Ved fejlfinding af CPU-ydeevneproblemer på virtualiserede SQL-servere, der kører på VMware, er en af de første ting, jeg gør, at verificere, at den virtuelle maskine-konfiguration ikke er en medvirkende faktor til ydeevneproblemet. Hvor en fysisk server har 100 % af de tilgængelige ressourcer dedikeret til operativsystemet, har en virtuel maskine det ikke, så at se på nogle få grundlæggende elementer på forhånd eliminerer fejlfinding af det forkerte problem og spilder tid. Tidligere har jeg blogget om vigtigheden af, at DBA'er har skrivebeskyttet adgang til Virtual Center for VMware til grundlæggende fejlfinding af ydeevneproblemer. Men selv uden adgang til Virtual Center er det stadig muligt at finde ud af nogle grundlæggende oplysninger inde i Windows, der kan føre til potentielle problemer på værtsniveau, der påvirker ydeevnen.
Hver virtuelle VMware-maskine har to ydeevnetællergrupper i Windows, der tilføjes, når VMware-værktøjerne er installeret i gæsten; VM-processor og VM-hukommelse. Disse ydeevnetællere er en af de første ting, jeg ser på, når jeg arbejder med en virtuel maskine på VMware, fordi de giver dig et kig på, hvilke ressourcer VM'en modtager fra hypervisoren. VM-processorgruppen har følgende tællere:
- % Processortid
- Effektiv VM-hastighed i MHz
- Værtsprocessorhastighed i MHz
- Grænse i MHz
- Reservation i MHz
- Delinger
På en VM-gæst, der viser en høj Processor\% Processortid i Task Manager eller perfmon, vil kontrol af VM Processor-tællerne give en nøjagtig redegørelse for de faktiske ressourceallokeringer, som VM-gæsten modtager. Hvis værtsprocessorhastigheden i MHz er 3000, og gæsten har tildelt 8 virtuelle CPU'er, så er den maksimale effektive hastighed for VM'en 24000 MHz, og tælleren Effektiv VM-hastighed i MHz vil afspejle, om VM'en rent faktisk får ressourcerne fra værten. Normalt når dette er tilfældet, skal du begynde at se på værtsniveauoplysningerne for at diagnosticere årsagen til problemet yderligere. Men i et nyligt klientengagement viste det sig ikke at være tilfældet.
Klient-VM'en i dette tilfælde matchede konfigurationen beskrevet ovenfor og havde en maksimal effektiv hastighed på 24000 MHz, men den effektive VM-hastighed i MHz-tælleren var kun i gennemsnit omkring 6900 MHz med VM Windows Procent Processor-tid knyttet til næsten 100 %. Et kig lige under den effektive VM-hastighed i MHz-tæller afslørede årsagen til problemet:Grænsen i MHz var 7000, hvilket betyder, at VM'en havde en konfigureret grænse for CPU-brug på 7000MHz i ESX, så den blev konsekvent droslet af hypervisoren under belastning.
Forklaringen på dette var, at netop denne VM var blevet brugt til testformål i et proof of concept og oprindeligt var placeret på en travl VM-vært; VM-administratorerne ønskede ikke en ukendt arbejdsbelastning, der forårsagede ydeevneproblemer på den vært. Så for at sikre, at det ikke ville have en negativ indvirkning på de reelle produktionsarbejdsbelastninger på værten under POC, var det begrænset til kun at tillade 7000 MHz CPU eller hvad der svarer til 2 1/3 fysiske kerner på værten. I sidste ende eliminerede fjernelse af VM CPU-grænsen i ESX de høje CPU-problemer i Windows, og de ydeevneproblemer, som klienten oplevede, forsvandt.
VM-hukommelsestællergruppen er lige så vigtig som VM-processorgruppen til at identificere potentielle ydeevneproblemer for SQL Server. VM-hukommelsestællergruppen indeholder følgende tællere:
- Hukommelse aktiv i MB
- Hukommelsesballon i MB
- Hukommelsesgrænse i MB
- Hukommelse kortlagt i MB
- Hukommelsesoverhead i MB
- Hukommelsesreservation i MB
- Hukommelse delt i MB
- Hukommelse delt Gemt i MB
- Hukommelsesdelinger
- Hukommelse ombyttet i MB
- Hukommelse brugt i MB
Af disse tællere er dem, jeg specifikt kigger på, hukommelsesballonen i MB og hukommelsen ombyttet i MB, som begge burde være nul for SQL Server-arbejdsbelastninger. Memory Ballooned in MB-tælleren fortæller, hvor meget hukommelse der er blevet genvundet fra gæste-VM'en af ballondriveren på grund af hukommelsesoverbelastning på værten, hvilket vil få SQL Server til at reducere hukommelsesforbruget for at reagere på hukommelsestryk i Windows forårsaget af ballondriveren oppustning for at fjerne hukommelsen fra VM'en. Memory Swapped in MB-tælleren sporer, hvor meget hukommelse der blev sideført til disken af værtshypervisoren på grund af hukommelsesoverbelastning på værten, som ikke kunne løses ved at ballonere VM-gæster med ballondriveren. VMwares vejledning til bedste praksis for SQL Server anbefaler, at du bruger reservationer for at sikre, at SQL Server ikke bliver balloneret eller bladret ud af ydeevneårsager, men mange VM-administratorer tøver med at indstille statiske reservationer, fordi det reducerer miljøfleksibiliteten.
Overvågningsværktøjer, som SentryOne V Sentry, kan også hjælpe. Overvej det tilfælde, hvor du måske ikke har direkte adgang til vCenter, men nogen kan konfigurere overvågning mod det på dine vegne. Nu kan du få fantastisk visualisering og indsigt i CPU, hukommelse og endda diskproblemer – både på gæste- og værtsniveau – og al den historie, der også følger med. På dashboardet nedenfor kan du se værtsmetrics til venstre (inklusive CPU-nedbrud for co-stop og klartid) og gæstemetrics til højre:
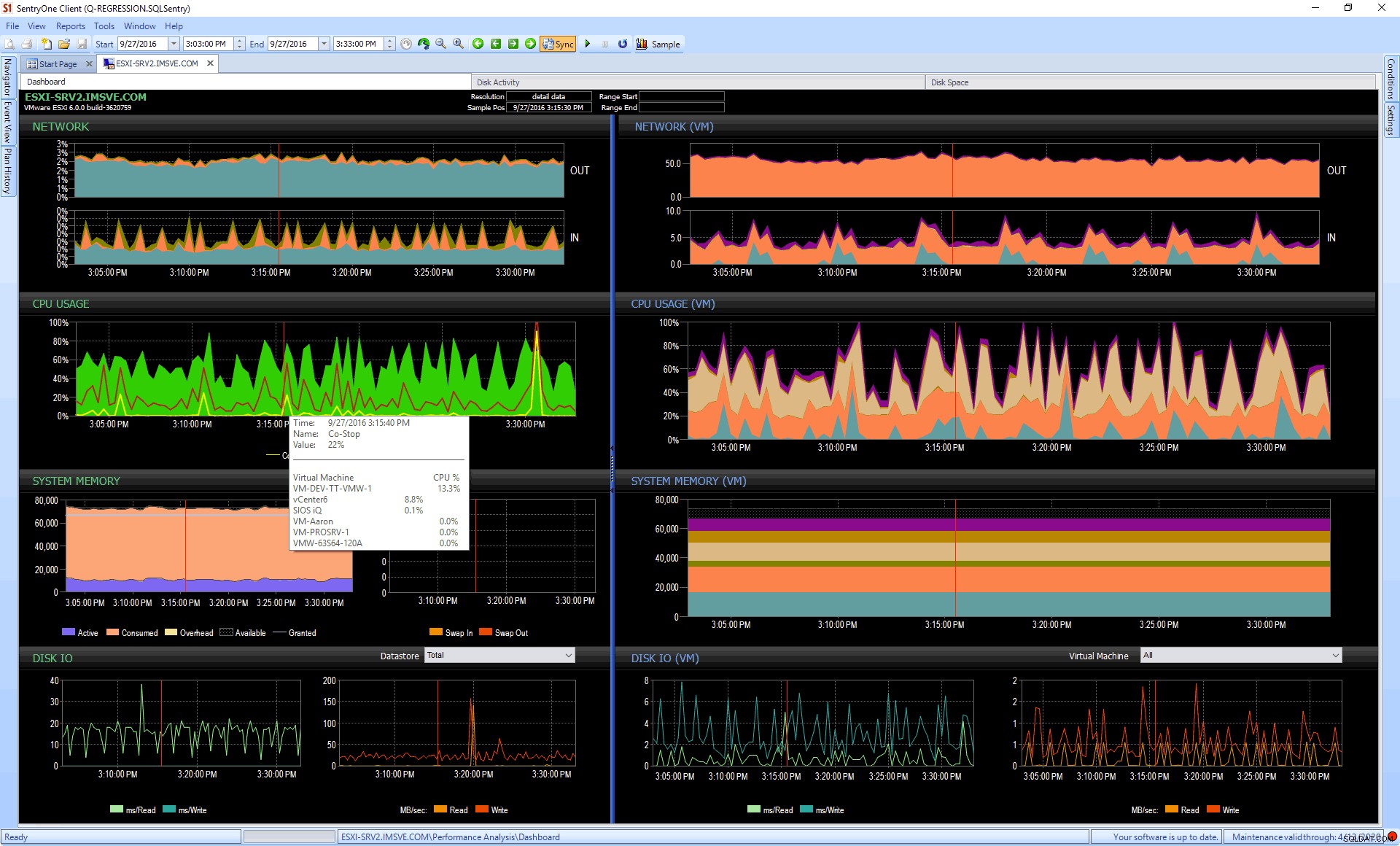
For at prøve denne og andre funktioner fra SentryOne kan du downloade en gratis prøveversion.
Konklusion
Ved fejlfinding af ydelsesproblemer på virtualiserede SQL-servere på VMware, er det vigtigt at se på problemet fra et holistisk synspunkt i stedet for at lave "knee-jerk" fejlfinding med kun begrænset information. De VMware-specifikke tællere i Performance Monitor kan være en fantastisk måde til hurtigt at bekræfte, at VM'en får de grundlæggende ressourceallokeringer fra værten, før du tager yderligere skridt til at fejlfinde problemet.