere dette udtryk på kompileringstidspunktet, så det skal beregne det for hver række ved kørsel og derefter sortere hele postsættet baseret på det.
Outputtet af statistik IO er ligesom i den første udførelse:
- Tabel 'SalesOrderHeader'. Scanning tæller 1, logisk læser 689
- Tabel 'SalesOrderDetail'. Scanning tæller 1, logisk læser 1248
Returner de 10 bedste rækker til en specifik kunde sorteret efter SalesOrderID
Følgende er koden til at returnere de øverste 10 rækker for en specifik kunde sorteret efter SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Udførelsesplanen er den samme som i den anden mulighed (retur top 10 rækker for en specifik kunde sorteret efter OrderDate). Planen har de samme to problemer, som vi allerede har nævnt. Det første problem er at udføre en indeksscanning i stedet for en indekssøgning på grund af udtrykket i WHERE-sætningen. Det andet problem er at udføre en dyr sortering på grund af udtrykket i ORDER BY-sætningen.
Så hvad skal vi gøre?
Lad os først minde os selv om, hvad vi har med at gøre. Vi har parametre, som bestemmer forespørgslens struktur. For hver kombination af parameterværdier får vi en anden forespørgselsstruktur. I tilfælde af @CustomerID-parameteren er de to forskellige adfærd NULL eller NOT NULL, og de påvirker WHERE-udtrykket. I tilfælde af @SortOrder-parameteren er der to mulige værdier, og de påvirker ORDER BY-udtrykket. Resultatet er 4 mulige forespørgselsstrukturer, og vi vil gerne have en anden plan for hver enkelt.
Så har vi to forskellige problemer. Den første er plancaching. Der er kun en enkelt plan for den lagrede procedure, og den vil blive genereret baseret på parameterværdierne i den første udførelse. Det andet problem er, at selv når en ny plan genereres, er den ikke effektiv, fordi optimeringsværktøjet ikke kan evaluere de "dynamiske" udtryk i WHERE-udtrykket og i ORDER BY-udtrykket på kompileringstidspunktet.
Vi kan forsøge at løse disse problemer på flere måder:
- Brug en række IF-ELSE-sætninger
- Opdel proceduren i separate lagrede procedurer
- Brug OPTION (GENKOMPILER)
- Generer forespørgslen dynamisk
Brug en række IF-ELSE-erklæringer
Ideen er enkel:I stedet for de "dynamiske" udtryk i WHERE-sætningen og i ORDER BY-sætningen, kan vi opdele udførelsen i 4 grene ved hjælp af IF-ELSE-sætninger – en gren for hver mulig adfærd.
For eksempel er følgende koden for den første gren:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Denne tilgang kan hjælpe med at generere bedre planer, men den har nogle begrænsninger.
For det første bliver den lagrede procedure ret lang, og den er sværere at skrive, læse og vedligeholde. Og det er, når vi kun har to parametre. Hvis vi havde 3 parametre, ville vi have 8 grene. Forestil dig, at du skal tilføje en kolonne til SELECT-sætningen. Du skal tilføje kolonnen i 8 forskellige forespørgsler. Det bliver et vedligeholdelsesmareridt med høj risiko for menneskelige fejl.
For det andet har vi stadig problemet med plancaching og parametersniffing til en vis grad. Dette skyldes, at i den første udførelse vil optimeringsværktøjet generere en plan for alle 4 forespørgsler baseret på parameterværdierne i den udførelse. Lad os sige, at den første udførelse vil bruge standardværdierne for parametrene. Specifikt vil værdien af @CustomerID være NULL. Alle forespørgsler vil blive optimeret baseret på denne værdi, inklusive forespørgslen med WHERE-klausulen (SalesOrders.CustomerID =@CustomerID). Optimeringsværktøjet vil estimere 0 rækker for disse forespørgsler. Lad os nu sige, at den anden udførelse kommer til at bruge en ikke-null værdi for @CustomerID. Den cachelagrede plan, som anslår 0 rækker, vil blive brugt, selvom kunden måske har mange ordrer i tabellen.
Opdel proceduren i separate lagrede procedurer
I stedet for 4 grene inden for den samme lagrede procedure, kan vi oprette 4 separate lagrede procedurer, hver med de relevante parametre og den tilsvarende forespørgsel. Derefter kan vi enten omskrive applikationen for at beslutte, hvilken lagret procedure der skal udføres i henhold til den ønskede adfærd. Eller, hvis vi ønsker, at det skal være gennemsigtigt for applikationen, kan vi omskrive den oprindelige lagrede procedure for at beslutte, hvilken procedure der skal udføres baseret på parameterværdierne. Vi kommer til at bruge de samme IF-ELSE-sætninger, men i stedet for at udføre en forespørgsel i hver gren, vil vi udføre en separat lagret procedure.
Fordelen er, at vi løser plancaching-problemet, fordi hver lagret procedure nu har sin egen plan, og planen for hver lagret procedure vil blive genereret i dens første udførelse baseret på parametersniffing.
Men vi har stadig vedligeholdelsesproblemet. Nogle mennesker vil måske sige, at nu er det endnu værre, fordi vi skal opretholde flere lagrede procedurer. Igen, hvis vi øger antallet af parametre til 3, ville vi ende med 8 forskellige lagrede procedurer.
Brug OPTION (GENKOMPILER)
OPTION (GENKOMPILER) fungerer som magi. Du skal bare sige ordene (eller tilføje dem til forespørgslen), og der sker magi. Virkelig løser det så mange problemer, fordi det kompilerer forespørgslen ved kørsel, og det gør det for hver udførelse.
Men du skal være forsigtig, fordi du ved, hvad de siger:"Med stor magt følger et stort ansvar." Hvis du bruger OPTION (RECOMPILE) i en forespørgsel, der udføres meget ofte på et travlt OLTP-system, kan du dræbe systemet, fordi serveren skal kompilere og generere en ny plan i hver udførelse ved at bruge en masse CPU-ressourcer. Dette er virkelig farligt. Men hvis forespørgslen kun udføres en gang imellem, lad os sige en gang hvert par minutter, så er det sandsynligvis sikkert. Men test altid påvirkningen i dit specifikke miljø.
I vores tilfælde, hvis vi antager, at vi sikkert kan bruge OPTION (RECOMPILE), er alt, hvad vi skal gøre, at tilføje de magiske ord i slutningen af vores forespørgsel, som vist nedenfor:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Lad os nu se magien i aktion. For eksempel er følgende plan for den anden adfærd:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
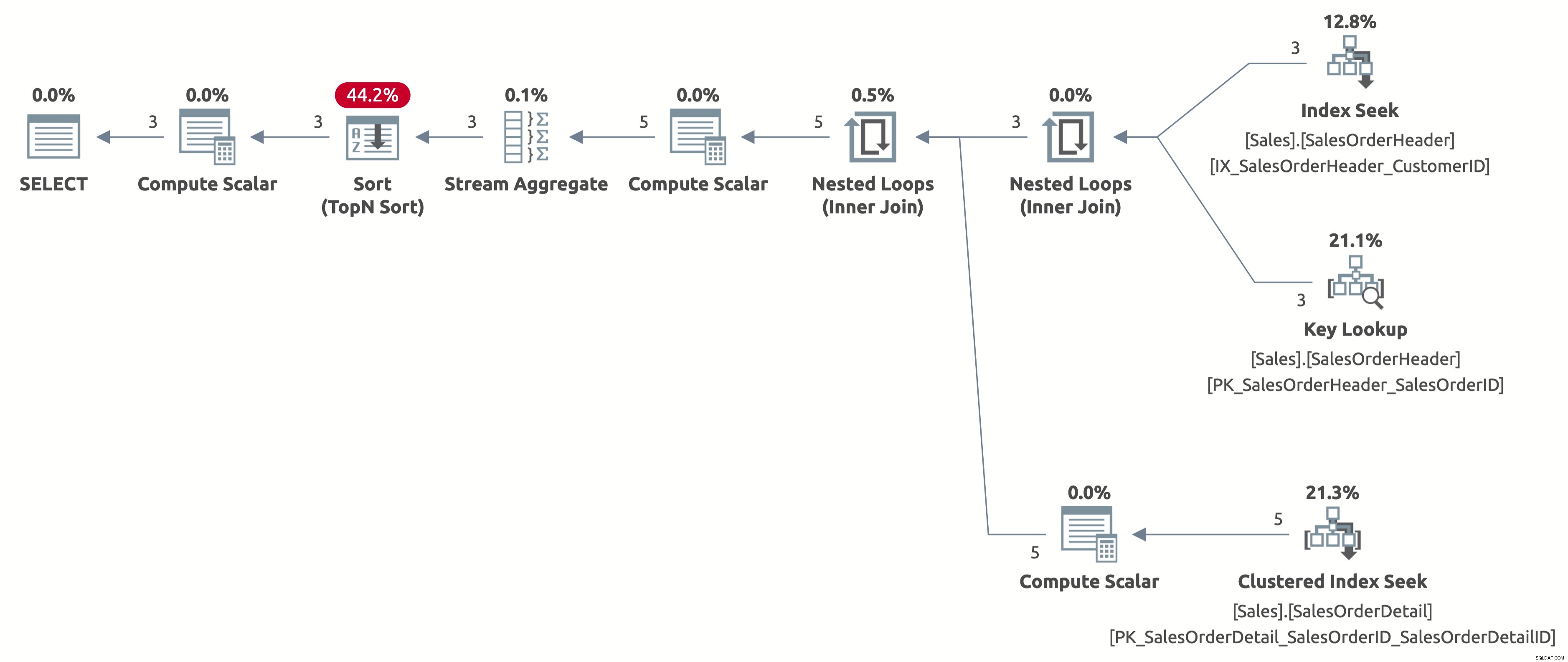
Nu får vi en effektiv indekssøgning med en korrekt estimering på 2,6 rækker. Vi skal stadig sortere efter OrderDate, men nu er sorteringen direkte efter Order Date, og vi behøver ikke længere at beregne CASE-udtrykket i ORDER BY-sætningen. Dette er den bedst mulige plan for denne forespørgselsadfærd baseret på de tilgængelige indekser.
Her er output af statistik IO:
- Tabel 'SalesOrderDetail'. Scanning tæller 3, logisk læser 9
- Tabel 'SalesOrderHeader'. Scanning tæller 1, logisk læser 11
Grunden til at OPTION (RECOMPILE) er så effektiv i dette tilfælde er, at det løser præcis de to problemer, vi har her. Husk, at det første problem er plancaching. OPTION (RECOMPILE) eliminerer dette problem helt, fordi det genkompilerer forespørgslen hver gang. Det andet problem er optimeringsværktøjets manglende evne til at evaluere det komplekse udtryk i WHERE-udtrykket og i ORDER BY-udtrykket på kompileringstidspunktet. Da OPTION (RECOMPILE) sker under kørsel, løser det problemet. For ved runtime har optimizeren meget mere information sammenlignet med kompileringstid, og det gør hele forskellen.
Lad os nu se, hvad der sker, når vi prøver den tredje adfærd:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
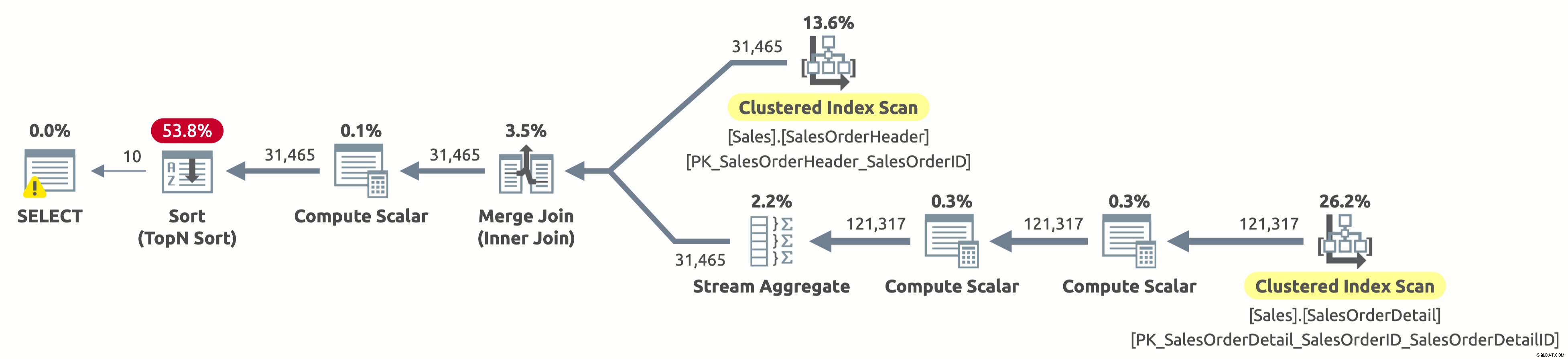
Houston vi har et problem. Planen scanner stadig begge tabeller fuldstændigt og sorterer derefter alt, i stedet for kun at scanne de første 10 rækker fra Sales.SalesOrderHeader og undgå sorteringen helt. Hvad skete der?
Dette er et interessant "tilfælde", og det har at gøre med CASE-udtrykket i ORDER BY-sætningen. CASE-udtrykket evaluerer en liste over betingelser og returnerer et af resultatudtrykkene. Men resultatudtrykkene kan have forskellige datatyper. Så hvad ville datatypen være for hele CASE-udtrykket? Nå, CASE-udtrykket returnerer altid den højeste prioritetsdatatype. I vores tilfælde har kolonnen OrderDate datatypen DATETIME, mens kolonnen SalesOrderID har INT-datatypen. DATETIME-datatypen har en højere prioritet, så CASE-udtrykket returnerer altid DATETIME.
Dette betyder, at hvis vi ønsker at sortere efter SalesOrderID, skal CASE-udtrykket først implicit konvertere værdien af SalesOrderID til DATETIME for hver række, før det sorteres. Se Compute Scalar-operatoren til højre for Sort-operatoren i planen ovenfor? Det er præcis, hvad det gør.
Dette er et problem i sig selv, og det viser, hvor farligt det kan være at blande forskellige datatyper i et enkelt CASE-udtryk.
Vi kan omgå dette problem ved at omskrive ORDER BY-klausulen på andre måder, men det ville gøre koden endnu mere grim og svær at læse og vedligeholde. Så jeg vil ikke gå i den retning.
Lad os i stedet prøve den næste metode...
Generer forespørgslen dynamisk
Da vores mål er at generere 4 forskellige forespørgselsstrukturer inden for en enkelt forespørgsel, kan dynamisk SQL være meget praktisk i dette tilfælde. Ideen er at bygge forespørgslen dynamisk baseret på parameterværdierne. På denne måde kan vi bygge de 4 forskellige forespørgselsstrukturer i en enkelt kode uden at skulle vedligeholde fire kopier af forespørgslen. Hver forespørgselsstruktur kompileres én gang, når den udføres første gang, og den får den bedste plan, fordi den ikke indeholder nogle komplekse udtryk.
Denne løsning minder meget om løsningen med de flere lagrede procedurer, men i stedet for at opretholde 8 lagrede procedurer for 3 parametre, vedligeholder vi kun en enkelt kode, der bygger forespørgslen dynamisk.
Jeg ved godt, dynamisk SQL er også grimt og nogle gange kan det være ret svært at vedligeholde, men jeg tror, det stadig er nemmere end at vedligeholde flere lagrede procedurer, og det skaleres ikke eksponentielt, efterhånden som antallet af parametre stiger.
Følgende er koden:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Bemærk, at jeg stadig bruger en intern parameter til kunde-id'et, og jeg udfører den dynamiske kode ved hjælp af sys.sp_executesql for at videregive parameterværdien. Dette er vigtigt af to grunde. For det første for at undgå flere kompileringer af den samme forespørgselsstruktur for forskellige værdier af @CustomerID. For det andet for at undgå SQL-injektion.
Hvis du prøver at udføre den lagrede procedure nu ved hjælp af forskellige parameterværdier, vil du se, at hver forespørgselsadfærd eller forespørgselsstruktur får den bedste udførelsesplan, og hver af de 4 planer kompileres kun én gang.
Som et eksempel er følgende plan for den tredje adfærd:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
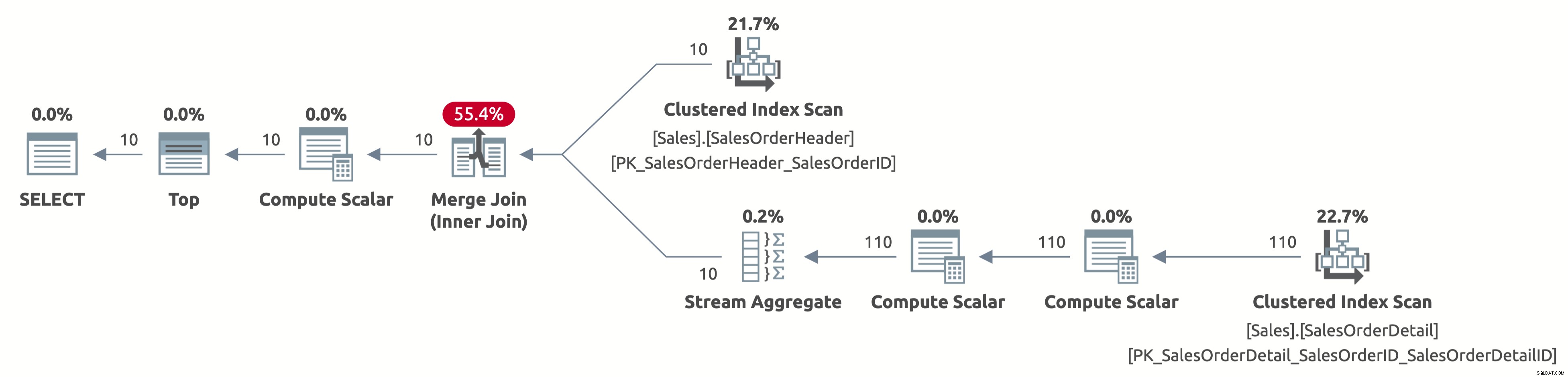
Nu scanner vi kun de første 10 rækker fra tabellen Sales.SalesOrderHeader, og vi scanner også kun de første 110 rækker fra tabellen Sales.SalesOrderDetail. Derudover er der ingen sorteringsoperator, fordi dataene allerede er sorteret efter SalesOrderID.
Her er output af statistik IO:
- Tabel 'SalesOrderDetail'. Scanning tæller 1, logisk læser 4
- Tabel 'SalesOrderHeader'. Scanning tæller 1, logisk læser 3
Konklusion
Når du bruger parametre til at ændre strukturen af din forespørgsel, skal du ikke bruge komplekse udtryk i forespørgslen til at udlede den forventede adfærd. I de fleste tilfælde vil dette føre til dårlig ydeevne, og det er der gode grunde til. Den første grund er, at planen vil blive genereret baseret på den første udførelse, og så vil alle efterfølgende eksekveringer genbruge den samme plan, hvilket kun er passende for én forespørgselsstruktur. Den anden grund er, at optimeringsværktøjet er begrænset i sin evne til at evaluere disse komplekse udtryk på kompileringstidspunktet.
Der er flere måder at overvinde disse problemer på, og vi undersøgte dem i denne artikel. I de fleste tilfælde ville den bedste metode være at bygge forespørgslen dynamisk baseret på parameterværdierne. På den måde vil hver forespørgselsstruktur blive kompileret én gang med den bedst mulige plan.
Når du bygger forespørgslen ved hjælp af dynamisk SQL, skal du sørge for at bruge parametre, hvor det er relevant, og verificere, at din kode er sikker.