I de tidligere blogs viste mine kolleger og jeg dig, hvordan du kan overvåge ydeevne, administrere og implementere klynger, køre sikkerhedskopier og endda aktivere automatisk failover for TimescaleDB.
I denne blog vil vi vise dig, hvordan du skalerer din enkelte TimescaleDB-instans til multi-node-klynge med nogle få enkle trin.
Vi starter med en fælles opsætning, en enkelt node-instans, der kører på CentosOS. Noden er i gang, og den bliver allerede overvåget og administreret af ClusterControl.
Hvis du gerne vil lære, hvordan du implementerer eller importerer din TimescaleDB-instans, så tjek bloggen skrevet af min kollega Sebastian Insausti, "Sådan implementerer du nemt TimescaleDB."
Opsætningen ser ud som følger...
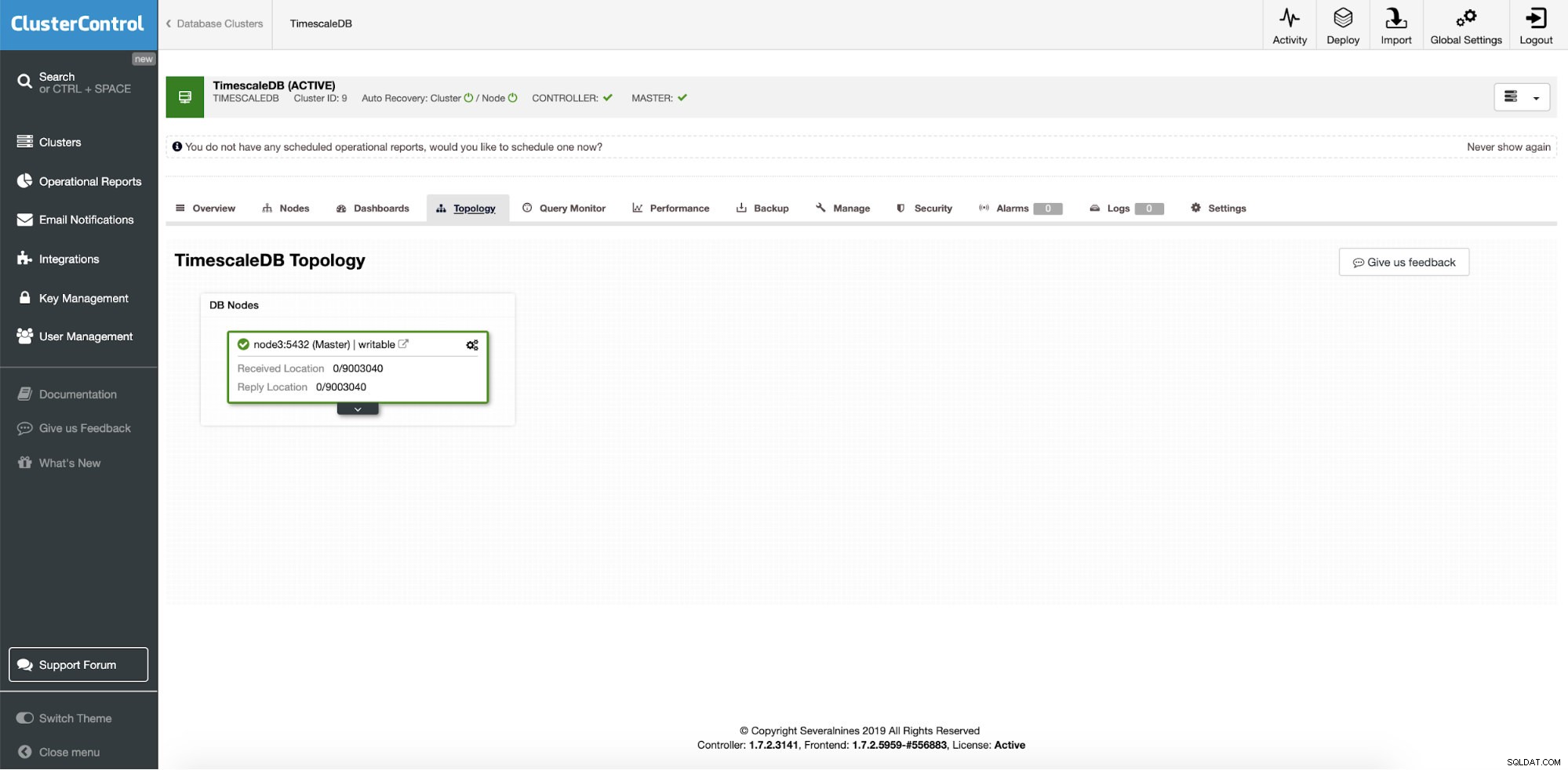 ClusterControl:Single instans TimescaleDB
ClusterControl:Single instans TimescaleDB Så det er en enkelt produktionsinstans, og vi ønsker at konvertere den til klynge uden nedetid. Vores hovedmål er at skalere applikationslæseoperationer til andre maskiner med mulighed for at bruge dem som iscenesættelse af HA-servere, når der skrives servernedbrud.
Flere knudepunkter bør også reducere nedetid for applikationsvedligeholdelse. Ligesom patching anvendt i den rullende genstartstilstand - én node patches ad gangen, mens andre noder betjener databaseforbindelser.
Det sidste krav er at oprette en enkelt adresse til vores nye klynge, så vores nye noder vil være synlige for applikationen fra ét sted.

Vi kan opsummere vores handlingsplan i to store trin:
- Tilføjelse af en replikalæsning
- Installer og konfigurer Haproxy
Tilføjelse af en replika-læsning
Hvis vi går til klyngehandlinger og vælger "Tilføj replikeringsslave", kan vi enten oprette en ny replika fra bunden eller tilføje en eksisterende TimescaleDB-database som en replika.
 ClusterControl:Tilføj replikeringsslave
ClusterControl:Tilføj replikeringsslave 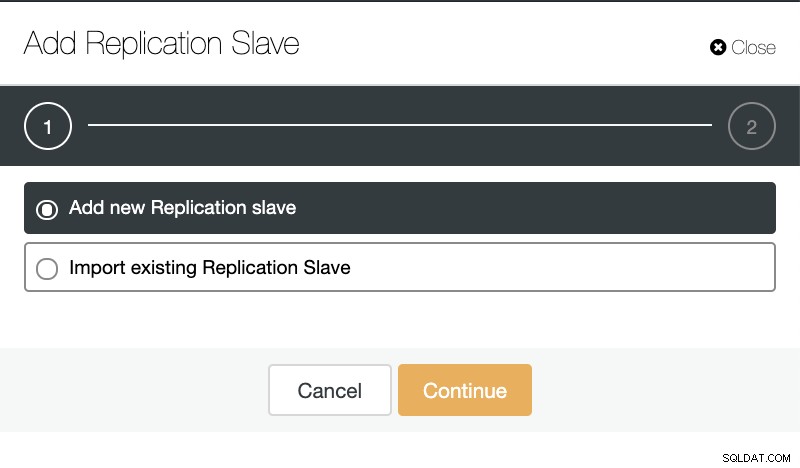 ClusterControl:Tilføj ny replikeringsslave, importer eksisterende replikeringsslave
ClusterControl:Tilføj ny replikeringsslave, importer eksisterende replikeringsslave Som du kan se på billedet nedenfor, skal vi kun vælge vores masterserver, indtaste IP-adressen til vores nye slaveserver og databaseporten.
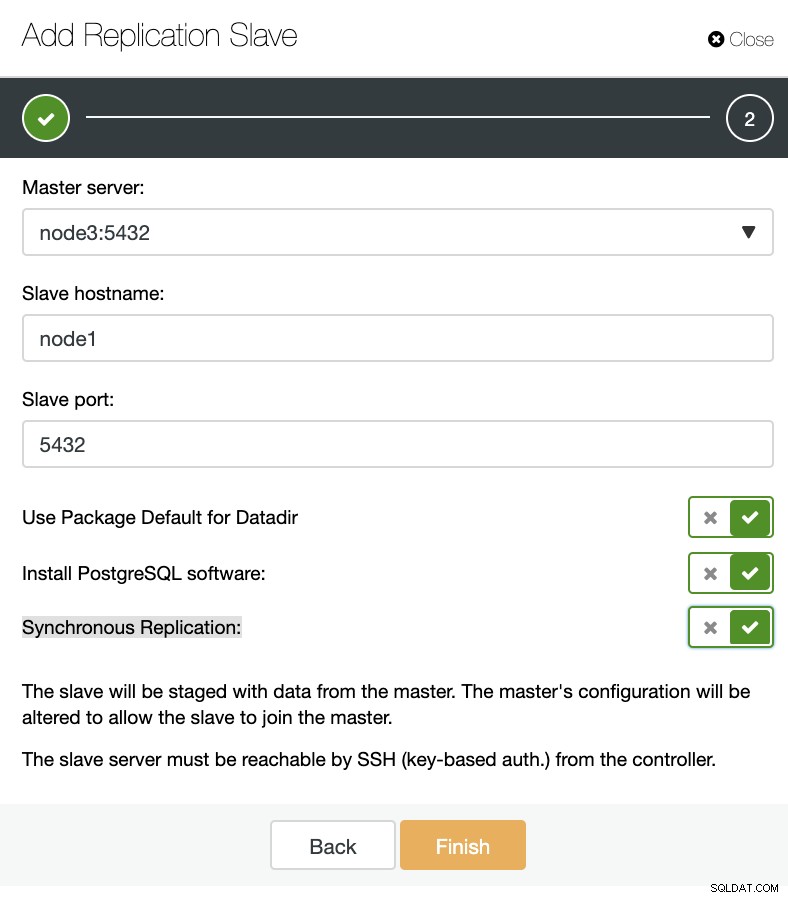 ClusterControl:Tilføj replikeringsslave
ClusterControl:Tilføj replikeringsslave Så kan vi vælge om vi vil have ClusterControl til at installere softwaren for os og om replikeringsslaven skal være Synchronous eller Asynchronous. Når du importerer eksisterende slaveserver, kan du bruge importmuligheden som følger:
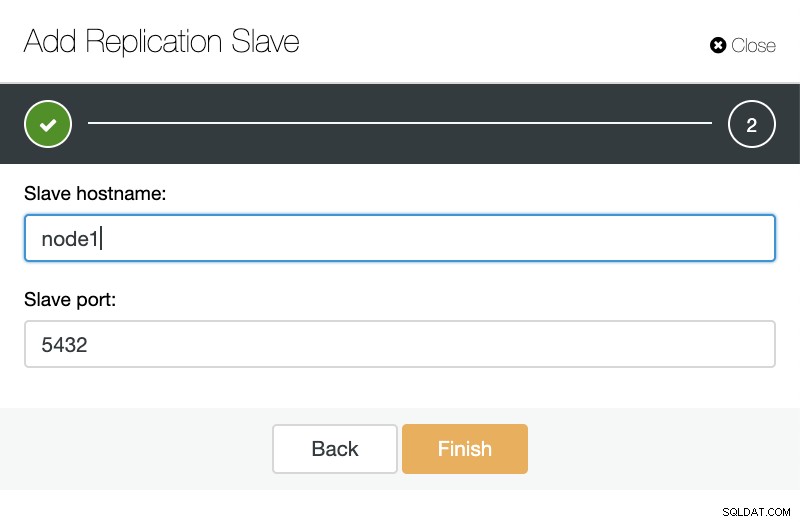 ClusterControl:Importer replikeringsslave til TimescaleDB
ClusterControl:Importer replikeringsslave til TimescaleDB Begge måder kan vi tilføje så mange replikaer, som vi ønsker. I vores eksempeltilfælde tilføjer vi to noder. CusterControl vil oprette et internt job og tage sig af alle de nødvendige trin med én ingen ad gangen.
 ClusterControl:tilføj læst replika
ClusterControl:tilføj læst replika Tilføjelse af en Load Balancer til TimescaleDB
På dette tidspunkt er vores data fordelt på tværs af flere noder eller datacentre, hvis du vælger at tilføje replikeringsslaveknuder et andet sted. Klyngen skaleres ud med to yderligere læse-replikanoder.
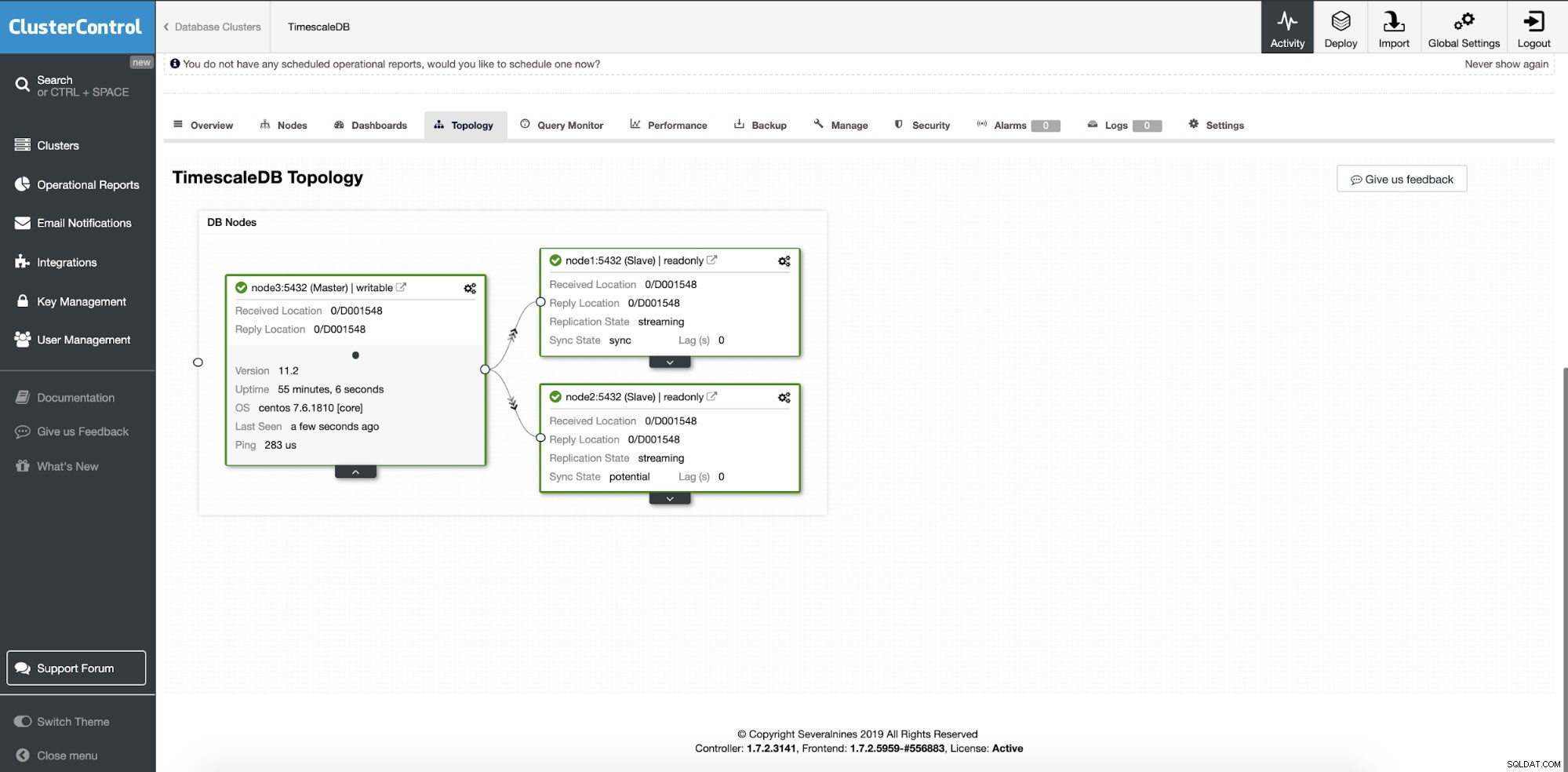 ClusterControl:To noder tilføjet
ClusterControl:To noder tilføjet Spørgsmålet er, hvordan ved applikationen, hvilken databasenode den skal tilgå? Vi vil bruge HAProxy og forskellige porte til skrive- og læseoperationer.
Fra TimescaleDB-klyngen vælger kontekstmenuen at tilføje belastningsbalancer.

Nu skal vi angive placeringen af serveren, hvor Haproxy skal installeres, hvilken politik vi vil bruge til databaseforbindelser, og hvilke noder der indgår i Haproxy-konfigurationen.
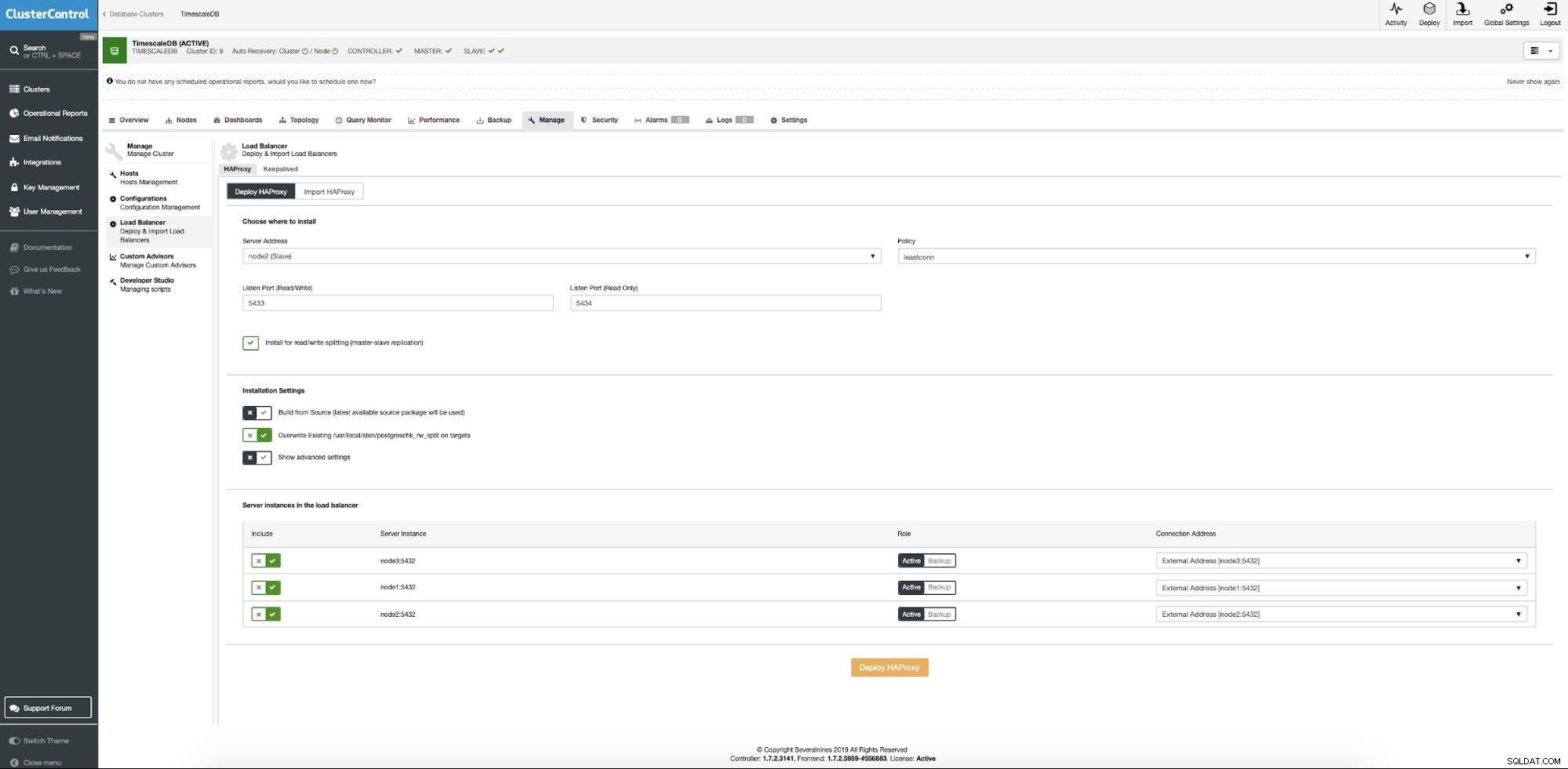
Når alt er indstillet, tryk på deploy-knappen. Efter et par minutter skulle vi gøre vores klyngekonfiguration klar. ClusterControl tager sig af alle forudsætninger og konfigurationer for at implementere load balancer.
Efter en vellykket implementering kan vi se vores nye klynges topologi; med belastningsbalancering og yderligere læseknudepunkter. Med flere noder ombord aktiverer ClusterControl automatisk automatisk gendannelse. På denne måde vil failover-operationen starte af sig selv, når masternoden går ned.
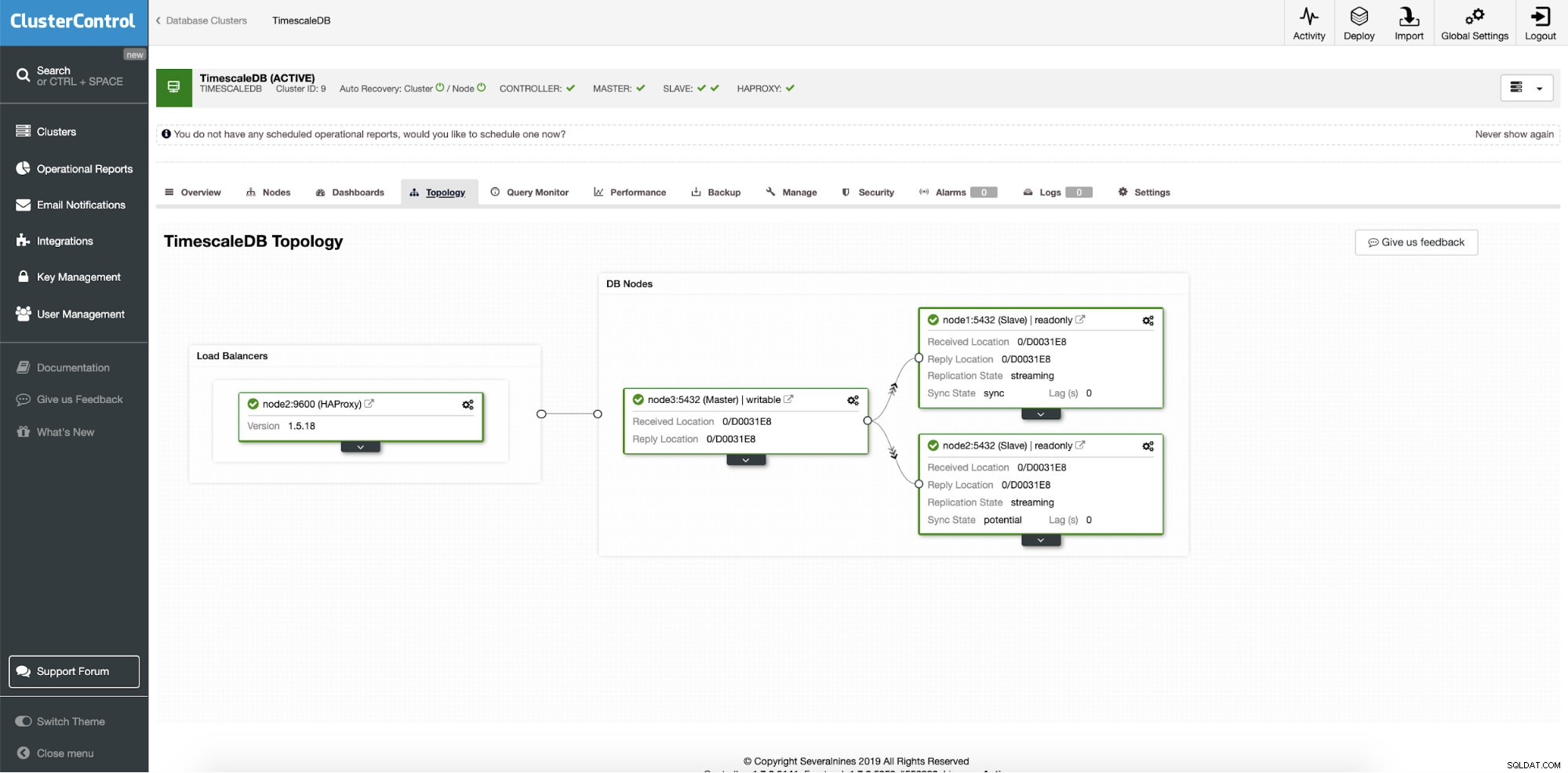 ClusterControl:Endelig topologi
ClusterControl:Endelig topologi Konklusion
TimescaleDB er en open source-database opfundet for at gøre SQL skalerbar til tidsseriedata. At have en automatiseret måde at udvide deres klynge på er nøglen til at opnå ydeevne og effektivitet. Som vi har set ovenfor, kan du nu nemt skalere TimescaleDB ved at bruge ClusterControl.