Tilbage i 2014 startede jeg en række blogindlæg her for at tale om specifikke ventetyper, og hvad de gør og ikke betyder. Det gav mig ideen til at oprette de vente- og låsebiblioteker, som jeg vedligeholder (mere om disse senere).
Hvis du læser dette og tænker "hvad taler han om?" så er dette indlæg noget for dig. Jeg vil introducere dig til ventestatistikker og forklare, hvor kritiske de er for fejlfinding af arbejdsbyrdes ydeevne i SQL Server.
Planlægning
Udførelsen af SQL Servers interne kode udføres ved hjælp af en mekanisme kaldet tråde . Hver tråd kan udføre SQL Server-kode, og flere tråde koordinerer sammen, når en forespørgsel kører parallelt. Disse tråde oprettes, når SQL Server starter, afhængigt af antallet af processorkerner, der er tilgængelige for SQL Server at bruge.
Tråde placeres på en planlægger når en forespørgsel starter, med en planlægger pr. processorkerne, og flyt ikke denne planlægger, før forespørgslen er afsluttet. En skemalægger har tre grundlæggende 'dele':
- processoren , som har præcis én tråd, der i øjeblikket udfører kode.
- Tjenerlisten , som har alle de tråde, der grundlæggende sidder fast og venter på, at en bestemt ressource bliver tilgængelig.
- Den kørbare kø , som har alle de tråde, der er i stand til at udføre, men som venter på at komme på processoren.
Tråde skifter fra tilstand 1 til 2 til 3 til 1, rundt og rundt, indtil forespørgslen er færdig.
Venter
Fra vores perspektiv er den mest interessante del af planlægning, når en tråd skal vente på en ressource, før den kan fortsætte. Nogle eksempler på dette er:
- En tråd skal læse en side, og siden er ikke i hukommelsen, så tråden udsender en asynkron fysisk I/O og skal derefter vente uden for processoren, indtil I/O er færdig.
- En tråd skal anskaffe en delingslås på en række for at læse den, men en anden tråd har allerede en modstridende eksklusiv lås, mens den opdaterer rækken.
Når en tråd støder på behovet for en ressource, som den ikke kan få, har den intet andet valg end at stoppe og vente på, at ressourcen bliver tilgængelig (mekanismen for, hvordan tråden underrettes om ressourcetilgængelighed, ligger uden for denne artikels omfang). Når det sker, noterer SQL Server, hvorfor tråden måtte vente, og dette kaldes ventetypen . Nogle eksempler på dette er:
- Når en tråd venter på, at en side bliver læst ind i hukommelsen, så den kan læses, er ventetypen PAGEIOLATCH_SH (hvis tråden venter på en side, som den vil ændre, er ventetypen PAGEIOLATCH_EX ).
- Når en tråd venter på en delingslås på en række, er ventetypen LCK_M_S (lås-tilstand-deling)
SQL Server holder også styr på, hvor længe tråden skal vente. Dette kaldes ressourceventetiden , og er normalt bare kendt som ventetiden .
Ventstatistik
Det overordnede sæt af metrics for, hvor mange tråde der har ventet på hvilke ressourcer og hvor længe i gennemsnit kaldes ventestatistikker . Disse oplysninger er yderst nyttige til fejlfinding af arbejdsbelastningens ydeevne, da du nemt kan se, hvor ydeevneflaskehalse kan være.
Den grundlæggende idé er, at SQL Server har informationen om, hvorfor tråde skal stoppe og vente, og hvad de venter på. Så i stedet for at skulle gætte på, hvor du skal starte fejlfinding, kan omhyggelig analyse af ventestatistikker normalt pege dig i en retning, du skal tage.
For eksempel, hvis størstedelen af ventetiden på serveren er PAGEIOLATCH_SH , kan dette indikere, at der er hukommelsestryk på serveren, eller at der er forespørgsler, der laver store tabelscanninger i stedet for at bruge ikke-klyngede indekser, eller at der er et problem med det underliggende I/O-undersystem eller en række andre årsager.
Der er et stort antal ventetyper, men de fleste af dem dukker ikke op ret ofte, så der er et kernesæt, som du vil se igen og igen på dine servere. At forstå, hvad disse betyder, og hvordan man undersøger dem, er afgørende, så du ikke bukker under for det, jeg kalder 'knæ-jek-præstationsjustering', og spilder tid og kræfter på at prøve at løse et problem, som faktisk ikke er et problem. Jeg skrev en række blogindlæg her, der går i detaljer der, og Aaron Bertrand skrev også et opsummerende indlæg over top 10 ventestatistikker sidste år.
Sporingsventer
Der er flere måder, hvorpå du kan spore ventetider. Det enkleste er at se på, hvilke ventetider der sker på serveren lige nu, ved at bruge et script, der undersøger sys.dm_os_waiting_tasks DMV. Du kan finde et script til at gøre det her, og som har autogenererede URL'er i ventebiblioteket.
En anden måde er at se på den samlede ventestatistik for hele serveren med et script, der undersøger sys.dm_os_wait_stats DMV. Du kan finde et script til at gøre det her, og som har autogenererede URL'er i ventebiblioteket. Du skal dog være forsigtig med den metode, da den vil vise alle de ventetider, der er sket siden serveren startede. En bedre måde er at spore ventetider over små intervaller, f.eks. en halv time, og et script til at gøre det er her.
Du kan også få ventestatistikker ved at bruge tilføjelsesprogrammet Server Reports til det nye Azure Data Studio-værktøj og bruge Query Store fra SQL Server 2017 og fremefter.
Husk, at du stadig skal forstå, hvad ventetyperne betyder, når du har indsamlet metrics.
Venter-ressourcer
For at hjælpe med dette, og fordi Microsoft ikke har dokumentation for, hvordan man fortolker ventestatistikker, udgav jeg tilbage i 2016 et ventetypebibliotek med detaljer om hundredvis af almindelige ventetyper og hvordan man fejlfinder dem. Du kan komme til biblioteket på https://www.SQLskills.com/help/waits. Og så i 2017 oprettede SentryOne et automatiseret system til at give en infografik for hver side i biblioteket, som du hurtigt kan bruge til at se, om den ventetype, du er interesseret i, er en virkelig almindelig en eller ej (se dette indlæg for detaljer) . Et eksempel på infografik er nedenfor for PAGEIOLATCH_SH vent type:
På den vandrette akse er en skala (som kan skiftes mellem lineær og logaritmisk) af, hvor stor en procentdel af tilfælde (fjernovervåget af SentryOne), der har oplevet denne ventetid i løbet af den foregående kalendermåned, og på den lodrette akse er den procentdel af tid, som de tilfælde, der oplevede det wait havde faktisk en tråd, der ventede på den ventetype.
En anden ressource til at hjælpe dig med at forstå ventetider er et onlinekursus, jeg har optaget for Pluralsight – se her.
I det mindste bør du læse de forskellige blogindlæg i afsnittene Ventestatistik og Sporing af ventetider ovenfor.
Sporing af ventetider ved hjælp af SentryOne-værktøjer
SQL Sentry sporer ventetider på instansniveau på dig automatisk over tid, så du ikke behøver at fange høje ventetider "på akten". Nogen klagede over et trægt system i går eftermiddags eller en rapport, der udløb i tirsdags? Intet problem. Du kan grave ind i alle ventetider på et hvilket som helst tidspunkt eller over en rækkevidde og korrelere dem med forskellige andre præstationsmålinger indsamlet på det tidspunkt – det være sig andre tendenser på dashboardet, såsom backup eller database I/O-aktivitet, hoppe til alle de øverste SQL-kommandoer, der kørte i det samme vindue, undersøgte langvarig blokering, eller brug basislinjer til at sammenligne venteprofilen med andre perioder.
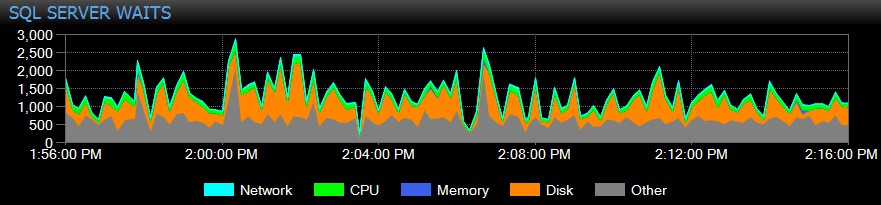
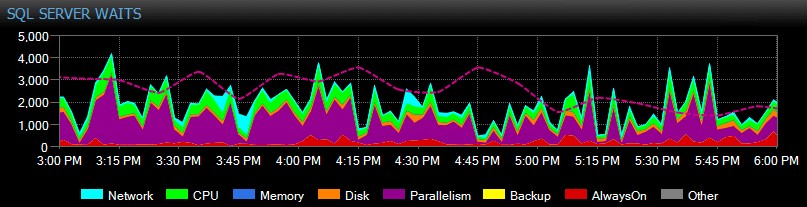
Du kan endda tilpasse ventetider, der er eller ikke indsamles, ændre de kategorier, der præsenteres visuelt, og opbygge intelligente alarmer og/eller svar på specifikke ventescenarier. Mange af vores kunder bruger SQL Sentry til at fokusere på reelle præstationsproblemer i forbindelse med ventetider, da det giver dem mulighed for at ignorere en masse af den støj, der blot er normal SQL Server-trådaktivitet.
Oversigt
Som du kan se fra ovenstående information, sker der altid ventetider i SQL Server, fordi det er sådan trådplanlægning og multi-threaded systemer fungerer. De er et af de mest kraftfulde værktøjer i din fejlfindingsværktøjskasse, så hvis du ikke allerede bruger dem, er det nu, du skal starte. Indlæringskurven er kort og stejl – når du har kørt de forskellige forespørgsler og værktøjer et par gange, får du hurtigt styr på det, og så er det en sag om at læse guiderne igennem for de ventetider, du ser og afgøre, om de er et problem eller ikke.
God fejlfinding!