Introduktion
Det kan være en vanskelig opgave at finde ud af, hvilken slags databaseinfrastruktur du skal bruge for at matche dine applikationers ydeevne, pålidelighed og skaleringskrav. De valg, du træffer for din databasetopologi, kan påvirke, hvordan hele din applikationsstak reagerer på forskellige typer brug, og hvilke fejlscenarier den kan tage højde for. På grund af dette er det vigtigt at forstå dine muligheder og træffe en informeret beslutning, der stemmer overens med dine mål.
Der er mange forskellige måder at gå fra en enkelt database, der håndterer alle dine infrastrukturbehov, til mere komplekse systemer. Sammen med dette er der mange afvejninger at overveje.
I denne vejledning introducerer vi nogle af de mest almindelige mønstre for relationel databaseinfrastruktur, og hvordan de stemmer overens med forskellige brugsmønstre. Vi gennemgår, hvilke fordele hver konfiguration tilbyder, samt nogle af de mangler, som du skal tage højde for. Vi vil også tale om indflydelsen af forskellige beslutninger på din overordnede operations kompleksitet. Når du er færdig, burde du være i stand til at træffe en bedre beslutning om, hvilke designs der passer bedst til dine nuværende behov, og hvilke muligheder du måtte ønske at eksperimentere med, efterhånden som dine behov ændrer sig.
Skalering lodret
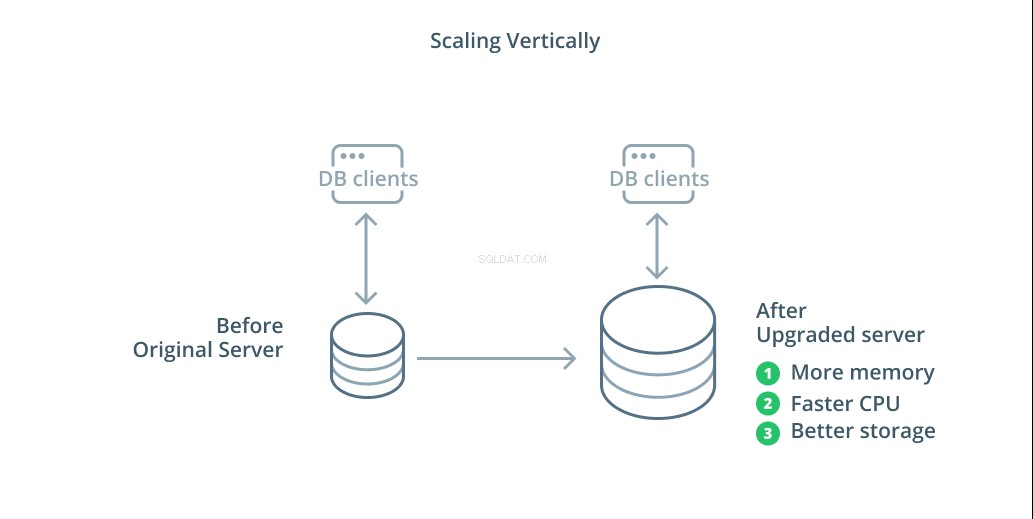
Den enkleste måde at skalere et databasesystem på er lodret skalering. Skalering lodret , også kaldet opskalering , betyder at tilføje kapacitet til den server, der administrerer din database. Ved at øge processorkraften, hukommelsesallokeringen eller lagerkapaciteten kan du øge ydeevnen og volumen, som et databasesystem kan håndtere uden at øge kompleksiteten af systemet som helhed.
Som en generel regel er opskalering af din database et godt første skridt, da det øger din databases muligheder uden at påvirke din infrastrukturtopologi. Opskalering er normalt også ret simpelt, da en maskine med større kapacitet kan konfigureres som en replikeringsfølger, indtil den er synkroniseret, og derefter kan en failover udløses for at gøre den til den nye primære server.
Opskalering har dog sine begrænsninger, fordi mængden af ressourcer, der med rimelighed kan allokeres til én maskine, er begrænset. Det repræsenterer også et enkelt fejlpunkt, hvis ingen replikeringsfølgere er konfigureret til at tage over, når der opstår problemer. Disse bekymringer løses af nogle af de andre skaleringsmuligheder.
Kommandoforespørgselsansvarsadskillelse (CQRS) og skrivebeskyttede replikaer
Den anden primære måde at skalere din databaseinfrastruktur på er at skalere ud. Udskalering betyder, at du i stedet for at øge kapaciteten på en enkelt server øger antallet af servere dedikeret til at betjene et specifikt behov. Så du tilføjer kapacitet ved at tilføje yderligere maskiner til din infrastruktur.
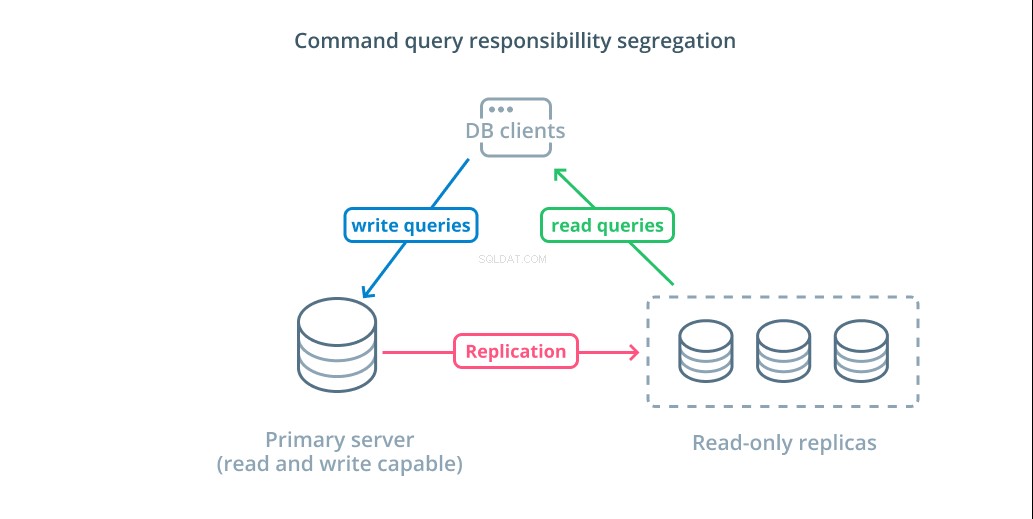
Kommandoforespørgselsansvarsadskillelse (CQRS) er et udtryk, der bruges til at beskrive tilføjelse af logik for at adskille forespørgsler, der muterer data (skrive forespørgsler) fra dem, der ikke gør det (læs forespørgsler). Dette giver dig mulighed for at dirigere disse forskellige kategorier af anmodninger til forskellige værter for at hjælpe med at fordele belastningen.
Den mest basale infrastruktur til at drage fordel af dette design er en primær server, der kan acceptere læse- og skriveforespørgsler kombineret med en eller flere replikaservere efter den primære server, der kan acceptere læseforespørgsler. Dette design er passende til applikationsbrugsmønstre, der er læsetunge, da læseoperationer kan håndteres af enhver af databaseserverne.
Derudover giver dette system en vis redundans til din arkitektur, da systemet stadig vil fungere, hvis nogen af serverne går ned. Hvis en følger går ned, kan læseanmodninger omdirigeres til de andre servere. Hvis den primære server går ned, kan en af replika-følgerne blive forfremmet til at acceptere skriveforespørgsler.
Multi-primær replikering
Mens brug af CQRS med skrivebeskyttede replikaer hjælper dig med at adressere et højere antal læseanmodninger, påvirker det ikke skriveydeevnen af din infrastruktur væsentligt. For at øge antallet af skrivninger, som din arkitektur kan håndtere, skal du overveje, om du kan anvende et multi-primært replikeringsdesign.
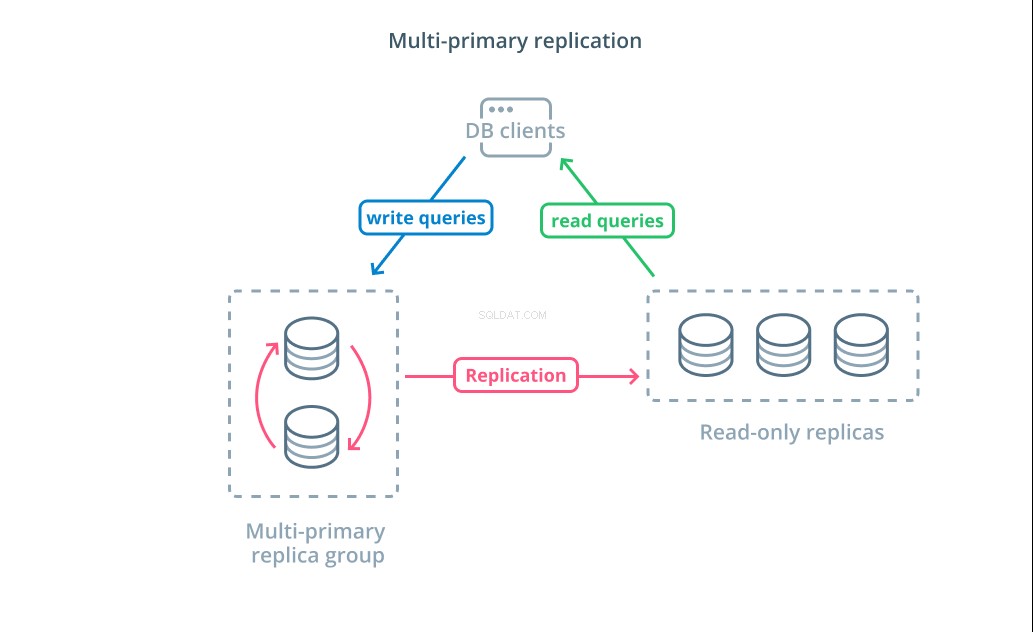
Multi-primær replikering er en form for replikering, hvor flere servere kan acceptere skriveanmodninger. Nogle systemer er konfigureret, så enhver server kan behandle skriveanmodninger, mens andre er designet således, at en kernegruppe af primære servere håndterer skrivninger med et større antal skrivebeskyttede følgere. Uanset implementeringen øger multiprimær replikering antallet af servere, der er ansvarlige for skriveforespørgsler.
Selvom dette design lyder ideelt i starten, er der nogle store udfordringer, der forhindrer dette i at være et bredt vedtaget mønster. Selvom flere servere kan håndtere skriveanmodninger, skal de stadig koordinere for at replikere ændringer mellem deres servere og for at løse konflikter i dataændringer. Dette kan enten føre til lange svartider, efterhånden som konflikter forhandles, eller muligheden for inkonsistente data.
Hvert system vælger deres egen tilgang til at håndtere disse udfordringer. Dette er en demonstration af CAP Theorem — en erklæring, der beskriver samspillet mellem konsistens, tilgængelighed og partitionstolerance i distribuerede systemer — i aktion. Nogle systemer tilbyder svagere konsistensgarantier for at opretholde tilgængeligheden, mens andre databaser nægter at acceptere ændringer, hvis deres peers ikke kan koordinere transaktionen på tidspunktet for skrivningen. At vælge den tilgang, der passer bedst til dine behov, er en vigtig faktor, når du skal vælge mellem forskellige implementeringer.
Læs forespørgselscache
Selvom brug af skrivebeskyttede replikaer er en måde at øge de tilgængelige databaser, der kan reagere på læseanmodninger, forbedrer det ikke den grundlæggende forespørgselsydeevne for komplekse læseoperationer. En af serverne forventes stadig at udføre læseoperationen, hver gang der foretages en anmodning, selvom resultaterne er identiske med det tidligere opslag.
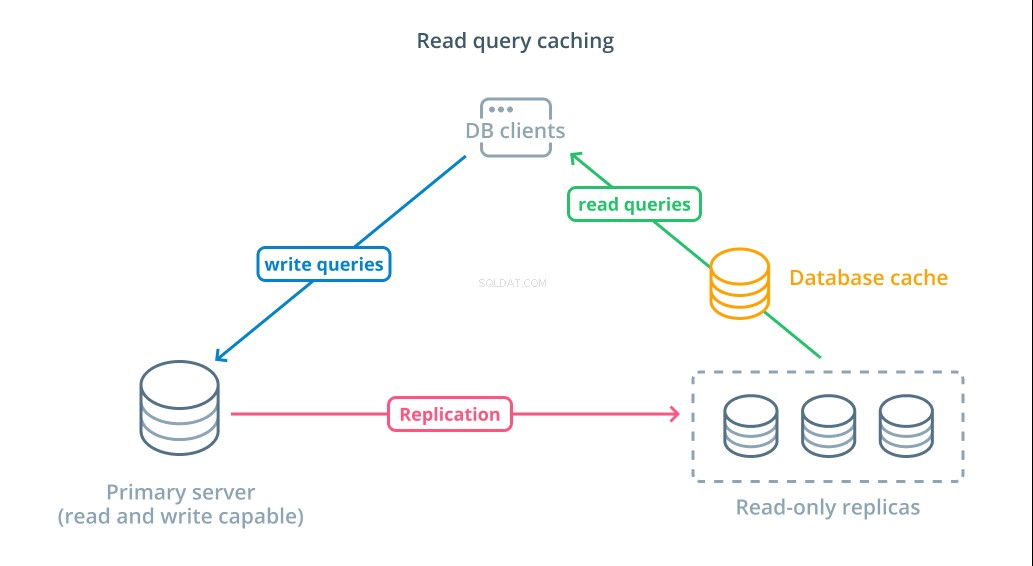
For at reducere svartider, en læse forespørgsel i cache lag kan indføres. Tilføjelse af en cache mellem dine databaseklienter og selve databaserne kan reducere forespørgselstiden for almindelige anmodninger betydeligt. Applikationen kan anmode om læseresultater fra cachen og modtage dem næsten med det samme, hvis de er tilgængelige. I tilfælde, hvor resultaterne ikke findes i cachen, hentes de fra selve databasen og føjes til cachen til næste gang.
Konfiguration af caching på denne måde er utroligt effektivt til scenarier, hvor data sandsynligvis ikke ændres, hver gang anmodningen foretages. Det er især nyttigt for dyre læseforespørgsler, der konsulterer flere tabeller og inkluderer komplekse joinoperationer. Disse resultater kan udføres én gang og derefter gemmes til fremtidige forespørgsler.
I tilfælde, hvor data ændrer sig hurtigere, hjælper en læsecache muligvis ikke nær så meget. Afhængigt af den konfigurerede adfærd risikerer caches at returnere forældede data i disse situationer, og gennemtænkte cache-invalideringsstrategier bør implementeres for at fjerne forældede data fra cachen, når de ændres.
Datasharding
Indtil videre har de designs, vi har diskuteret, segmenteret databasekomponenter baseret på, om de reagerer på skriveanmodninger eller ej. En anden måde at opdele ansvaret på er dog at opdele det faktiske datasæt i flere dele.
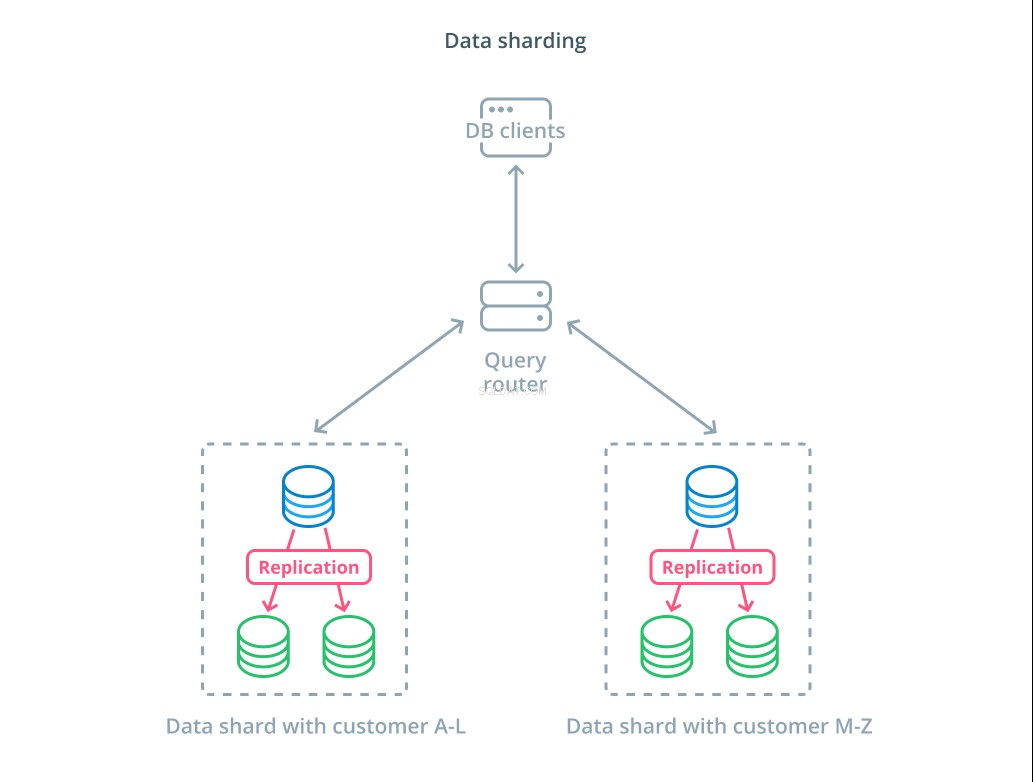
Sharding er processen med at opdele et logisk datasæt i mindre delmængder for at distribuere deres styring til forskellige maskiner. Hver databaseserver håndterer kun en del af dataene, og der introduceres en routingmekaniker, der forstår, hvilke maskiner der er ansvarlige for hvilke datastykker.
Typisk udføres sharding i scenarier, hvor det er unødvendigt eller ualmindeligt at betjene hele datasættet på én gang. Datasættet er segmenteret baseret på hver posts værdi for en specifik nøgle, kendt som sharding-nøglen . For eksempel kan du manuelt sønderdele data baseret på kundernes placering. Du kan også sønderdele automatisk ved hjælp af en hashing-algoritme til at bestemme, hvilke noder der skal håndtere hvilke nøgler. Dette kan hjælpe dit system med at undgå ubalanceret distribution i tilfælde, hvor shard-tasterummet er ujævnt fordelt.
Sharding introducerer en del kompleksitet i datasystemer og er ikke passende til alle scenarier. Operationer, der interagerer med flere shards, vil lide betydelige præstationsstraffe, da de henter resultater fra hvert medlem. Dette kan ske for aggregerede forespørgsler, eller hvis den specifikke shard-nøgle ikke er kendt på forhånd. Derudover kan ujævn fordeling af shards også forårsage ineffektivitet og flaskehalse, der skal rettes ved at ombalancere fordelingen af hele datasættet.
Decentraliseret funktionel datastyring
I stedet for at opdele værdierne af et datasæt i flere segmenter, giver det i mange tilfælde mere mening at bruge forskellige databaser til forskellige funktionelle formål. Hvis du for eksempel har en kontotjeneste og en produkttjeneste, kan det hjælpe dig med at skalere forskellige komponenter uafhængigt af dedikerede databaser, der falder sammen med hver bekymring.
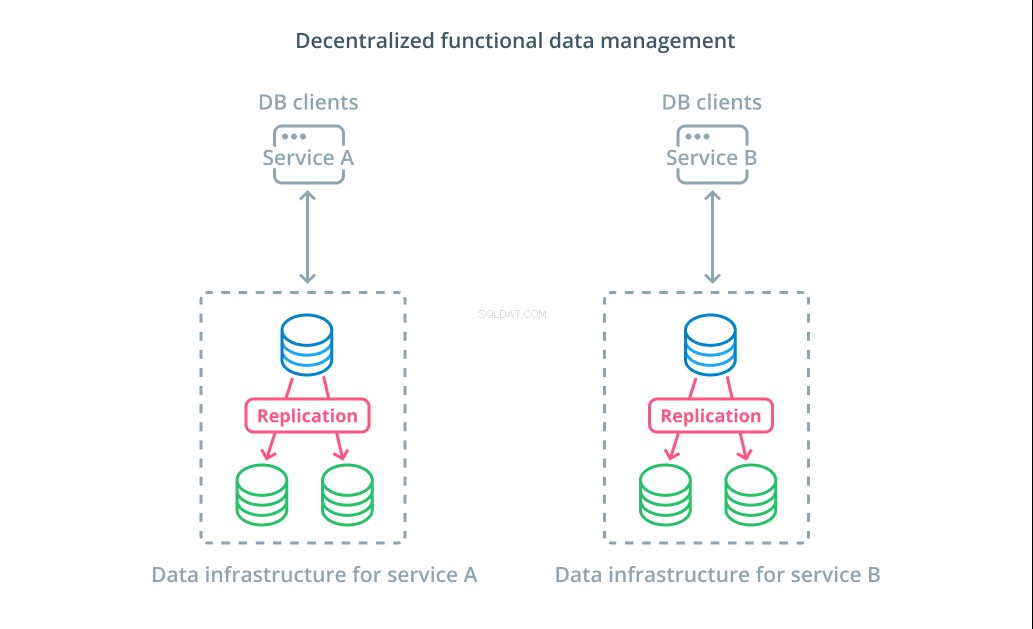
Funktionel datastyring giver dig mulighed for at opdele din databaseinfrastruktur og administrere hver del i overensstemmelse med kundernes behov. Hver funktionel del kan skaleres ved at bruge den strategi, der giver mest mening. Det giver dig mulighed for at designe databaseskemaet og implementere det til en placering, der bedst matcher mønstrene for en specifik use case i stedet for at kræve, at den skal betjene hele organisationen.
For mange organisationer har denne strategi vigtige fordele, der går ud over egenskaberne ved de faktiske systemer. Decentralisering af datastyring kan give mindre teams mulighed for at eje deres egne data uden at koordinere ændringer med andre parter. Det stemmer godt overens med den fokuserede adskillelse af bekymringer fremmet af mikroservice-orienterede applikationsarkitekturer.
Serverløse databaser
De forskellige afvejninger, som du skal evaluere, og mængden af infrastruktur, du kan forventes at administrere for korrekt skalering, kan være overvældende for mange mennesker. En mulighed for at fjerne denne kompleksitet er at drage fordel af databasetjenester, der administrerer infrastruktur og skalerer for dig.
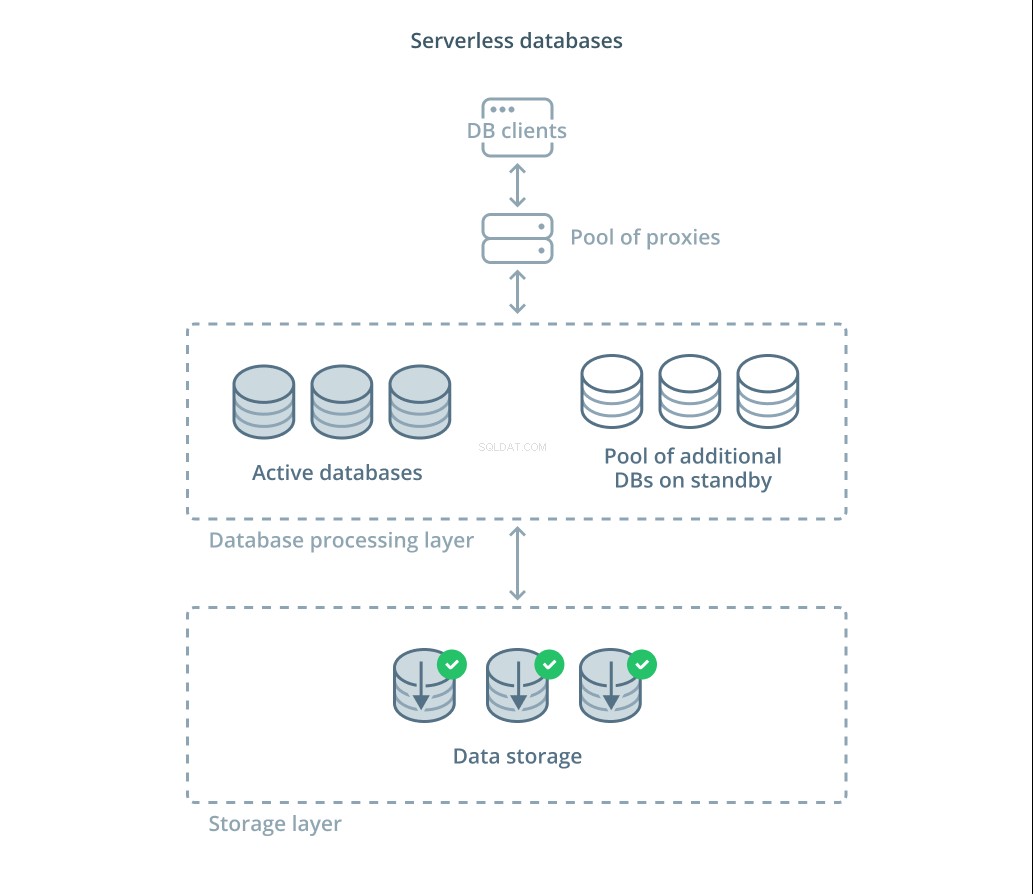
Serverløse databaser er en kategori af tjenester, der afkobler datalagring fra databehandling for nemt at skalere ressourcer som reaktion på ændringer i efterspørgslen.
Et datalagerlag er ansvarlig for at vedligeholde de faktiske data, der administreres af systemet. Foran dette lag er et niveau af skalerbare databasebehandlingsenheder implementeret til at håndtere den faktiske forespørgselsbehandling mod datasættene. Antallet af aktive enheder på et givet tidspunkt er knyttet direkte til det aktuelle forbrug, så flere ressourcer tildeles efterhånden som efterspørgslen topper, og behandlingsenhederne returneres til standby, hvis tingene bliver stille.
Forespørgsler videresendes til databaseprocessorerne gennem en routing-proxy, der ved, hvordan man videresender anmodninger til de aktive noder, og hvornår der skal anmodes om yderligere ressourcer.
Serverløse databaser har mange af de samme egenskaber som traditionelle databasetjenester, der implementerer autoskaleringsfunktioner. Begge kan allokere kapacitet baseret på efterspørgsel. Serverløse databaser giver dig dog mulighed for at adskille lageromkostninger fra behandlingsomkostninger og kan skalere behandlingen ned til nul, når det ikke er nødvendigt. Derudover har serverløse løsninger en tendens til at være i stand til at opskalere meget hurtigere for at imødekomme efterspørgslen sammenlignet med den autoskalering, der tilbydes af traditionelle tilbud.
Selvom serverløse databaser kan være en god pasform for nogle, er de ikke en sølvkugle. I tilfælde hvor databasebehandlerne var nedskaleret til nul, kan der opstå forsinkelser i behandlingen igen på grund af koldstart. Ydermere kan churn gennem forbindelser mellem de forskellige komponenter i en serverløs databasestak føre til yderligere latenstid.
Serverløse databaseplatforme kan også være vanskelige fra et driftsmæssigt synspunkt. Implementeringer og databaseændringer kan være sværere at begrunde og overvåge. Det lokale udviklingsmiljø kan også afvige væsentligt fra produktionsmiljøet på grund af databasesystemets dynamiske tilstand. Og endelig, som med enhver anden cloud-tjeneste, kan brug af serverløse databaser potentielt bringe dig i fare for leverandørlåsning. Det er vigtigt at huske disse afvejninger, når du designer omkring en serverløs platform.
Konklusion
Der er mange måder at designe, implementere og administrere din databaseinfrastruktur på, efterhånden som dine applikationskrav bliver mere seriøse. Hver løsning har sine styrker og begrænsninger, som er vigtige at forstå, når man prøver at finde en løsning, der passer til dit miljø.
At lære om, hvordan databaseinfrastruktur påvirker tilgængeligheden, ydeevnen og integriteten af dine data, giver dig mulighed for at undgå dyre fejl og implementeringer, der ikke giver de garantier, du har brug for. Hvis et af ovenstående designs ikke dækker dine krav, kan du muligvis kombinere nogle af elementerne i forskellige tilgange for at opnå yderligere fordele.
Hvis du gerne vil lære mere om de generelle mønstre, der er dækket ovenfor, er her nogle yderligere ressourcer, som du måske vil tjekke ud:
- Opskalering versus udskalering
- Segregering af kommandoforespørgsel
- Multi-primær replikering
- Caching af læseforespørgsler
- Datasharding
- Decentraliseret datastyring
- Serverløse databaser