I et nyligt tip beskrev jeg et scenarie, hvor en SQL Server 2016-instans syntes at kæmpe med kontrolpunkter. Fejlloggen var udfyldt med et alarmerende antal FlushCache-poster som denne:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Jeg var en smule forvirret over dette problem, da systemet bestemt ikke var sløv - masser af kerner, 3 TB hukommelse og XtremIO-lagring. Og ingen af disse FlushCache-meddelelser blev nogensinde parret med de afslørende 15 sekunders I/O-advarsler i fejlloggen. Alligevel, hvis du stabler en masse databaser med høje transaktioner der, kan kontrolpunktbehandlingen blive ret træg. Ikke så meget på grund af den direkte I/O, men mere afstemning, der skal gøres med et massivt antal beskidte sider (ikke kun fra committed transaktioner) spredt ud over så stor en mængde hukommelse og potentielt venter på lazywriteren (da der kun er én for hele forekomsten).
Jeg læste nogle meget værdifulde indlæg hurtigt "opfrisket":
- Hvordan fungerer kontrolpunkter, og hvad bliver logget
- Databasekontrolpunkter (SQL-server)
- Hvad gør checkpoint for tempdb?
- En SQL Server DBA-myte om dagen:(15/30) checkpoint skriver kun sider fra forpligtede transaktioner
- FlushCache-meddelelser er muligvis ikke en egentlig IO-stall
- Indirekte Checkpoint og tempdb – den gode, den dårlige og den ikke-eftergivende planlægger
- Ændre målet for gendannelsestid for en database
- Sådan virker det:Hvornår føjes FlushCache-meddelelsen til SQL Server-fejllog?
- Ændringer i SQL Server 2016 Checkpoint Behavior
- Målgendannelsesinterval og indirekte kontrolpunkt – ny standard på 60 sekunder i SQL Server 2016
- SQL 2016 – Det kører bare hurtigere:Indirekte kontrolpunkt som standard
- SQL-server:stor RAM og DB Checkpointing
Jeg besluttede hurtigt, at jeg ville spore kontrolpunkters varighed for et par af disse mere besværlige databaser, før og efter at have ændret deres målgendannelsesinterval fra 0 (den gamle måde) til 60 sekunder (den nye måde). Tilbage i januar lånte jeg en Extended Events-session af veninde og canadiske kollega Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Jeg markerede tidspunktet, hvor jeg ændrede hver database, og analyserede derefter resultaterne fra data om udvidede hændelser ved hjælp af en forespørgsel offentliggjort i det originale tip. Resultaterne viste, at efter at have skiftet til indirekte kontrolpunkter, gik hver database fra kontrolpunkter med et gennemsnit på 30 sekunder til kontrolpunkter med et gennemsnit på mindre end en tiendedel af et sekund (og langt færre kontrolpunkter i de fleste tilfælde også). Der er meget at pakke ud af denne grafik, men dette er de rå data, jeg brugte til at præsentere mit argument (klik for at forstørre):
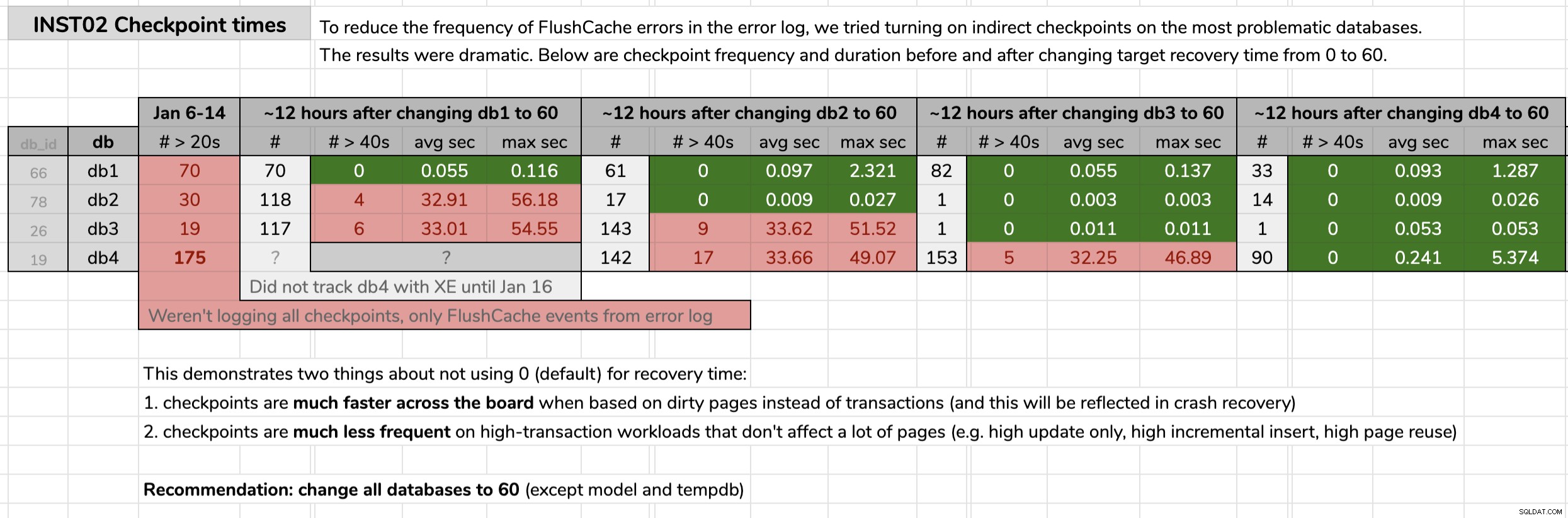 Mine beviser
Mine beviser
Da jeg havde bevist min sag på tværs af disse problematiske databaser, fik jeg grønt lys til at implementere dette på tværs af alle vores brugerdatabaser i hele vores miljø. I dev først, og derefter i produktionen, kørte jeg følgende via en CMS-forespørgsel for at få en målestok for, hvor mange databaser vi talte om:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Nogle bemærkninger om forespørgslen:
database_id > 4
Jeg ønskede ikke at røre vedmasteroverhovedet, og jeg ønskede ikke at ændretempdbendnu fordi vi ikke er på den seneste SQL Server 2017 CU (se KB #4497928 af én grund, at detaljerne er vigtige). Sidstnævnte udelukkermodelogså, fordi ændring af model ville påvirketempdbved næste failover/genstart. Jeg kunne have ændretmsdb, og jeg kan gå tilbage for at gøre det på et tidspunkt, men mit fokus her var på brugerdatabaser.
[state] / is_read_only / is_in_standby
Vi er nødt til at sikre, at de databaser, vi forsøger at ændre, er online og ikke skrivebeskyttede (jeg ramte en, der i øjeblikket var indstillet til skrivebeskyttet, og bliver nødt til at vende tilbage til den senere).
OUTER APPLY (...)
Vi ønsker at begrænse vores handlinger til databaser, der enten er de primære i en AG eller slet ikke i en AG (og også skal tage højde for distribuerede AG'er, hvor vi kan være primære og lokale, men stadig ikke kan skrives) . Hvis du tilfældigvis kører kontrollen på en sekundær, kan du ikke løse problemet der, men du bør stadig få en advarsel om det. Tak til Erik Darling for at hjælpe med denne logik og Taylor Martell for motiverende forbedringer.
- Hvis du har forekomster, der kører ældre versioner som SQL Server 2008 R2 (jeg fandt en!), bliver du nødt til at justere dette lidt, da
target_recovery_time_in_secondskolonne findes ikke der. Jeg var nødt til at bruge dynamisk SQL for at komme uden om dette i ét tilfælde, men du kunne også midlertidigt flytte eller fjerne, hvor disse forekomster falder i dit CMS-hierarki. Du kan heller ikke være doven som mig og køre koden i Powershell i stedet for et CMS-forespørgselsvindue, hvor du nemt kan bortfiltrere databaser givet et hvilket som helst antal egenskaber, før du nogensinde rammer problemer med kompilering.
I produktionen var der 102 forekomster (ca. halvdelen) og 1.590 samlede databaser ved brug af den gamle indstilling. Alt var på SQL Server 2017, så hvorfor var denne indstilling så udbredt? Fordi de blev oprettet, før indirekte kontrolpunkter blev standard i SQL Server 2016. Her er et eksempel på resultaterne:
 Delvise resultater fra CMS-forespørgsel.
Delvise resultater fra CMS-forespørgsel.
Så kørte jeg CMS-forespørgslen igen, denne gang med sys.sp_executesql ukommenteret. Det tog omkring 12 minutter at køre det på tværs af alle 1.590 databaser. Inden for en time fik jeg allerede rapporter om folk, der observerede et betydeligt fald i CPU i nogle af de mere travle tilfælde.
Jeg har stadig mere at lave. For eksempel skal jeg teste den potentielle indvirkning på tempdb , og om der er vægt i vores use case til de rædselshistorier, jeg har hørt. Og vi skal sikre os, at indstillingen på 60 sekunder er en del af vores automatisering og alle anmodninger om oprettelse af databaser, især dem, der er scriptet eller gendannet fra sikkerhedskopier.