Jeg nævnte kort, at batch-tilstandsdata er normaliseret i min sidste artikel Batch Mode Bitmaps i SQL Server. Alle data i en batch er repræsenteret af en otte-byte værdi i dette særlige normaliserede format, uanset den underliggende datatype.
Det udsagn rejser uden tvivl nogle spørgsmål, ikke mindst om hvordan data med en længde meget større end otte bytes muligvis kan lagres på den måde. Denne artikel udforsker den batchdata-normaliserede repræsentation, forklarer, hvorfor ikke alle otte-byte datatyper kan passe inden for 64 bits, og viser et eksempel på, hvordan alt dette påvirker batch-tilstands ydeevne.
Demo
Jeg vil starte med et eksempel, der viser batchdataformat, der gør en vigtig forskel for en eksekveringsplan. Du skal bruge SQL Server 2016 (eller nyere) og Developer Edition (eller tilsvarende) for at gengive resultaterne vist her.
Det første, vi skal bruge, er en tabel med bigint tal fra 1 til 102.400 inklusive. Disse tal vil blive brugt til at udfylde en kolonnelagertabel inden længe (antallet af rækker er det minimum, der er nødvendigt for at opnå et enkelt komprimeret segment).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Vellykket samlet pushdown
Følgende script bruger taltabellen til at oprette en anden tabel, der indeholder de samme tal forskudt af en bestemt værdi. Denne tabel bruger kolonnelageret til dets primære lager til at producere batch-mode-udførelse senere.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Kør følgende testforespørgsler mod den nye kolonnelagertabel:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Tilføjelsen i SUM er at undgå overløb. Du kan springe WHERE over klausuler (for at undgå en triviel plan), hvis du kører SQL Server 2017.
Disse forespørgsler drager alle fordel af samlet pushdown. Samlet beregnes ved Søjlelagerindeksscanning snarere end batch-tilstanden Hash Aggregate operatør. Post-udførelsesplaner viser nul rækker udsendt af scanningen. Alle 102.400 rækker var 'lokalt aggregeret'.
SUM planen er vist nedenfor som et eksempel:

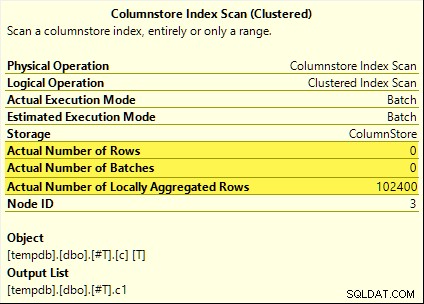
Mislykket samlet pushdown
Slip nu og genskab kolonnelagertesttabellen med forskydningen reduceret med én:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Kør nøjagtig de samme samlede pushdown-testforespørgsler som før:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Denne gang kun COUNT_BIG aggregate opnår samlet pushdown (kun SQL Server 2017). MAX og SUM aggregater ikke. Her er den nye SUM plan for sammenligning med den fra den første test:

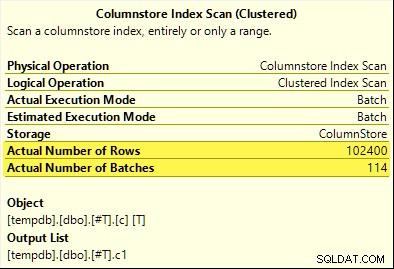
Alle 102.400 rækker (i 114 batches) udsendes af Columnstore Index Scan , behandlet af Compute Scalar , og sendt til Hash Aggregate .
Hvorfor forskellen? Det eneste, vi gjorde, var at udligne rækken af numre, der er gemt i kolonnelagertabellen, med én!
Forklaring
Jeg nævnte i indledningen, at ikke alle otte-byte datatyper kan passe i 64 bit. Dette faktum er vigtigt fordi mange kolonnelager- og batch-mode-ydeevneoptimeringer kun virker med data på 64 bit. Aggregeret pushdown er en af de ting. Der er mange flere ydeevnefunktioner (ikke alle dokumenterede), der kun fungerer bedst (eller overhovedet), når dataene passer i 64 bit.
I vores specifikke eksempel er samlet pushdown deaktiveret for et kolonnelagersegment, når det indeholder endnu et dataværdi, der ikke passer i 64 bit. SQL Server kan bestemme dette ud fra de minimums- og maksimumsværdimetadata, der er knyttet til hvert segment uden at kontrollere alle data. Hvert segment evalueres separat.
Samlet pushdown virker stadig for COUNT_BIG aggregeres kun i den anden test. Dette er en optimering tilføjet på et tidspunkt i SQL Server 2017 (mine tests blev kørt på CU16). Det er logisk ikke at deaktivere samlet pushdown, når vi kun tæller rækker og ikke gør noget med de specifikke dataværdier. Jeg kunne ikke finde nogen dokumentation for denne forbedring, men det er ikke så usædvanligt i disse dage.
Som en sidebemærkning bemærkede jeg, at SQL Server 2017 CU16 muliggør samlet pushdown for de tidligere ikke-understøttede datatyper real , float , datetimeoffset og numeric med mere præcision end 18 — når dataene passer i 64 bit. Dette er også udokumenteret i skrivende stund.
Ok, men hvorfor?
Du stiller måske det meget rimelige spørgsmål:Hvorfor fungerer et sæt bigint testværdier passer tilsyneladende i 64 bit, men den anden gør ikke?
Hvis du gættede, var årsagen relateret til NULL , giv dig selv et kryds. Selvom testtabelkolonnen er defineret som NOT NULL , SQL Server bruger det samme normaliserede datalayout til bigint om dataene tillader nuller eller ej. Det er der grunde til, som jeg vil pakke ud lidt efter lidt.
Lad mig starte med nogle observationer:
- Hver kolonneværdi i en batch gemmes i nøjagtigt otte bytes (64 bit) uanset den underliggende datatype. Dette layout i fast størrelse gør alt nemmere og hurtigere. Udførelse af batchtilstand handler om hastighed.
- En batch er 64 KB i størrelse og indeholder mellem 64 og 900 rækker, afhængigt af antallet af kolonner, der projiceres. Dette giver mening, da kolonnedatastørrelserne er fastsat til 64 bit. Flere kolonner betyder, at der kan passe færre rækker i hver 64KB batch.
- Ikke alle SQL Server-datatyper kan passe i 64 bit, selv i princippet. En lang streng (for at tage et eksempel) passer måske ikke engang i en hel 64KB batch (hvis det var tilladt), endsige en enkelt 64-bit post.
SQL Server løser dette sidste problem ved at gemme en 8-byte reference til data større end 64 bit. Den 'store' dataværdi gemmes et andet sted i hukommelsen. Du kan kalde dette arrangement "off-row" eller "out-of-batch" opbevaring. Internt omtales det som dybe data .
Nu kan otte-byte datatyper ikke passe i 64 bit, når de er nullable. Tag bigint NULL for eksempel . Ikke-nul-dataområdet kræver muligvis de fulde 64 bit, og vi har stadig brug for en anden bit for at angive null eller ej.
Løsning af problemerne
Den kreative og effektive løsning på disse udfordringer er at reservere den laveste betydende bit (LSB) af 64-bit værdien som et flag. Flaget angiver in-batch datalagring, når LSB er ryddet (sat til nul). Når LSB er indstillet (til én), kan det betyde en af to ting:
- Værdien er null; eller
- Værdien gemmes off-batch (det er dybe data).
Disse to tilfælde er kendetegnet ved tilstanden af de resterende 63 bit. Når de alle er nul , værdien er NULL . Ellers er 'værdien' en pegepind til dybe data, der er lagret andetsteds.
Når det ses som et heltal, betyder indstilling af LSB, at pointere til dybe data altid vil være ulige tal. Nuller er repræsenteret af det (ulige) tal 1 (alle andre bits er nul). In-batch data er repræsenteret ved lige tal, fordi LSB er nul.
Dette gør ikke betyder, at SQL Server kun kan gemme lige tal inden for en batch! Det betyder bare, at den normaliserede repræsentation af de underliggende kolonneværdier vil altid have en nul LSB, når de opbevares "in-batch". Dette vil give mere mening om et øjeblik.
Batchdatanormalisering
Normalisering udføres på forskellige måder, afhængigt af den underliggende datatype. For bigint processen er:
- Hvis dataene er null , gem værdien 1 (kun LSB indstillet).
- Hvis værdien kan repræsenteres i 63 bit , skift alle bits ét sted til venstre og nul LSB. Når man ser på værdien som et heltal, betyder det fordobling værdien. For eksempel
bigintværdi 1 er normaliseret til værdien 2. I binær er det syv bytes helt nul efterfulgt af00000010. Når LSB er nul, indikerer det, at dette er data, der er lagret inline. Når SQL Server har brug for den oprindelige værdi, flytter den 64-bit værdien til højre med én position (smid LSB flaget væk). - Hvis værdien ikke kan være repræsenteret i 63 bit, lagres værdien off-batch som dybe data . In-batch-markøren har LSB indstillet (gør det til et ulige tal).
Processen med at teste, om en bigint værdien kan passe i 63 bit er:
- Gem den rå*
bigintværdi i 64-bit processorregisterr8. - Gem den dobbelte værdi af
r8i registeretrax. - Skift bits af
raxét sted til højre. - Test om værdierne i
raxogr8er lige.
* Bemærk, at råværdien ikke kan bestemmes pålideligt for alle datatyper ved en T-SQL-konvertering til en binær type. T-SQL-resultatet kan have en anden byte-rækkefølge og kan også indeholde metadata, f.eks. time brøksekund præcision.
Hvis testen i trin 4 består, ved vi, at værdien kan fordobles og derefter halveres inden for 64 bit – og den oprindelige værdi bevares.
Et reduceret område
Resultatet af alt dette er, at rækkevidden af bigint værdier, der kan gemmes i batch, er reduceret med en bit (fordi LSB ikke er tilgængelig). Følgende inklusive områder af bigint værdier vil blive gemt off-batch som dybe data :
- -4.611.686.018.427.387.905 til -9.223.372.036.854.775.808
- +4.611.686.018.427.387.904 til +9.223.372.036.854.775.807
Til gengæld for at acceptere, at disse bigint områdebegrænsninger, normalisering tillader SQL Server at gemme (de fleste) bigint værdier, nuller og dybe datareferencer i-batch . Dette er meget enklere og mere pladseffektivt end at have separate strukturer til nullbarhed og dybe datareferencer. Det gør også behandling af batchdata med SIMD-processorinstruktioner meget nemmere.
Normalisering af andre datatyper
SQL Server indeholder normalisering kode for hver af de datatyper, der understøttes af batch-tilstand. Hver rutine er optimeret til at håndtere det indgående binære layout effektivt og til kun at skabe dybe data, når det er nødvendigt. Normalisering resulterer altid i, at LSB reserveres til at angive nuller eller dybe data, men layoutet af de resterende 63 bit varierer fra datatype.
Altid i batch
Normaliserede data for følgende datatyper er altid gemt i batch da de aldrig har brug for mere end 63 bit:
datetime(n)– omskaleret internt tiltime(7)datetime2(n)– omskaleret internt tildatetime2(7)integersmallinttinyintbit– brugertinyintimplementering.smalldatetimedatetimerealfloatsmallmoney
Det afhænger af
Følgende datatyper kan lagres in-batch eller dybe data afhængigt af dataværdien:
bigint– som beskrevet tidligere.money– samme område i batch sombigintmen divideret med 10.000.numeric/decimal– 18 decimalcifre eller færre i batch uanset af erklæret præcision. For eksempeldecimal(38,9)værdi -999999999.999999999 kan repræsenteres som 8 byte heltal -999999999999999999 (f21f494c589c0001hex), som kan fordobles til -19999999999999999998 (e43e9298b1380002hex) reversibelt inden for 64 bit. SQL Server ved, hvor decimaltegnet går fra datatypeskalaen.datetimeoffset(n)– in-batch hvis runtime-værdien vil passe ind idatetimeoffset(2)uanset af deklarerede brøksekunders præcision.timestamp– det interne format er forskelligt fra displayet. For eksempel ettimestampvist fra T-SQL som0x000000000099449Aer repræsenteret internt som9a449900 00000000(i hex). Denne værdi gemmes som dybe data, fordi den ikke passer i 64-bit, når den fordobles (forskydes til venstre en bit).
Altid dybe data
Følgende er altid gemt som dybe data (undtagen nuller) :
uniqueidentifiervarbinary(n)– inklusive(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameinklusive(max)– disse typer kan også bruge en ordbog (hvis tilgængelig).text/ntext/image/xml– brugervarbinary(n)implementering.
For at være klar, nuller for alle batch-mode kompatible datatyper gemmes i batch som den specielle værdi "one".
Sidste tanker
Du kan forvente at få det bedste ud af de tilgængelige kolonnelager- og batch-tilstandsoptimeringer, når du bruger datatyper og værdier, der passer i 64 bit. Du vil også have den bedste chance for at drage fordel af trinvise produktforbedringer over tid, for eksempel de seneste forbedringer til aggregeret pushdown, der er noteret i hovedteksten. Ikke alle præstationsfordelene vil være så synlige i udførelsesplaner eller endda dokumenterede. Ikke desto mindre kan forskellene være ekstremt betydelige.
Jeg bør også nævne, at data normaliseres, når en række-mode eksekveringsplan operatør leverer data til en batch-mode forælder, eller når en non-columnstore scanning producerer batches (batch mode på rowstore). Der er en usynlig række-til-batch-adapter, der kalder den relevante normaliseringsrutine på hver kolonneværdi, før den tilføjes til batchen. At undgå datatyper med kompliceret normalisering og dyb datalagring kan også give ydeevnefordele her.