Bemærk:Dette indlæg blev oprindeligt kun udgivet i vores e-bog, High Performance Techniques for SQL Server, bind 3. Du kan finde ud af om vores e-bøger her.
Et krav, jeg af og til ser, er at få en forespørgsel returneret med ordrer grupperet efter kunde, der viser det maksimale antal forfaldne set for enhver ordre til dato (et "løbende maksimum"). Så forestil dig disse eksempelrækker:
| SalesOrderID | Kunde-id | Ordredato | TotalDue |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37,55 |
| 23 | 1 | 2014-01-02 | 45,29 |
| 31 | 2 | 2014-01-03 | 24.56 |
| 32 | 2 | 2014-01-04 | 89,84 |
| 37 | 1 | 2014-01-05 | 32.56 |
| 44 | 2 | 2014-01-06 | 45,54 |
| 55 | 1 | 2014-01-07 | 99,24 |
| 62 | 2 | 2014-01-08 | 12.55 |
Et par rækker med eksempeldata
De ønskede resultater fra de angivne krav er som følger – i almindelige vendinger, sorter hver kundes ordrer efter dato, og angiv hver ordre. Hvis det er den højeste TotalDue-værdi for alle ordrer, der er set indtil den dato, skal du udskrive ordrens total, ellers udskrive den højeste TotalDue-værdi fra alle tidligere ordrer:
| SalesOrderID | Kunde-id | Ordredato | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45,29 | 45,29 |
| 23 | 1 | 2014-01-05 | 32.56 | 45,29 |
| 31 | 1 | 2014-01-07 | 99,24 | 99,24 |
| 32 | 2 | 2014-01-01 | 37,55 | 37,55 |
| 37 | 2 | 2014-01-03 | 24.56 | 37,55 |
| 44 | 2 | 2014-01-04 | 89,84 | 89,84 |
| 55 | 2 | 2014-01-06 | 45,54 | 89,84 |
| 62 | 2 | 2014-01-08 | 12.55 | 89,84 |
Eksempel på ønskede resultater
Mange mennesker ville instinktivt ønske at bruge en cursor eller while-løkke for at opnå dette, men der er flere tilgange, der ikke involverer disse konstruktioner.
Korreleret underforespørgsel
Denne tilgang ser ud til at være den enkleste og mest ligetil tilgang til problemet, men det er blevet bevist igen og igen at den ikke skaleres, da læsningerne vokser eksponentielt, efterhånden som tabellen bliver større:
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = (SELECT MAX(TotalDue)
FROM Sales.SalesOrderHeader
WHERE CustomerID = h.CustomerID
AND SalesOrderID <= h.SalesOrderID)
FROM Sales.SalesOrderHeader AS h
ORDER BY CustomerID, SalesOrderID; Her er planen mod AdventureWorks2014 ved hjælp af SQL Sentry Plan Explorer:
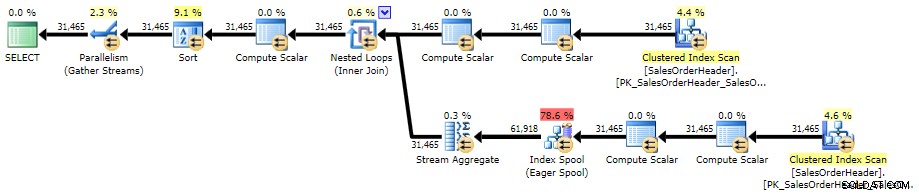 Udførelsesplan for korreleret underforespørgsel (klik for at forstørre)
Udførelsesplan for korreleret underforespørgsel (klik for at forstørre)
Selvhenvisende KRYDS GÆLDER
Denne tilgang er næsten identisk med Correlated Subquery-tilgangen med hensyn til syntaks, planform og ydeevne i skala.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDue
FROM Sales.SalesOrderHeader AS h
CROSS APPLY
(
SELECT MaxTotalDue = MAX(TotalDue)
FROM Sales.SalesOrderHeader AS i
WHERE i.CustomerID = h.CustomerID
AND i.SalesOrderID <= h.SalesOrderID
) AS x
ORDER BY h.CustomerID, h.SalesOrderID; Planen er ret lig den korrelerede underforespørgselsplan, den eneste forskel er placeringen af en slags:
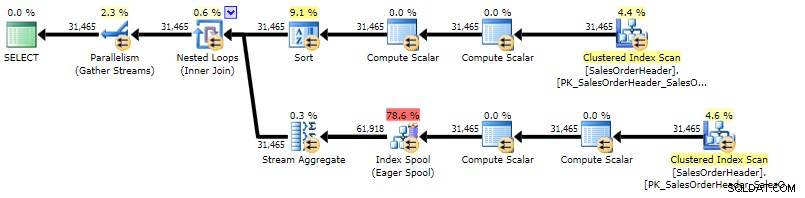 Udførelsesplan for CROSS APPLY (klik for at forstørre)
Udførelsesplan for CROSS APPLY (klik for at forstørre)
Rekursiv CTE
Bag kulisserne bruger dette loops, men indtil vi rent faktisk kører det, kan vi ligesom lade som om det ikke gør det (selvom det let er det mest komplicerede stykke kode, jeg nogensinde ville ønske at skrive for at løse dette særlige problem):
;WITH /* Recursive CTE */ cte AS
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue = TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader
) AS x
WHERE rn = 1
UNION ALL
SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue,
MaxTotalDue = CASE
WHEN r.TotalDue > cte.MaxTotalDue THEN r.TotalDue
ELSE cte.MaxTotalDue
END
FROM cte
CROSS APPLY
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader AS h
WHERE h.CustomerID = cte.CustomerID
AND h.SalesOrderID > cte.SalesOrderID
) AS r
WHERE r.rn = 1
)
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM cte
ORDER BY CustomerID, SalesOrderID
OPTION (MAXRECURSION 0); Du kan med det samme se, at planen er mere kompleks end de to foregående, hvilket ikke er overraskende i betragtning af den mere komplekse forespørgsel:
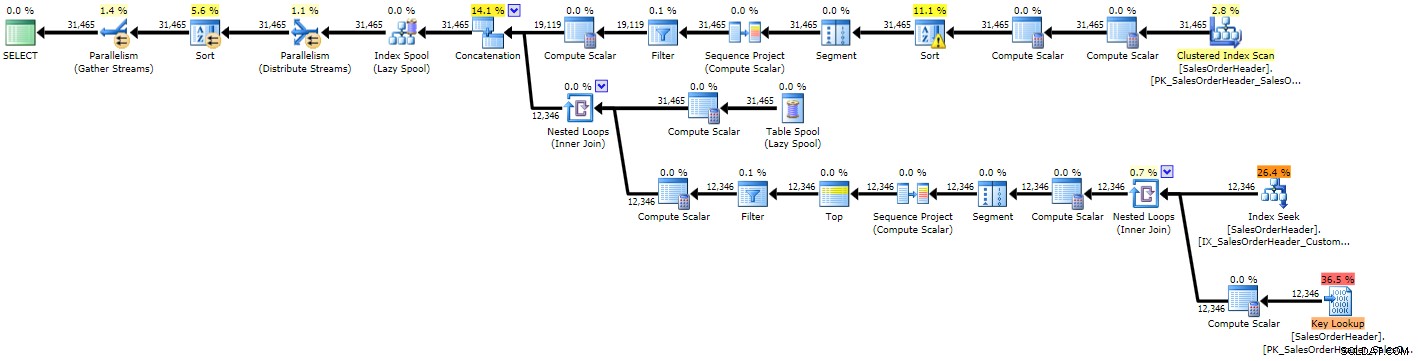 Udførelsesplan for rekursiv CTE (klik for at forstørre)
Udførelsesplan for rekursiv CTE (klik for at forstørre)
På grund af nogle dårlige estimater ser vi en indekssøgning med et tilhørende nøgleopslag, der sandsynligvis både burde være blevet erstattet af en enkelt scanning, og vi får også en sorteringsoperation, der i sidste ende skal spredes til tempdb (det kan du se i værktøjstippet hvis du holder markøren over sorteringsoperatøren med advarselsikonet):

MAX() OVER (RÆKKER UBEGRÆNSET)
Dette er en løsning, der kun er tilgængelig i SQL Server 2012 og nyere, da den bruger nyligt introducerede udvidelser til vinduesfunktioner.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = MAX(TotalDue) OVER
(
PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS UNBOUNDED PRECEDING
)
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID; Planen viser præcis, hvorfor den skalerer bedre end alle de andre; den har kun én klynget indeksscanningsoperation, i modsætning til to (eller det dårlige valg af en scanning og et søge + opslag i tilfælde af den rekursive CTE):
 Udførelsesplan for MAX() OVER() (klik for at forstørre)
Udførelsesplan for MAX() OVER() (klik for at forstørre)
Sammenligning af ydeevne
Planerne får os bestemt til at tro, at den nye MAX() OVER() kapacitet i SQL Server 2012 er en rigtig vinder, men hvad med håndgribelige runtime-metrics? Her er hvordan henrettelserne sammenlignes:

De første to forespørgsler var næsten identiske; mens i dette tilfælde CROSS APPLY var bedre med hensyn til samlet varighed med en lille margin, den korrelerede underforespørgsel slår den nogle gange lidt i stedet for. Den rekursive CTE er væsentligt langsommere hver eneste gang, og du kan se de faktorer, der bidrager til det – nemlig de dårlige estimater, den massive mængde af aflæsninger, nøgleopslaget og den ekstra sorteringsoperation. Og som jeg før har demonstreret med kørende totaler, er SQL Server 2012-løsningen bedre i næsten alle aspekter.
Konklusion
Hvis du er på SQL Server 2012 eller nyere, vil du helt sikkert gerne stifte bekendtskab med alle udvidelserne til vinduesfunktionerne, der først blev introduceret i SQL Server 2005 – de kan give dig nogle temmelig seriøse ydelsesforøg, når du genbruger kode, der stadig kører " den gamle måde." Hvis du vil lære mere om nogle af disse nye muligheder, anbefaler jeg stærkt Itzik Ben-Gans bog, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Hvis du ikke er på SQL Server 2012 endnu, i det mindste i denne test, kan du vælge mellem CROSS APPLY og den korrelerede underforespørgsel. Som altid bør du teste forskellige metoder mod dine data på din hardware.