Jeg er i gang med at rydde op i mit hus (for sent på sommeren til at prøve at udgive det som forårsrengøring). Du ved, at rydde op i skabe, gå gennem børnenes legetøj og organisere kælderen. Det er en smertefuld proces. Da vi flyttede ind i vores hus for 10 år siden, havde vi SÅ meget plads. Nu føler jeg, at der er ting overalt, og det gør det sværere at finde det, jeg virkelig leder efter, og det tager længere og længere tid at rydde op og organisere.
Lyder dette som en database, du administrerer?
Mange kunder, som jeg har arbejdet med, håndterer udrensning af data som en eftertanke. På tidspunktet for implementeringen ønsker alle at gemme alt. "Vi ved aldrig, hvornår vi får brug for det." Efter et år eller to indser nogen, at der er en masse ekstra ting i databasen, men nu er folk bange for at slippe af med det. "Vi er nødt til at tjekke med Legal for at se, om vi kan slette det." Men ingen tjekker med Legal, eller hvis nogen gør det, går Legal tilbage til virksomhedsejerne for at spørge, hvad de skal beholde, og så går projektet i stå. "Vi kan ikke nå til enighed om, hvad der kan slettes." Projektet er glemt, og så to eller fire år hen ad vejen er databasen pludselig en terabyte, svær at administrere, og folk skyder skylden på alle præstationsproblemer på databasestørrelsen. Du hører ordene "partitionering" og "arkivdatabase" kastet rundt, og nogle gange kommer du bare til at slette en masse data, som har sine egne problemer.
Ideelt set bør du beslutte dig for din rensestrategi før implementering eller inden for de første seks til tolv måneder efter start. Men da vi er forbi det stadie, lad os se på, hvilken indflydelse disse ekstra data kan have.
Testmetode
For at sætte scenen tog jeg en kopi af Credit-databasen og gendannede den til min SQL Server 2012-instans. Jeg droppede de tre eksisterende ikke-klyngede indekser og tilføjede to af mine egne:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Jeg øgede derefter antallet af rækker i tabellen til 14,4 millioner ved at genindsætte det originale sæt rækker flere gange, og ændre datoerne lidt:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Til sidst satte jeg en testsele op til at udføre en række sætninger mod databasen fire gange hver. Udsagnene er nedenfor:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Før hver erklæring, jeg udførte
DBCC DROPCLEANBUFFERS; GO
for at rydde bufferpuljen. Dette er naturligvis ikke noget, der skal udføres mod et produktionsmiljø. Jeg gjorde det her for at give et konsekvent udgangspunkt for hver test.
Efter hver udførelse øgede jeg størrelsen på dbo.charge-tabellen ved at indsætte de 14,4 millioner rækker, jeg startede med, men jeg øgede charge_dt med et år for hver udførelse. For eksempel:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Efter tilføjelsen af 14,4 millioner rækker kørte jeg testselen igen. Jeg gentog dette seks gange og tilføjede i det væsentlige seks "års" data. Tabellen dbo.charge startede med data fra 1999, og efter de gentagne indsættelser indeholdt data til og med 2005.
Resultater
Resultaterne fra henrettelserne kan ses her:
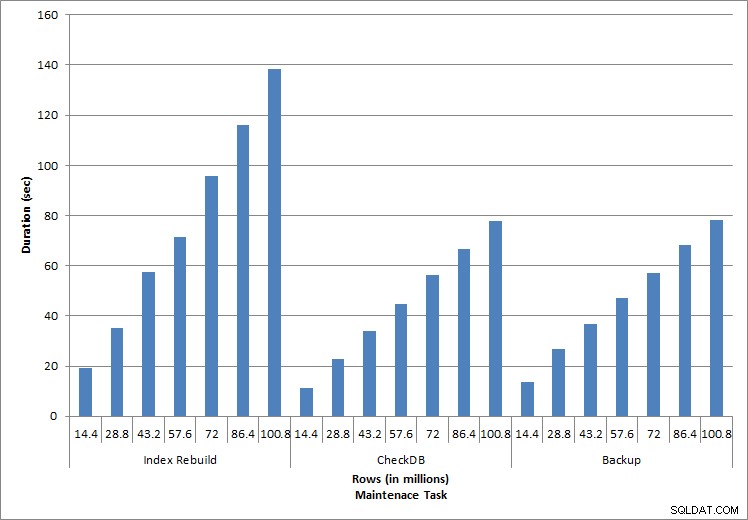
Varighed for vedligeholdelsesopgaver
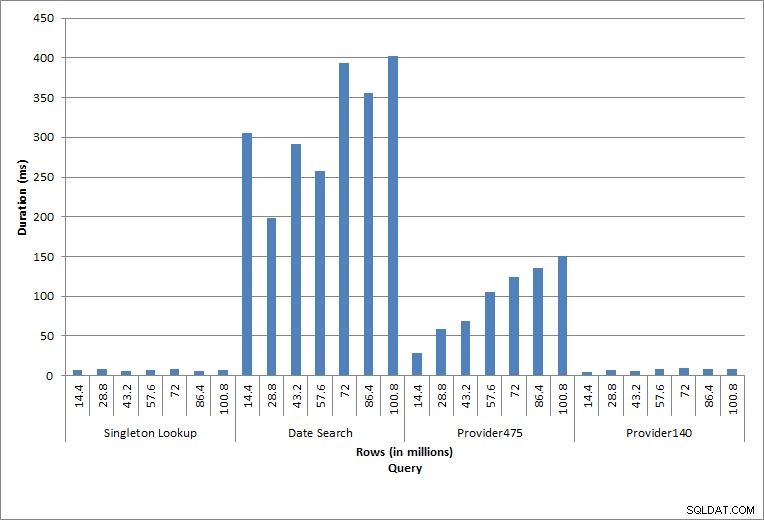
Varighed for forespørgsler
De enkelte udsagn, der udføres, afspejler typisk databaseaktivitet. Genopbygning af indeks, integritetstjek og sikkerhedskopiering er en del af regelmæssig databasevedligeholdelse. Forespørgslerne mod debiteringstabellen repræsenterer et enkeltopslag samt tre variationer af rækkeviddescanninger, der er specifikke for dataene i tabellen.
Indeksgenopbygninger, CHECKDB og sikkerhedskopier
Som forventet for vedligeholdelsesopgaverne steg varighed og IO-værdier, efterhånden som flere rækker blev tilføjet til databasen. Databasestørrelsen steg med en faktor 10, og mens varighederne ikke steg med samme hastighed, sås en konsekvent stigning. Hver vedligeholdelsesopgave tog oprindeligt mindre end 20 sekunder at fuldføre, men efterhånden som flere rækker blev tilføjet, steg varigheden af opgaverne til næsten 1 minut og 20 sekunder for 100 millioner rækker (og til over 2 minutter for indeksgenopbygningen). Dette afspejler den ekstra tid, SQL Server krævede for at fuldføre opgaven på grund af yderligere data.
Singleton Lookup
Forespørgslen mod dbo.charge for en specifik charge_no producerede altid én række – og ville have produceret én række uanset den anvendte værdi, da charge_no er en unik identitet. Der er minimal variation for dette opslag. Da rækker løbende tilføjes til tabellen, kan indekset øges i dybden med et eller to niveauer (mere, efterhånden som tabellen bliver bredere), og derfor tilføjes et par IO'er, men dette er et singleton-opslag med meget få IO'er.
Rækkeviddescanninger
Forespørgslen for et datointerval (charge_dt) blev ændret efter hver indsættelse for at søge i det seneste års data for juli (f.eks. '2005-07-01' til '2005-07-01' for det sidste sæt af tests), men returnerede lidt over 1,2 millioner rækker hver gang. I et scenarie i den virkelige verden ville vi ikke forvente, at det samme antal rækker returneres for den samme måned, år for år, og vi ville heller ikke forvente, at det samme antal rækker returneres for hver måned i et år. Men rækkeantallet kan forblive inden for det samme interval mellem måneder, med små stigninger over tid. Der er udsving i varigheden for denne forespørgsel, men en gennemgang af IO-dataene, der er hentet fra sys.dm_io_virtual_file_stats, viser ensartethed i antallet af læsninger.
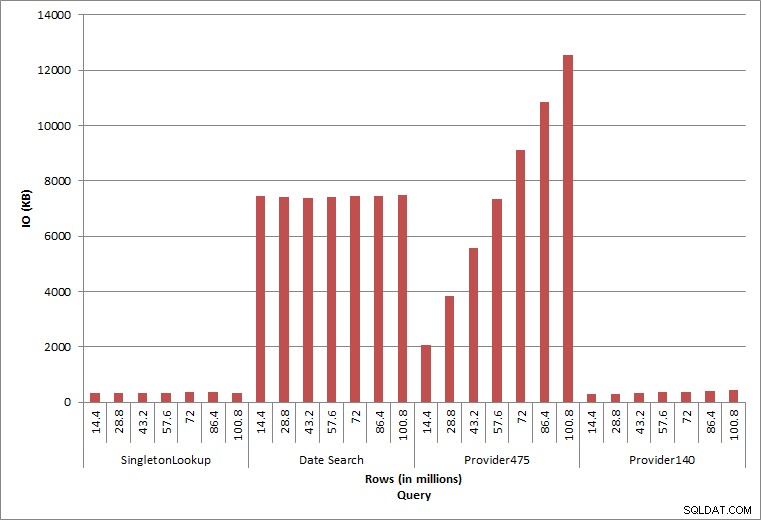
Forespørgsel IO
De sidste to forespørgsler, for to forskellige provider_no-værdier, viser den sande effekt af at opbevare data. I den indledende dbo.charge-tabel havde provider_no 475 over 126.000 rækker og provider_no 140 havde over 1700 rækker. For hver 14,4 millioner rækker, der blev tilføjet, blev der tilføjet omtrent det samme antal rækker for hver provider_no. I et produktionsmiljø er denne type datadistribution ikke ualmindelig, og forespørgsler efter disse data kan fungere godt i de første år af løsningen, men kan forringes over tid, efterhånden som flere rækker tilføjes. Forespørgselsvarigheden øges med en faktor på fem (fra 31 ms til 153 ms) mellem den indledende og endelige udførelse for provider_nr. 475. Selvom denne påvirkning måske ikke virker signifikant, skal du bemærke den parallelle stigning i IO (ovenfor). Hvis dette var en forespørgsel, der blev udført med høj frekvens, og/eller der var lignende forespørgsler, der blev udført med almindelig frekvens, kan den ekstra belastning tilføjes og påvirke det samlede ressourceforbrug. Overvej desuden virkningen, når du arbejder med tabeller, der har milliarder af rækker, og som bruges i forespørgsler med komplekse joinforbindelser, og indvirkningen på dine almindelige – og ekstremt kritiske – vedligeholdelsesopgaver. Tag endelig højde for inddrivelsestid. Din disaster recovery plan bør være baseret på gendannelsestider, og efterhånden som databasestørrelsen vokser, vil databasen tage længere tid at gendanne i sin helhed. Hvis du ikke regelmæssigt tester og timer dine gendannelser, kan det tage længere tid at komme dig efter en katastrofe, end du troede.
Oversigt
Eksemplerne vist her er enkle illustrationer af, hvad der kan ske, når en dataarkiveringsstrategi ikke bestemmes under databaseimplementering, og der er mange andre scenarier at udforske og teste. Gamle data, som man sjældent eller aldrig får adgang til, påvirker mere end blot plads på disken. Det kan påvirke forespørgselsydeevne og varighed af vedligeholdelsesopgaver. Som en DBA, der administrerer flere databaser på en instans, kan én database, der indeholder historiske data, påvirke ydeevnen og vedligeholdelsesopgaverne for andre databaser. Ydermere, hvis rapporter udføres i forhold til historiske data, kan dette skabe kaos i et allerede travlt OLTP-miljø.
Fra begyndelsen er det afgørende, at levetiden for data i en database bestemmes, og en handlingsplan er på plads. For nogle løsninger er det nødvendigt at opbevare alle data for evigt. I dette tilfælde skal du bruge strategier til at holde databasestørrelsen håndterbar, for eksempel:arkiver dataene til en separat tabel eller en separat database med jævne mellemrum. I tilfælde af, at data ikke skal opbevares i årevis, skal du implementere en udrensningsstrategi, der fjerner data på regelmæssig basis. På denne måde kan du smide det legetøj ud, der ikke længere bliver leget med, tøj, der ikke længere passer, og tilfældigt skrammel, som du bare ikke bruger hver tredje måned … i stedet for en gang hvert 10. år.