Eksekveringsplaner giver en rig kilde til information, der kan hjælpe os med at identificere måder, hvorpå vi kan forbedre ydeevnen af vigtige forespørgsler. Folk leder ofte efter ting som store scanninger og opslag som en måde at identificere potentielle dataadgangsstioptimeringer. Disse problemer kan ofte hurtigt løses ved at oprette et nyt indeks eller udvide et eksisterende med flere inkluderede kolonner.
Vi kan også bruge efterudførelsesplaner til at sammenligne faktiske med forventede rækkeantal mellem planoperatører. Hvor disse viser sig at være væsentlige afvigende, kan vi forsøge at give bedre statistisk information til optimeringsværktøjet ved at opdatere eksisterende statistik, oprette nye statistikobjekter, bruge statistik på beregnede kolonner eller måske ved at dele en kompleks forespørgsel op i mindre kompleks komponent. dele.
Ud over det kan vi også se på dyre operationer i planen, især hukommelseskrævende som sortering og hashing. Sortering kan nogle gange undgås gennem indekseringsændringer. Andre gange er vi måske nødt til at omfaktorere forespørgslen ved hjælp af syntaks, der favoriserer en plan, der bevarer en bestemt ønsket rækkefølge.
Nogle gange vil ydeevnen stadig ikke være god nok, selv efter at alle disse præstationsjusteringsteknikker er blevet anvendt. Et muligt næste skridt er at tænke lidt mere over planen som helhed . Det betyder at tage et skridt tilbage og prøve at forstå den overordnede strategi, der er valgt af forespørgselsoptimeringsværktøjet, for at se, om vi kan identificere en algoritmisk forbedring.
Denne artikel udforsker denne sidstnævnte type analyse ved at bruge et simpelt eksempel på problem med at finde unikke kolonneværdier i et moderat stort datasæt. Som det ofte er tilfældet i analoge problemer i den virkelige verden, vil kolonnen af interesse have relativt få unikke værdier sammenlignet med antallet af rækker i tabellen. Der er to dele af denne analyse:oprettelse af eksempeldata og selve skrivning af forespørgslen med distinkte værdier.
Oprettelse af prøvedata
For at give det enklest mulige eksempel har vores testtabel kun en enkelt kolonne med et klynget indeks (denne kolonne vil indeholde duplikerede værdier, så indekset ikke kan erklæres unikt):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
For at vælge nogle tal ud af luften, vælger vi at indlæse ti millioner rækker i alt med en jævn fordeling over tusind forskellige værdier . En almindelig teknik til at generere data som denne er at krydsforene nogle systemtabeller og anvende ROW_NUMBER fungere. Vi vil også bruge modulo-operatoren til at begrænse de genererede tal til de ønskede distinkte værdier:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Den estimerede udførelsesplan for den forespørgsel er som følger (klik på billedet for at forstørre det om nødvendigt):

Dette tager omkring 30 sekunder for at oprette prøvedataene på min bærbare computer. Det er på ingen måde et enormt tidsrum, men det er stadig interessant at overveje, hvad vi kan gøre for at gøre denne proces mere effektiv...
Plananalyse
Vi vil starte med at forstå, hvad hver operation i planen er der til.
Sektionen af udførelsesplanen til højre for segmentoperatøren handler om fremstilling af rækker ved krydssammenføjning af systemtabeller:

Segmentoperatoren er der, hvis vinduesfunktionen havde en PARTITION BY klausul. Det er ikke tilfældet her, men det er alligevel med i forespørgselsplanen. Sekvensprojektoperatøren genererer rækkenumrene, og toppen begrænser planens output til ti millioner rækker:

Compute Scalar definerer det udtryk, der anvender modulo-funktionen og tilføjer et til resultatet:

Vi kan se, hvordan etiketterne Sequence Project og Compute Scalar udtryk relaterer sig ved at bruge Plan Explorers faneblad Udtryk:

Dette giver os en mere fuldstændig fornemmelse af strømmen af denne plan:Sequence Project nummererer rækkerne og mærker udtrykket Expr1050; Compute Scalar mærker resultatet af modulo- og plus-one-beregningen som Expr1052 . Bemærk også den implicitte konvertering i Compute Scalar-udtrykket. Destinationstabelkolonnen er af typen heltal, hvorimod ROW_NUMBER funktion producerer en bigint, så en indsnævrende konvertering er nødvendig.
Den næste operatør i planen er en sortering. Ifølge forespørgselsoptimeringsmaskinens omkostningsestimater forventes dette at være den dyreste operation (88,1 % estimeret ):

Det er måske ikke umiddelbart indlysende, hvorfor denne plan indeholder sortering, da der ikke er noget eksplicit bestillingskrav i forespørgslen. Sorteringen føjes til planen for at sikre, at rækker ankommer til Clustered Index Insert-operatoren i grupperet indeksrækkefølge. Dette fremmer sekventiel skrivning, undgår sideopdeling og er en af forudsætningerne for minimalt logget INSERT operationer.
Disse er alle potentielt gode ting, men selve sorten er ret dyr. Faktisk afslører en kontrol af den efterudførelse ("faktiske") eksekveringsplan, at sorteringen også løb tør for hukommelse på udførelsestidspunktet og måtte gå til fysisk tempdb disk:

Sorteringsudslippet sker på trods af, at det estimerede antal rækker er nøjagtigt rigtige, og på trods af at forespørgslen fik al den hukommelse, den bad om (som det ses i planegenskaberne for roden INSERT node):

Sortering af spild er også angivet ved tilstedeværelsen af IO_COMPLETION venter på fanen Plan Explorer PRO ventestatistik:

Læg endelig mærke til DML Request Sort for denne plananalysesektion egenskaben for Clustered Index Insert-operatoren er sat sand:

Dette flag angiver, at optimeringsværktøjet kræver, at undertræet under Indsæt giver rækker i indeksnøglesorteret rækkefølge (derfor behovet for den problematiske sorteringsoperator).
Undgå sorteringen
Nu hvor vi ved hvorfor sorteringen vises, kan vi teste for at se, hvad der sker, hvis vi fjerner det. Der er måder, hvorpå vi kunne omskrive forespørgslen for at "narre" optimeringsværktøjet til at tro, at færre rækker ville blive indsat (så sortering ville ikke være umagen værd), men en hurtig måde at undgå sorteringen direkte (kun til eksperimentelle formål) er at bruge udokumenteret sporingsflag 8795. Dette indstiller DML Request Sort egenskaben til false, så rækker er ikke længere nødvendige for at komme til Clustered Index Insert i klynget nøglerækkefølge:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Den nye forespørgselsplan efter udførelse er som følger (klik på billedet for at forstørre):

Sorteringsoperatoren er forsvundet, men den nye forespørgsel kører i over 50 sekunder (sammenlignet med 30 sekunder Før). Det er der et par grunde til. For det første mister vi enhver mulighed for minimalt loggede inserts, fordi disse kræver sorterede data (DML Request Sort =sand). For det andet vil et stort antal "dårlige" sideopdelinger forekomme under indsættelsen. Hvis det virker kontraintuitivt, skal du huske, at selvom ROW_NUMBER funktionsnumre rækker sekventielt, er effekten af modulo-operatoren at præsentere en gentagende sekvens af tal 1...1000 til Clustered Index Insert.
Det samme grundlæggende problem opstår, hvis vi bruger T-SQL-tricks til at sænke det forventede rækkeantal for at undgå sorteringen i stedet for at bruge det ikke-understøttede sporingsflag.
Undgå Sort II
Ser man på planen som helhed, synes det klart, at vi gerne vil generere rækker på en måde, der undgår en eksplicit sortering, men som stadig høster fordelene ved minimal logning og dårlig sideopdeling. Sagt enkelt:vi ønsker en plan, der præsenterer rækker i grupperet nøglerækkefølge, men uden sortering.
Bevæbnet med denne nye indsigt kan vi udtrykke vores forespørgsel på en anden måde. Den følgende forespørgsel genererer hvert tal fra 1 til 1000 og krydssammenføjninger det sæt med 10.000 rækker for at producere den nødvendige grad af duplikering. Ideen er at generere et indsætningssæt, der præsenterer 10.000 rækker nummereret '1' derefter 10.000 nummereret '2' … og så videre.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Desværre producerer optimeringsværktøjet stadig en plan med en slags:

Der er ikke meget at sige i optimizerens forsvar her, det er bare en tåbelig plan. Den har valgt at generere 10.000 rækker og derefter krydsforbinde dem med tal fra 1 til 1000. Dette tillader ikke, at den naturlige rækkefølge af tallene bevares, så sorteringen kan ikke undgås.
Undgå sorteringen – endelig!
Strategien, som optimizeren gik glip af, er at tage tallene 1...1000 først , og krydssammenføj hvert tal med 10.000 rækker (laver 10.000 kopier af hvert tal i rækkefølge). Den forventede plan ville undgå en sortering ved at bruge en indlejret løkkekrydsforbindelse, der bevarer rækkefølgen af rækkerne på den ydre indgang.
Vi kan opnå dette resultat ved at tvinge optimeringsværktøjet til at få adgang til de afledte tabeller i den rækkefølge, der er angivet i forespørgslen, ved at bruge FORCE ORDER forespørgselstip:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Endelig får vi den plan, vi var ude efter:
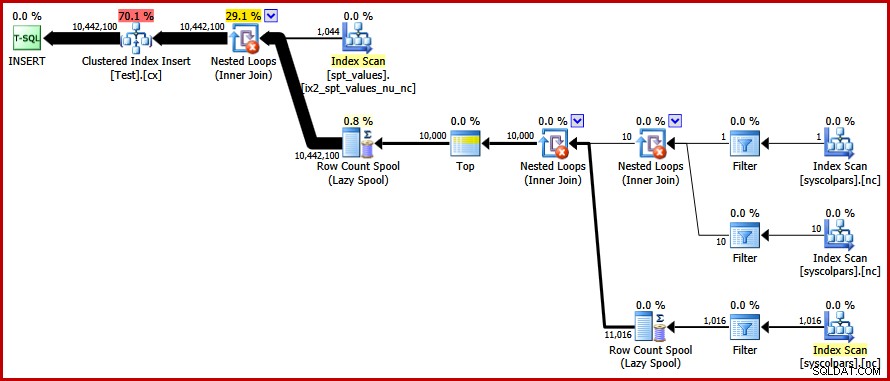
Denne plan undgår en eksplicit sortering, mens den stadig undgår "dårlige" sideopdelinger og muliggør minimalt loggede indsættelser til det klyngede indeks (forudsat at databasen ikke bruger FULL gendannelsesmodel). Den indlæser alle ti millioner rækker på omkring 9 sekunder på min bærbare computer (med en enkelt 7200 rpm SATA roterende disk). Dette repræsenterer en markant effektivitetsforøgelse i løbet af 30-50 sekunder forløbet tid set før omskrivningen.
Sådan finder du de forskellige værdier
Nu vi har oprettet eksempeldataene, kan vi rette vores opmærksomhed mod at skrive en forespørgsel for at finde de forskellige værdier i tabellen. En naturlig måde at udtrykke dette krav på i T-SQL er som følger:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Udførelsesplanen er meget enkel, som du ville forvente:

Dette tager omkring 2900 ms til at køre på min maskine, og kræver 43.406 logisk lyder:

Fjernelse af MAXDOP (1) forespørgselstip genererer en parallel plan:

Dette afsluttes på omkring 1500 ms (men med 8.764 ms forbrugt CPU-tid) og 43.804 logisk lyder:

De samme planer og ydeevne resulterer, hvis vi bruger GROUP BY i stedet for DISTINCT .
En bedre algoritme
Forespørgselsplanerne vist ovenfor læser alle værdier fra basistabellen og behandler dem gennem et Stream Aggregate. Når man tænker på opgaven som helhed, virker det ineffektivt at scanne alle 10 millioner rækker, når vi ved, at der er relativt få distinkte værdier.
En bedre strategi kan være at finde den enkelte laveste værdi i tabellen, derefter finde den næsthøjeste, og så videre, indtil vi løber tør for værdier. Det er afgørende, at denne tilgang egner sig til singleton-søgning i indekset i stedet for at scanne hver række.
Vi kan implementere denne idé i en enkelt forespørgsel ved hjælp af en rekursiv CTE, hvor ankerdelen finder den laveste distinkt værdi, så finder den rekursive del den næste distinkte værdi og så videre. Et første forsøg på at skrive denne forespørgsel er:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Desværre kompilerer den syntaks ikke:

Ok, så aggregerede funktioner er ikke tilladt. I stedet for at bruge MIN , kan vi skrive den samme logik ved at bruge TOP (1) med en ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Stadig ingen glæde.
Det viser sig, at vi kan komme uden om disse begrænsninger ved at omskrive den rekursive del til at nummerere kandidatrækkerne i den påkrævede rækkefølge, og derefter filtrere efter rækken, der er nummereret 'én'. Dette kan virke lidt omstændeligt, men logikken er nøjagtig den samme:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Denne forespørgsel gør kompilerer og producerer følgende plan efter udførelse:

Bemærk Top-operatøren i den rekursive del af udførelsesplanen (fremhævet). Vi kan ikke skrive en T-SQL TOP i den rekursive del af et rekursivt almindeligt tabeludtryk, men det betyder ikke, at optimizeren ikke kan bruge et! Optimeringsværktøjet introducerer toppen baseret på ræsonnement om antallet af rækker, den skal kontrollere for at finde den nummererede '1'.
Ydeevnen af denne (ikke-parallelle) plan er meget bedre end Stream Aggregate-tilgangen. Den afsluttes på omkring 50 ms , med 3007 logiske læsninger mod kildetabellen (og 6001 rækker læst fra spool-arbejdstabellen) sammenlignet med den tidligere bedste af 1500ms (8764 ms CPU-tid ved DOP 8) og 43.804 logisk lyder:


Konklusion
Det er ikke altid muligt at opnå gennembrud i forespørgselsydeevne ved at overveje individuelle forespørgselsplanelementer på egen hånd. Nogle gange er vi nødt til at analysere strategien bag hele eksekveringsplanen og derefter tænke sideværts for at finde en mere effektiv algoritme og implementering.