Introduktion
Det er almindeligt kendt i databasekredse, at indekser forbedrer forespørgselsydeevne enten ved at opfylde det krævede resultatsæt fuldstændigt (Covering Indexes) eller ved at fungere som opslag, der nemt dirigerer forespørgselsmotoren til den nøjagtige placering af det påkrævede datasæt. Men som erfarne DBA'er ved, bør man ikke være for begejstret for at skabe indekser i OLTP-miljøer uden at forstå arten af arbejdsbyrden. Ved at bruge Query Store i SQL Server 2019-instansen (Query Store blev introduceret i SQL Server 2016), er det ret nemt at vise effekten af et indeks på inserts.
Indsæt uden indeks
Vi starter med at gendanne WideWorldImporters Sample-databasen og derefter oprette en kopi af Salget. Fakturatabel ved hjælp af scriptet i liste 1. Bemærk, at prøvedatabasen allerede har aktiveret Query Store i læse-skrivetilstand.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Bemærk, at der slet ikke er nogen indekser i den tabel, vi lige har oprettet. Det eneste, vi har, er bordstrukturen. Når det er gjort, udfører vi indsættelser i den nye tabel ved hjælp af data fra dens overordnede som vist i liste 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Under denne operation fanger Query Store forespørgslens udførelsesplan. Figur 1 viser kort, hvad der sker under emhætten. Når vi læser fra venstre mod højre, ser vi, at SQL Server udfører indsættelserne ved hjælp af Plan ID 563 – en indeksscanning på kildetabellens primære nøgle for at hente dataene og derefter en tabelindsættelse på destinationstabellen. (Læser fra venstre mod højre). Bemærk, at i dette tilfælde er hovedparten af omkostningerne på tabelindlægget – 99 % af forespørgselsomkostningerne.
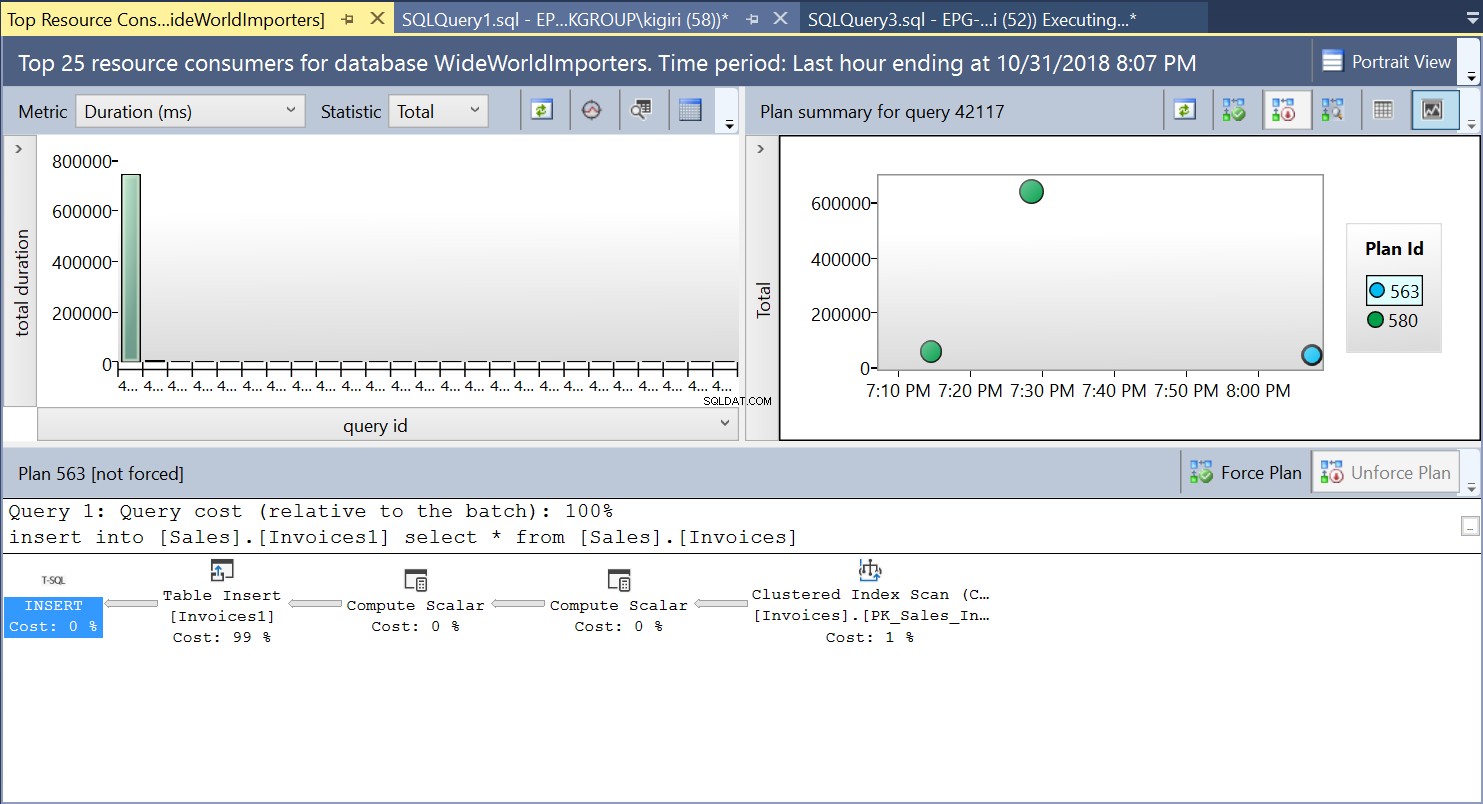
Fig. 1 Udførelsesplan 563
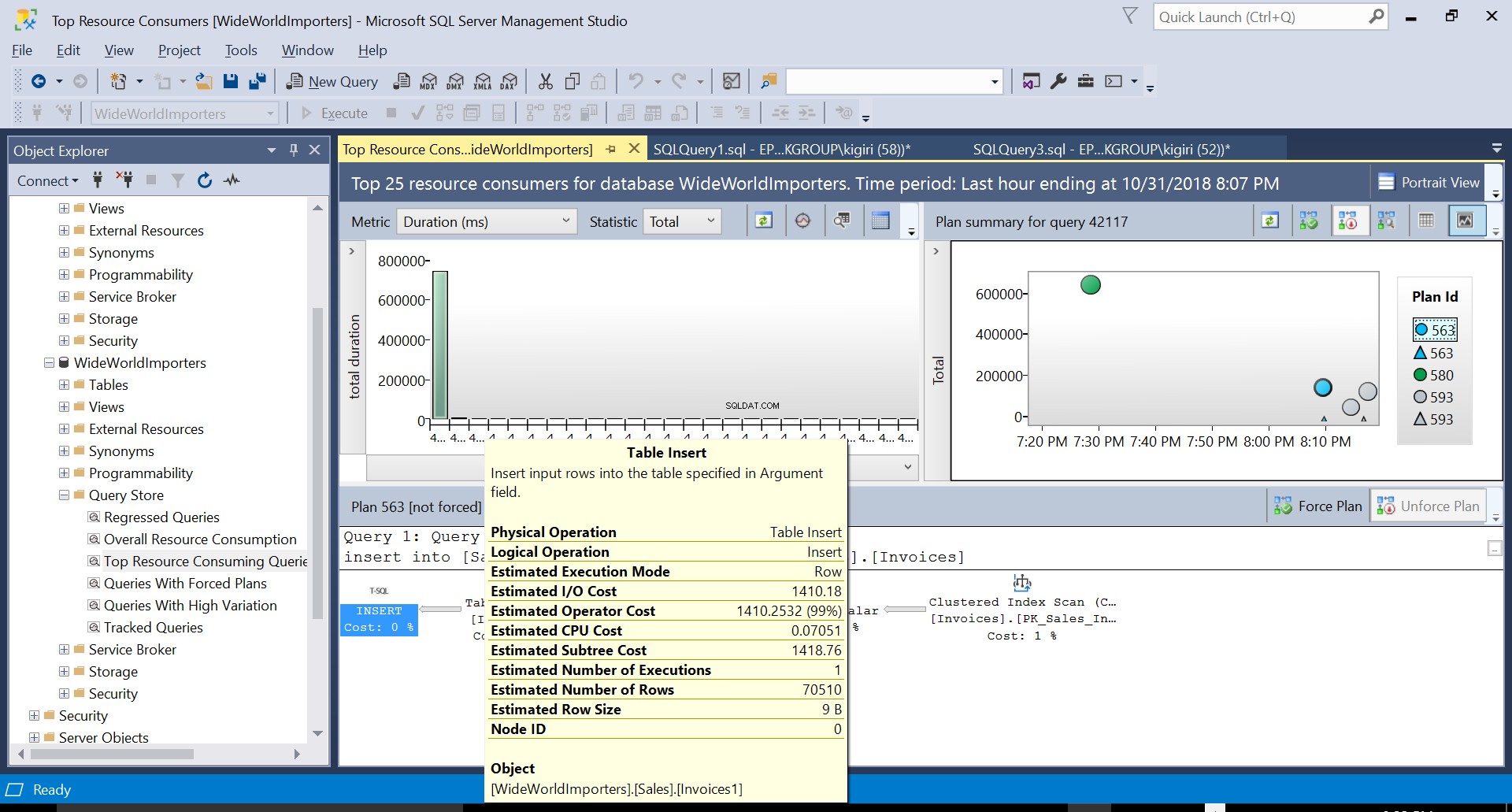
Fig. 2 Tabel Indsæt på destination
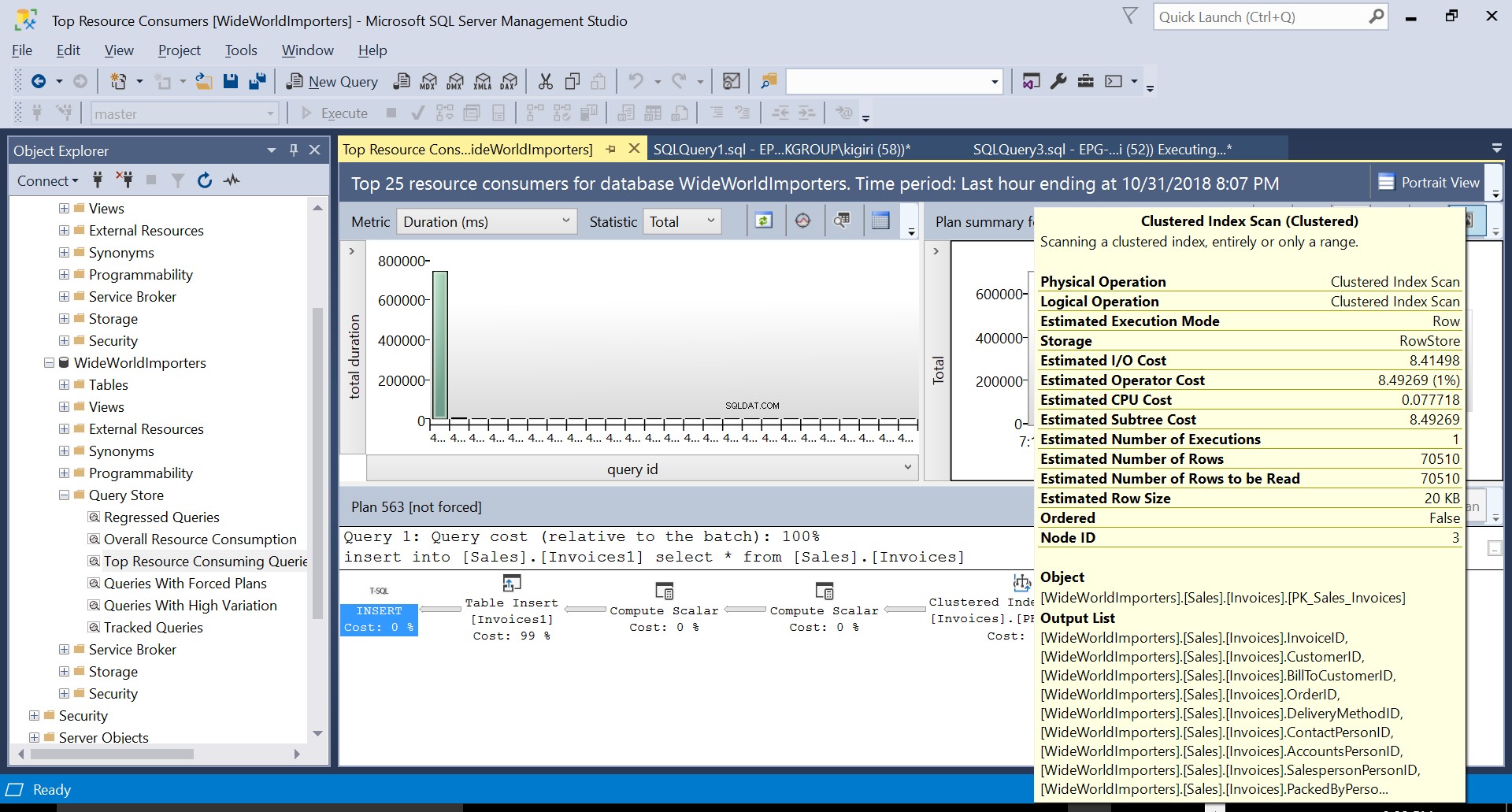
Fig. 3 Clustered Index Scan på kildetabel
Indsæt med indeks
Vi opretter derefter et indeks på destinationstabellen ved hjælp af DDL i Listing 3. Når vi gentager sætningen i Listing 2 efter at have trunkeret destinationstabellen, ser vi en lidt anderledes eksekveringsplan (Plan ID 593 vist i Fig. 4). Vi ser stadig tabelindsættelsen, men den bidrager kun med 58 % til prisen for forespørgslen. Udførelsesdynamikken er lidt skæv med introduktionen af en sortering og en Index Insert. Det, der i bund og grund sker, er, at SQL Server skal indføre tilsvarende rækker på indekset, efterhånden som nye poster introduceres i tabellen.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
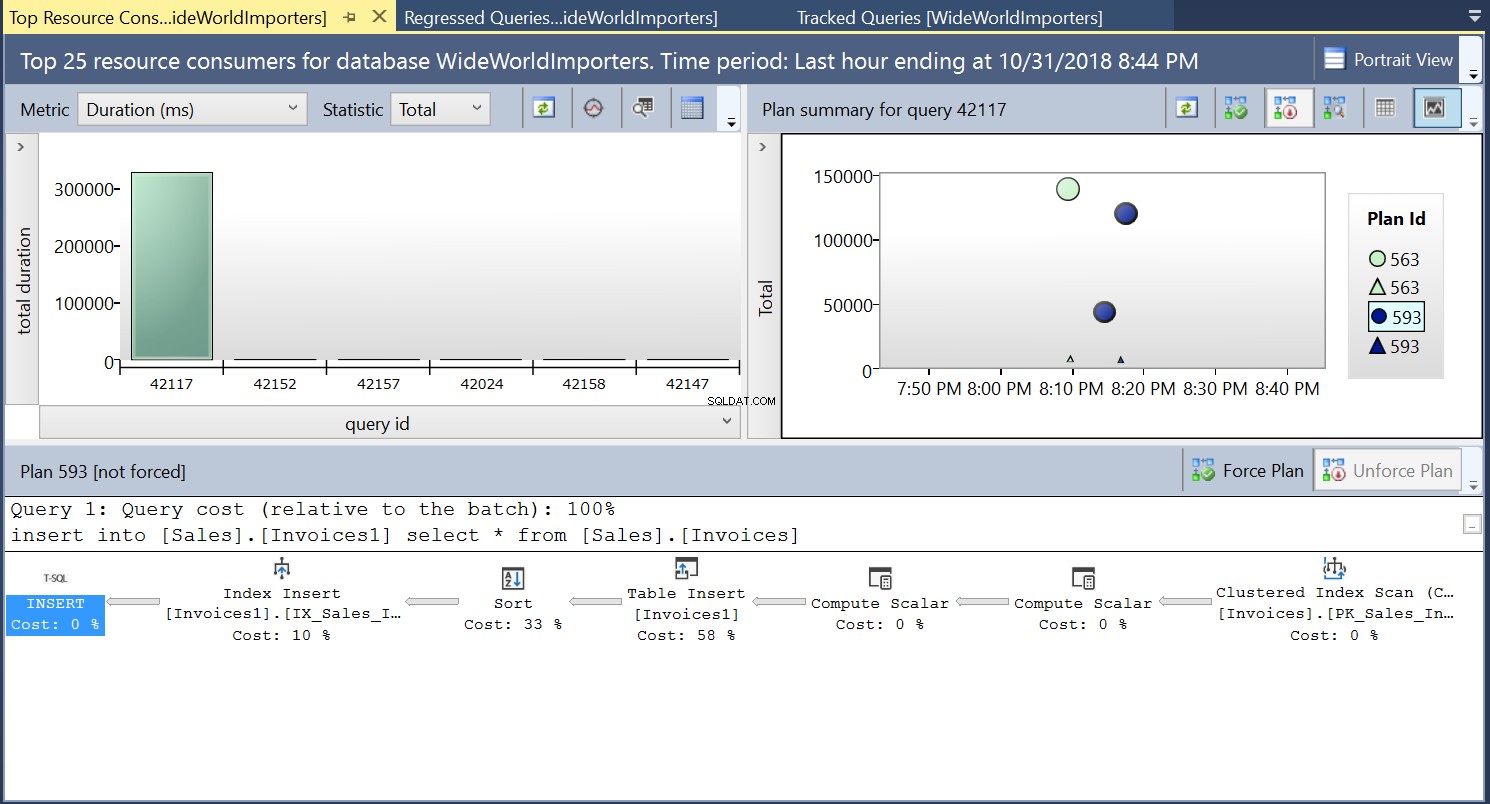
Fig. 4 Udførelsesplan 593
Ser dybere
Vi kan undersøge detaljerne i begge planer og se, hvordan disse nye faktorer eskalerer udførelsestiden for erklæringen. Plan 593 tilføjer yderligere 300 ms eller deromkring til den gennemsnitlige varighed af erklæringen. Under stor arbejdsbyrde i et produktionsmiljø kan denne forskel være betydelig.
At slå STATISTICS IO til, når der kun udføres insert-sætningen én gang i begge tilfælde - med Index på destinationstabel og uden et indeks på Destination table - viser også, at der arbejdes mere med hensyn til logisk IO, når der indsættes rækker i en tabel med indekser.
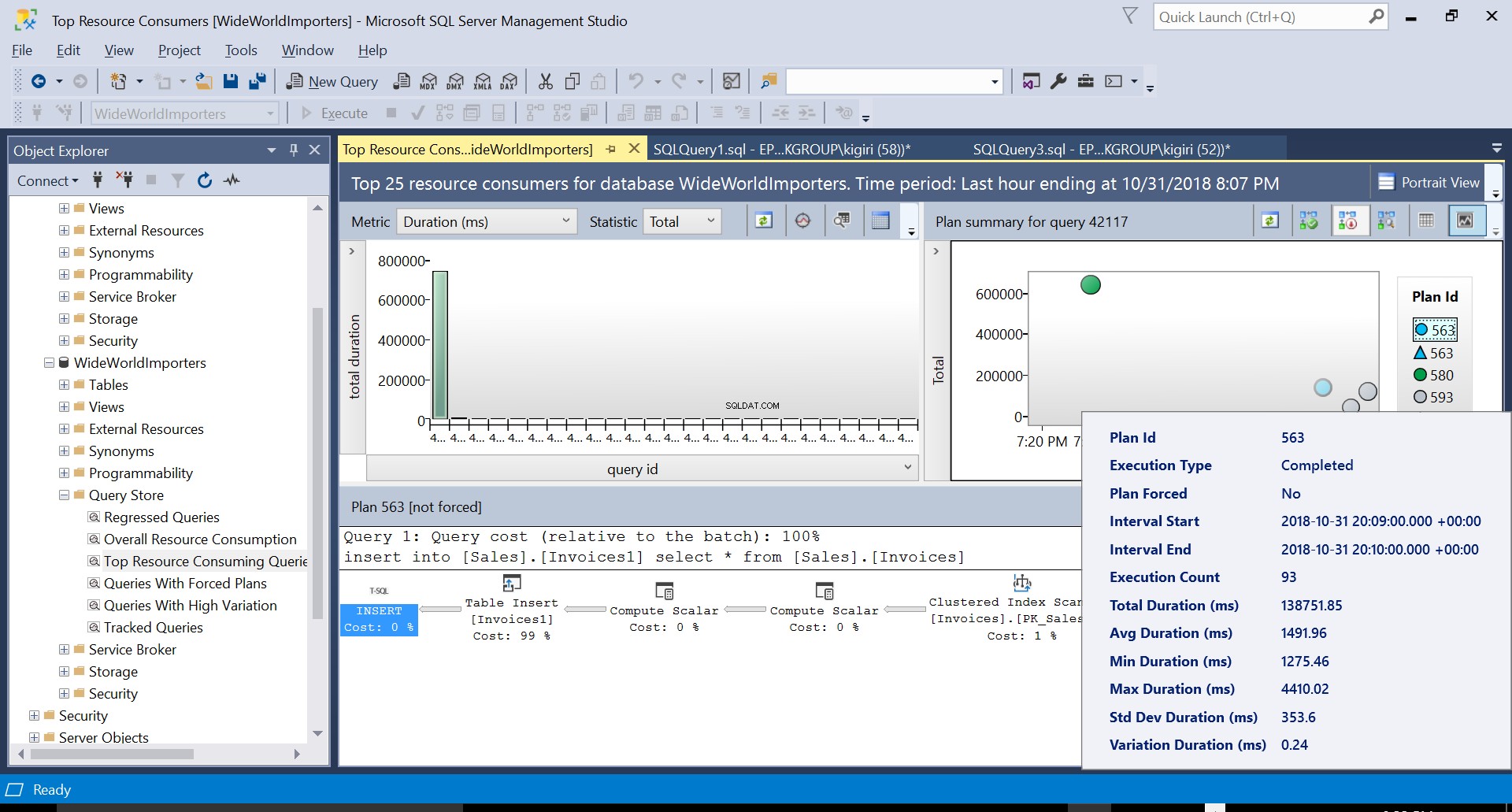
Fig. 5 Detaljer om udførelsesplan 563
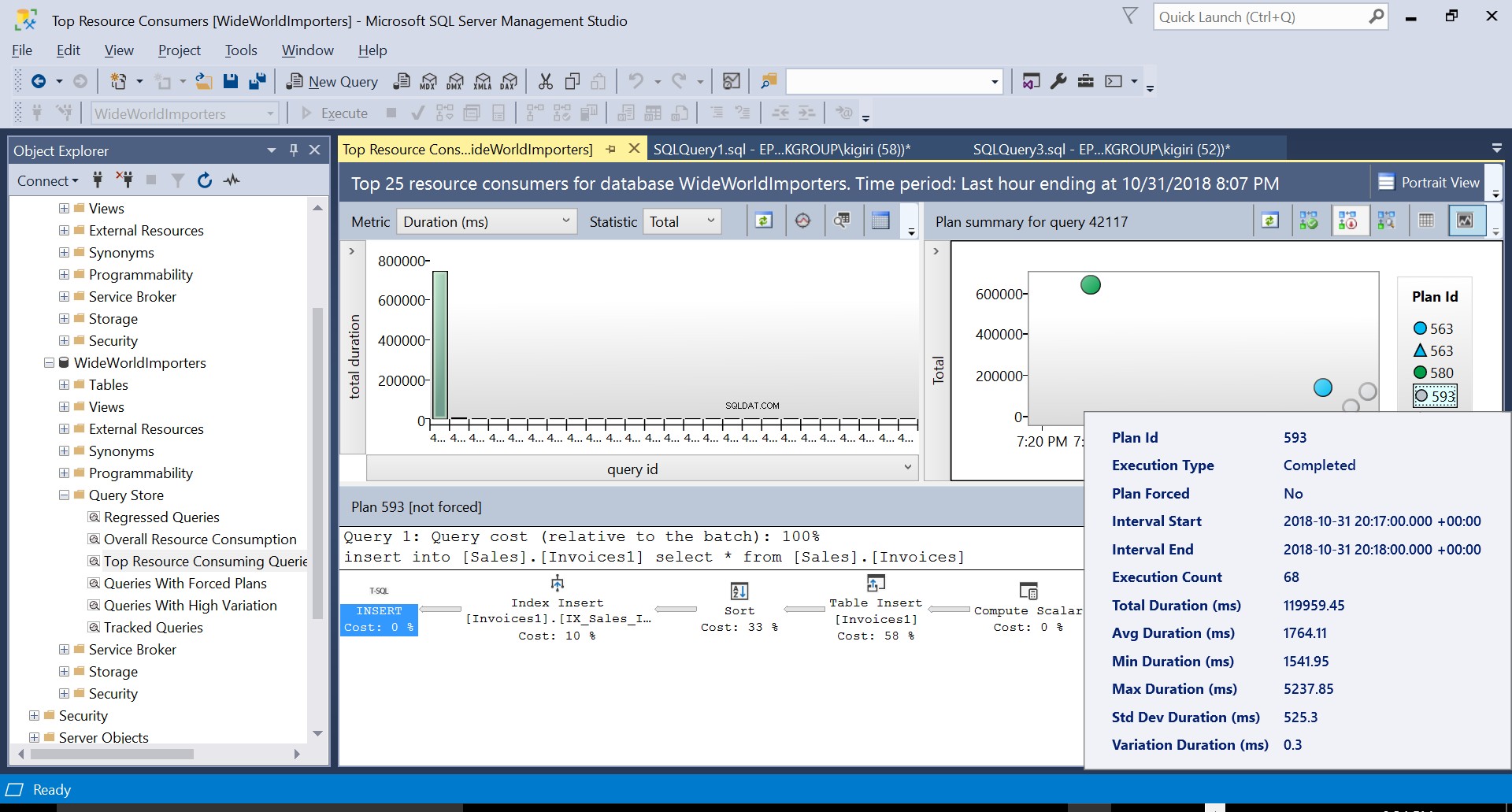
Fig. 4 Detaljer om udførelsesplan 593
Intet indeks:Output med STATISTICS IO slået til:
Tabel 'Fakturaer1'. Scanningsantal 0, logisk læser 78372 , fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Fakturaer'. Scanningsantal 1, logisk læser 11400, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
(70510 rækker påvirket)
Indeks:Output med STATISTICS IO slået til:
Tabel 'Fakturaer1'. Scanningsantal 0, logisk læser 81119 , fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Fakturaer'. Scanningsantal 1, logisk læser 11400 , fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
(70510 rækker påvirket)
Yderligere oplysninger
Microsoft og andre kilder leverer scripts til at undersøge produktionsmiljøet for indekser og identificere sådanne situationer som:
- Redundante indekser – Indekser, der er duplikeret
- Manglende indekser – Indekser, der kunne forbedre ydeevnen baseret på arbejdsbelastning
- Dynge – Tabeller uden grupperede indekser
- Overindekserede tabeller – Tabeller med flere indeks end kolonner
- Indeksbrug – Optælling af søgninger, scanninger og opslag på indekser
Punkt 2, 3 og 5 er mere relateret til præstationspåvirkning med hensyn til læsninger, mens punkt 1 og 4 er relateret til præstationspåvirkning med hensyn til skrivninger. Liste 4 og 5 er to eksempler på disse offentligt tilgængelige forespørgsler.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Konklusion
Vi har vist, ved hjælp af Query Store, at yderligere arbejdsbyrde med et indeks kan introducere i eksekveringsplanen for en eksempelindsættelseserklæring. I produktionen kan overdrevne og redundante indekser have en negativ indvirkning på ydeevnen, især i databaser beregnet til OLTP-arbejdsbelastninger. Det er vigtigt at bruge tilgængelige scripts og værktøjer til at undersøge indekser og afgøre, om de faktisk hjælper eller skader ydeevnen.
Nyttigt værktøj:
dbForge Index Manager – praktisk SSMS-tilføjelse til at analysere status for SQL-indekser og løse problemer med indeksfragmentering.