Vippepunktet er et udtryk, som jeg første gang hørte brugt af SQL Server-ydelsesjusteringsguruen og mangeårige SentryOne Advisory Board-medlem Kimberly Tripp – hun har en fantastisk blogserie om det her. Vippepunktet er den tærskel, ved hvilken en forespørgselsplan vil "tippe" fra at søge et ikke-dækkende ikke-klynget indeks til at scanne det klyngede indeks eller heap. Den grundlæggende formel, som ikke er en hård og hurtig regel, da der er forskellige andre indflydelsesfaktorer, er denne:
- En klynget indeks (eller tabel) scanning vil ofte forekomme, når anslåede rækker overstiger 33 % af antallet af sider i tabellen
- Et ikke-klynget søge-plusnøgleopslag vil ofte forekomme, når estimerede rækker er under 25 % af siderne i tabellen
- Mellem 25 % og 33 % kan det gå begge veje
Bemærk, at der er andre optimerings-"tipping points", såsom når en dækning indeks vil tippe fra en søgning til en scanning, eller når en forespørgsel vil gå parallelt, men den vi er fokuseret på er det ikke-dækkende ikke-klyngede indeks scenario, fordi det plejer at være det mest almindelige - det er svært at dække alle forespørgsler! Det er også potentielt mest farligt for ydeevnen, og når du hører nogen henvise til SQL Server-indeksets tippepunkt, er det typisk det, de mener.
Tipping Point i tidligere versioner af Plan Explorer
Plan Explorer har tidligere vist nettoeffekten af vippepunktet, når parametersniffing er i spil på indeksanalysen fanen, specifikt via Est(imated) Operation række i Parametre rude:
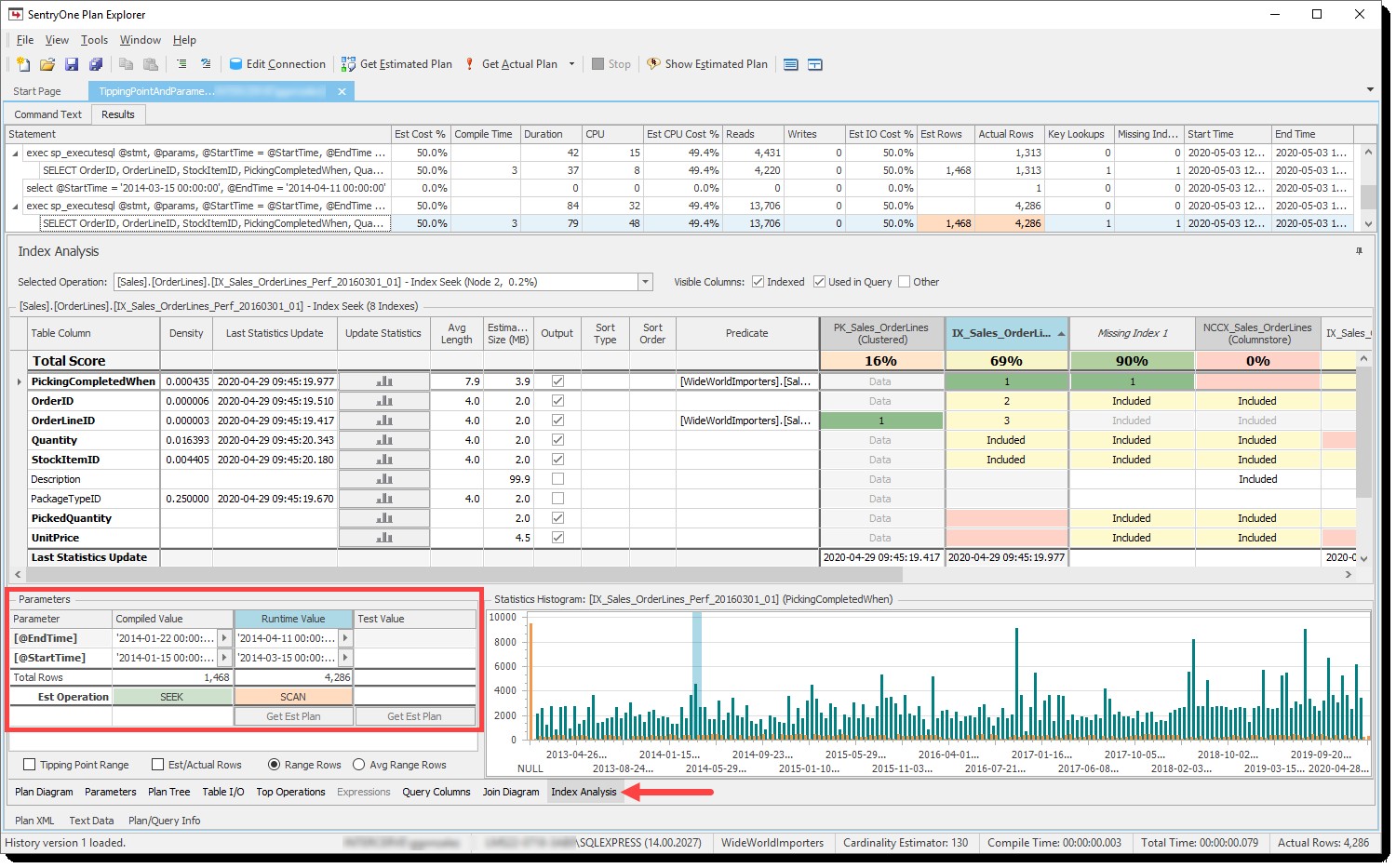 Den estimerede operation for de kompilerede og runtime-parametre baseret på antallet af rækker
Den estimerede operation for de kompilerede og runtime-parametre baseret på antallet af rækker
Hvis du endnu ikke har udforsket indeksanalysemodulet, opfordrer jeg dig til at gøre det. Selvom plandiagrammet og andre Plan Explorer-funktioner er fantastiske, ærligt talt, er indeksanalyse det sted, hvor du skal bruge det meste af din tid, når du tuner forespørgsler og indekser. Tjek Aaron Bertrands dybdegående gennemgang af funktioner og scenarier her, og en fantastisk dækkende indekstutorial af Devon Leann Wilson her.
Bag kulisserne laver vi tipping point-matematikken og forudsiger indeksoperationen (søg eller scanning) baseret på de estimerede rækker og antal sider i tabellen for både de kompilerede og runtime-parametre, og farvekoder derefter de tilknyttede celler, så du kan hurtigt se, om de matcher. Hvis de ikke gør det, som i eksemplet ovenfor, kan det være en stærk indikator for, at du har et parametersniffningsproblem.
Statistikhistogrammet diagrammet afspejler fordelingen af værdier for den førende nøgle i indekset ved hjælp af kolonner for lige store rækker (orange) og rækker med rækker (blågrøn). Dette er de samme værdier, som du får fra DBCC SHOW_STATISTICS eller sys.dm_db_stats_histogram . De dele af distributionen, der rammes af både de kompilerede og runtime-parametre, er fremhævet for at give dig en omtrentlig idé om, hvor mange rækker der er involveret for hver. Du skal blot vælge enten den Kompilerede værdi eller Runtime Value kolonne for at se det valgte område:
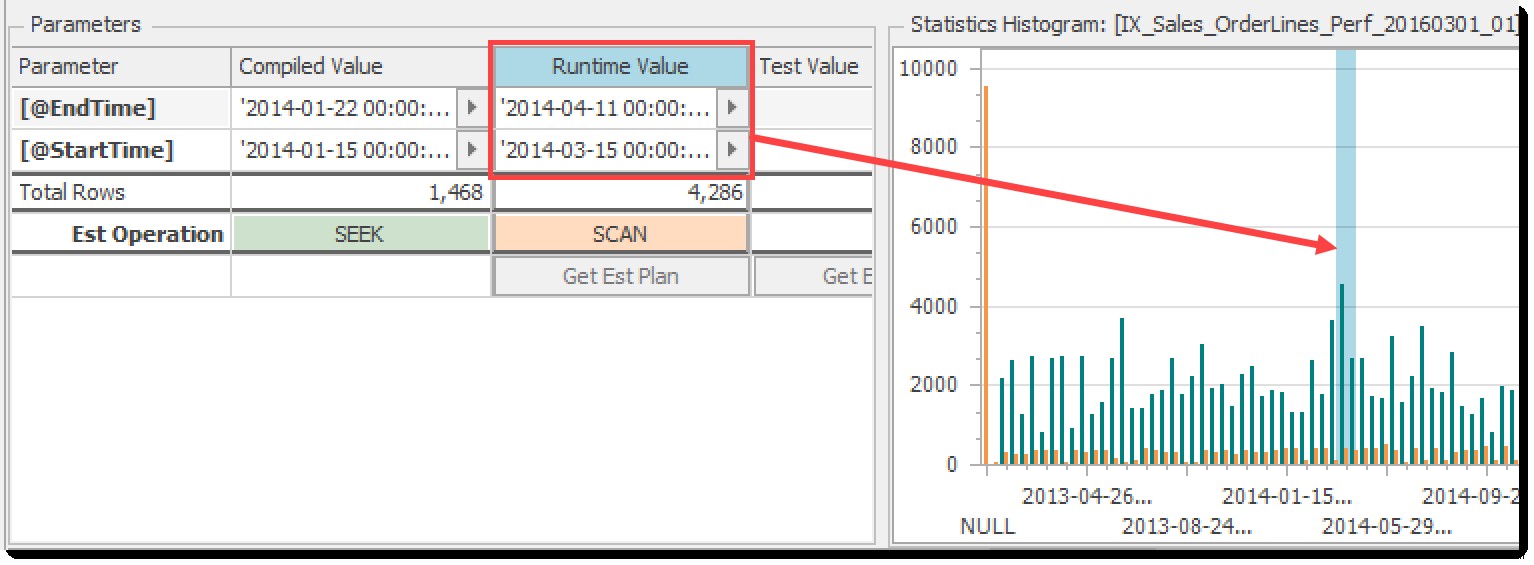 Histogramdiagram, der viser det interval, der rammes af runtime-parametrene
Histogramdiagram, der viser det interval, der rammes af runtime-parametrene
Nye kontroller og billeder
Ovenstående funktioner var gode, men i et stykke tid har jeg følt, at der var mere, vi kunne gøre for at gøre tingene klarere. Så i den seneste udgivelse af Plan Explorer (2020.8.7) har bunden af Parameter-ruden nogle nye kontroller med tilhørende visuals på histogramdiagrammet:
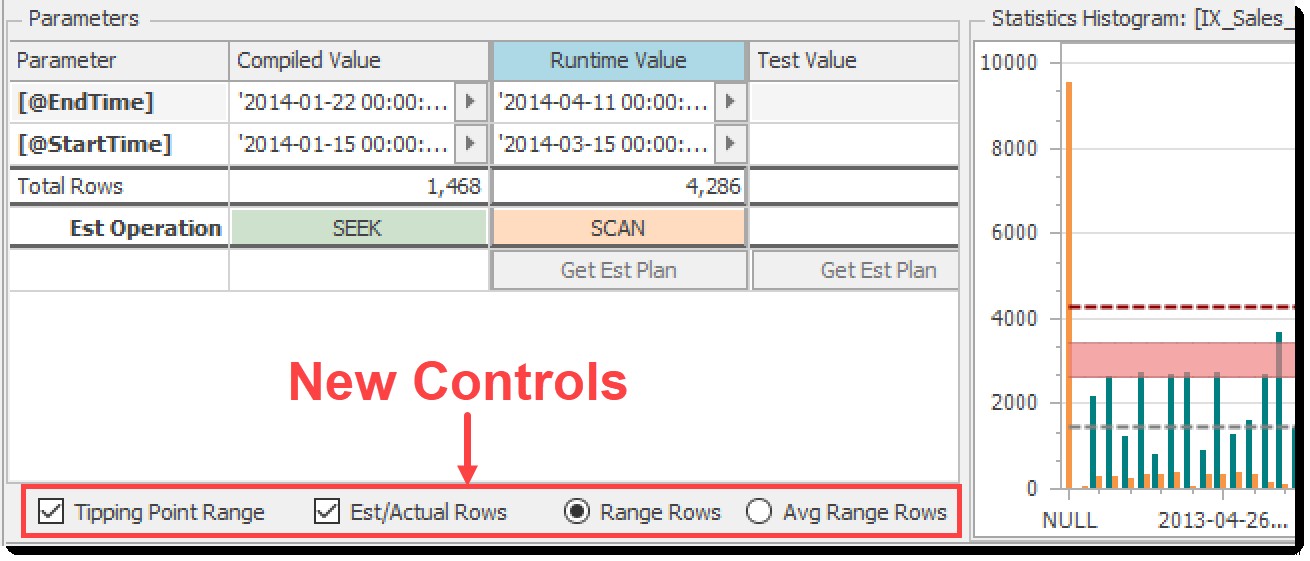 Nye kontroller til histogramvisualiseringer
Nye kontroller til histogramvisualiseringer
Bemærk, at det viste histogram som standard er for det indeks, der bruges af forespørgslen til at få adgang til den valgte tabel, men du kan klikke på en hvilken som helst anden indeksoverskrift eller tabelkolonne i gitteret for at se et andet histogram.
Tipping Point Range
Tipping Point Range afkrydsningsfeltet skifter det lyserøde bånd vist på histogramkortet:
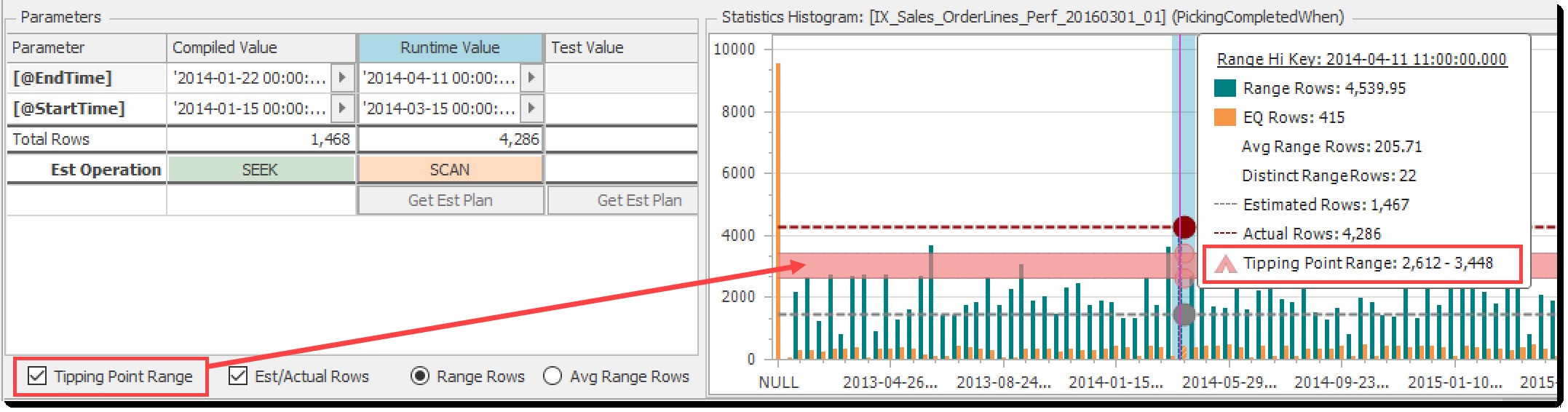 Skift til bånd til tippepunkter
Skift til bånd til tippepunkter
Hvis de estimerede rækker er under dette interval, vil optimeringsværktøjet favorisere en søgning + opslag, og over det en tabelscanning. Inden for rækkevidden er enhvers gæt.
Estimeret(imeret)/faktiske rækker
Anslået/faktisk rækker afkrydsningsfeltet skifter visning af estimerede rækker (fra de kompilerede parametre) og faktiske rækker (fra runtime-parametrene). Pilene i diagrammet nedenfor illustrerer forholdet mellem denne kontrol og de tilknyttede elementer:
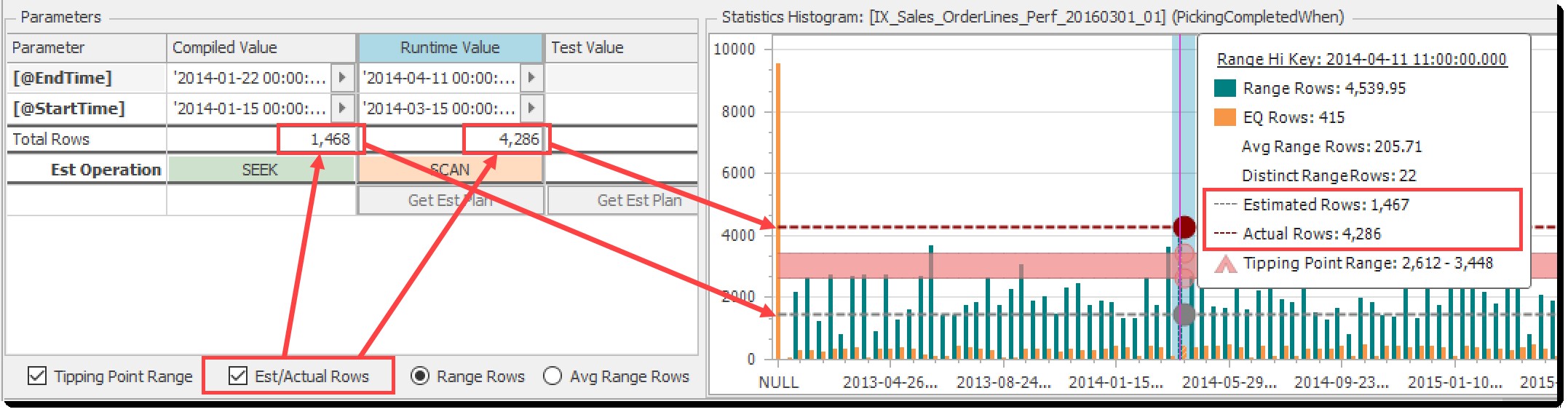 Skift for estimerede og faktiske rækker på histogramdiagrammet
Skift for estimerede og faktiske rækker på histogramdiagrammet
I dette eksempel er det tydeligt, at de estimerede rækker er under vippepunktet, og de faktisk returnerede rækker er over det, hvilket afspejles i forskellen mellem de angivne estimerede og faktiske operationer (Seek vs Scan). Dette er klassisk parametersniffing, illustreret!
I et fremtidigt indlæg vil jeg se nærmere på, hvordan dette korrelerer med det, du ser på plandiagrammet og udsagnsgitteret. I mellemtiden er her en Plan Explorer-sessionsfil, der indeholder dette eksempel (seek-to-scan parameter sniffing) samt et scan-to-seek eksempel. Begge udnytter den udvidede WideWorldImporters-database.
Rækker rækker eller gennemsnitlige rækker
Tidligere versioner af Plan Explorer stablede de lige store rækker og rækker i en kolonne for at repræsentere det samlede antal rækker i en histograminddeling. Dette fungerer godt, når du har et uligheds- eller rækkeviddeprædikat som vist ovenfor, men for lighedsprædikater giver det ikke meget mening. Det, du virkelig vil se, er de gennemsnitlige rækker, da det er det, optimeringsværktøjet vil bruge til estimatet. Desværre var der ingen måde at få dette på.
I det nye Plan Explorer-histogram bruger vi nu i stedet for en stablet kolonneserie klyngede kolonner med lige store rækker og rækker side om side, og dig kontroller, om rækkerne for det samlede eller gennemsnitlige interval skal vises efter behov ved hjælp af Interval rækker / Gns. rækker rækker vælger. Mere om dette snart...
Afslutning
Jeg er virkelig begejstret for disse nye funktioner, og jeg håber, du finder dem nyttige. Prøv dem ved at downloade den nye Plan Explorer. Dette var blot en kort introduktion, og jeg ser frem til at dække nogle forskellige scenarier her. Fortæl os som altid, hvad du synes!