Denne artikel er den femte del i en serie om T-SQL-fejl, faldgruber og bedste praksis. Tidligere dækkede jeg determinisme, underforespørgsler, joinforbindelser og vinduesdannelse. Denne måned dækker jeg pivotering og unpivoting. Tak Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man og Paul White for at dele dine forslag!
I mine eksempler vil jeg bruge en prøvedatabase kaldet TSQLV5. Du kan finde scriptet, der opretter og udfylder denne database her, og dets ER-diagram her.
Implicit gruppering med PIVOT
Når folk ønsker at pivotere data ved hjælp af T-SQL, bruger de enten en standardløsning med en grupperet forespørgsel og CASE-udtryk eller den proprietære PIVOT-tabeloperator. Den største fordel ved PIVOT-operatøren er, at den har en tendens til at resultere i kortere kode. Denne operatør har dog et par mangler, blandt dem en iboende designfælde, der kan resultere i fejl i din kode. Her vil jeg beskrive fælden, den potentielle fejl og en bedste praksis, der forhindrer fejlen. Jeg vil også beskrive et forslag til at forbedre PIVOT-operatørens syntaks på en måde, der hjælper med at undgå fejlen.
Når du pivoterer data, er der tre trin, der er involveret i løsningen, med tre tilknyttede elementer:
- Gruppe baseret på et gruppering/på rækker-element
- Spredning baseret på et spreading/on cols-element
- Aggregér baseret på et aggregerings-/dataelement
Følgende er syntaksen for PIVOT-operatoren:
VÆLGFRA PIVOT( ( ) FOR IN( ) ) AS ;
Designet af PIVOT-operatøren kræver, at du eksplicit specificerer aggregerings- og spredningselementerne, men lader SQL Server implicit finde ud af grupperingselementet ved eliminering. Uanset hvilke kolonner der vises i kildetabellen, der er angivet som input til PIVOT-operatøren, bliver de implicit grupperingselementet.
Antag for eksempel, at du vil forespørge i Sales.Orders-tabellen i TSQLV5-eksempeldatabasen. Du vil returnere afsender-id'er på rækker, afsendte år på kolonner og antallet af ordrer pr. afsender og år som aggregatet.
Mange mennesker har svært ved at finde ud af PIVOT-operatørens syntaks, og det resulterer ofte i gruppering af data efter uønskede elementer. Som et eksempel med vores opgave, antag, at du ikke er klar over, at grupperingselementet er bestemt implicit, og du kommer med følgende forespørgsel:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shipped year IN([2017] , [2018], [2019]) ) AS P;
Der er kun tre afsendere til stede i dataene med afsender-id'er 1, 2 og 3. Så du forventer kun at se tre rækker i resultatet. Det faktiske forespørgselsoutput viser dog mange flere rækker:
shipperid 2017 2018 2019-------------------------------------------------------------- -3 1 0 01 1 0 02 1 0 01 1 0 02 1 0 02 1 0 02 1 0 03 1 0 02 1 0 03 1 0 0...3 0 1 03 0 1 03 0 1 01 0 1 01 0 1 03 0 1 03 0 1 03 0 1 01 0 1 0...3 0 0 11 0 0 12 0 0 11 0 0 12 0 0 11 0 0 13 0 0 13 0 0 12 0 1 0...(830 rækker påvirket)
Hvad skete der?
Du kan finde en ledetråd, der vil hjælpe dig med at finde ud af fejlen i koden ved at se på forespørgselsplanen vist i figur 1.
 Figur 1:Plan for pivotforespørgsel med implicit gruppering
Figur 1:Plan for pivotforespørgsel med implicit gruppering
Lad ikke brugen af CROSS APPLY operatoren med VALUES-sætningen i forespørgslen forvirre dig. Dette gøres ganske enkelt for at beregne resultatkolonnen afsendt år baseret på kildekolonnen afsendt dato og håndteres af den første Compute Scalar-operatør i planen.
Inputtabellen til PIVOT-operatøren indeholder alle kolonner fra Sales.Orders-tabellen plus resultatkolonnen forsendelsesår. Som nævnt bestemmer SQL Server grupperingselementet implicit ved eliminering baseret på, hvad du ikke har angivet som aggregerings- (shippeddate) og spreading (shippedyear) elementer. Måske forventede du intuitivt, at shipperid-kolonnen skulle være grupperingskolonnen, fordi den optræder i SELECT-listen, men som du kan se i planen, fik du i praksis en meget længere liste af kolonner, inklusive orderid, som er den primære nøglekolonne i kildetabellen. Dette betyder, at du i stedet for at få en række pr. afsender, får en række pr. ordre. Da du i SELECT-listen kun har angivet kolonnerne shipperid, [2017], [2018] og [2019], kan du ikke se resten, hvilket øger forvirringen. Men resten deltog i den underforståede gruppering.
Det, der kunne være godt, er, hvis syntaksen for PIVOT-operatøren understøttede en klausul, hvor du eksplicit kan angive elementet gruppering/på rækker. Noget som dette:
VÆLGFRA PIVOT( ( ) FOR IN( ) ON ROWS ) AS ;
Baseret på denne syntaks vil du bruge følgende kode til at håndtere vores opgave:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shipped year IN([2017] , [2018], [2019]) ON ROWS shipperid ) SOM P;
Du kan finde et feedbackelement med et forslag til at forbedre PIVOT-operatørens syntaks her. For at gøre denne forbedring til en ubrudt ændring, kan denne klausul gøres valgfri, hvor standarden er den eksisterende adfærd. Der er andre forslag til at forbedre PIVOT-operatørens syntaks ved at gøre den mere dynamisk og ved at understøtte flere aggregater.
I mellemtiden er der en bedste praksis, der kan hjælpe dig med at undgå fejlen. Brug et tabeludtryk såsom en CTE eller en afledt tabel, hvor du kun projicerer de tre elementer, som du skal være involveret i pivotoperationen, og brug derefter tabeludtrykket som input til PIVOT-operatoren. På denne måde har du fuld kontrol over grupperingselementet. Her er den generelle syntaks efter denne bedste praksis:
MEDAS( SELECT , , FRA )SELECT FRA PIVOT( ( ) FOR IN( ) ) AS ;
Anvendt på vores opgave bruger du følgende kode:
WITH C AS( SELECT shipperid, YEAR(shippeddate) AS shipped year, shippeddate FROM Sales.Orders)SELECT shipperid, [2017], [2018], [2019]FROM C PIVOT( COUNT(shippeddate) FOR shipped year IN([ 2017], [2018], [2019]) ) AS P;
Denne gang får du kun tre resultatrækker som forventet:
shipperid 2017 2018 2019-------------------------------------------------------------- -3 51 125 731 36 130 792 56 143 116
En anden mulighed er at bruge den gamle og klassiske standardløsning til pivotering ved hjælp af en grupperet forespørgsel og CASE-udtryk, som sådan:
SELECT shipperid, COUNT(CASE WHEN shippedyear =2017 THEN END END) AS [2017], COUNT(CASE WHEN shipped year =2018 THEN END END) AS [2018], COUNT(CASE WHEN shipped year =2019 THEN END) [2019]FRA Salg. Ordrer KRYDS GÆLDER( VALUES(YEAR(shippeddate)) ) AS D(shipped year)HERE afsendelsesdato IKKE ER NULLGROUP BY shipperid;
Med denne syntaks skal alle tre pivoteringstrin og deres tilknyttede elementer være eksplicitte i koden. Men når du har et stort antal spredningsværdier, har denne syntaks en tendens til at være udførlig. I sådanne tilfælde foretrækker folk ofte at bruge PIVOT-operatøren.
Implicit fjernelse af NULLs med UNPIVOT
Det næste punkt i denne artikel er mere en faldgrube end en fejl. Det har at gøre med den proprietære T-SQL UNPIVOT-operator, som lader dig frigøre data fra en kolonnetilstand til en tilstand af rækker.
Jeg bruger en tabel kaldet CustOrders som mine eksempeldata. Brug følgende kode til at oprette, udfylde og forespørge om denne tabel for at vise dens indhold:
DROP TABEL HVIS FINDER dbo.CustOrders;GO WITH C AS( SELECT custid, YEAR(orderdate) AS orderyearyear, val FROM Sales.OrderValues)SELECT custid, [2017], [2018], [2019]INTO dbo.CustOrdersFROM C PIVOT( SUM(værdi) FOR ordreårår IN([2017], [2018], [2019]) ) AS P; VÆLG * FRA dbo.CustOrders;
Denne kode genererer følgende output:
custid 2017 2018 2019------- ---------- ---------- ----------1 NULL 2022.50 2250.502 88.80 799.75 514.403 403.20 5960.78 660.004 1379.00 6406.90 5604.755 4324.40 13849.02 6754.166 NULL 1079.80 2160.007 9986.20 7817.88 730.008 982.00 3026.85 224.009 4074.28 11208.36 6680.6110 1832.80 7630.25 11338.5611 479.40 3179.50 2431.0012 NULL 238.00 1576.8013 100.80 NULL NULL14 1674.22 6516.40 4158.2615 2169.00 1128.00 513.7516 NULL 787.60 931.5017 533.60 420.00 2809.6118 268.80 487.00 860.1019 950.00 4514.35 9296.6920 15568.07 48096.27 41210.65...
Denne tabel indeholder de samlede ordreværdier pr. kunde og år. NULL repræsenterer tilfælde, hvor en kunde ikke havde nogen ordreaktivitet i målåret.
Antag, at du vil fjerne pivoteringen af dataene fra CustOrders-tabellen, returnere en række pr. kunde og år, med en resultatkolonne kaldet val, der indeholder den samlede ordreværdi for den aktuelle kunde og år. Enhver ikke-pivoterende opgave involverer generelt tre elementer:
- Navnene på de eksisterende kildekolonner, som du deaktiverer:[2017], [2018], [2019] i vores tilfælde
- Et navn, du tildeler den målkolonne, der skal indeholde kildekolonnenavnene:ordreår i vores tilfælde
- Et navn, du tildeler målkolonnen, der skal indeholde kildekolonneværdierne:val i vores tilfælde
Hvis du beslutter dig for at bruge UNPIVOT-operatoren til at håndtere unpivoting-opgaven, skal du først finde ud af de tre ovenstående elementer og derefter bruge følgende syntaks:
VÆLG, , FRA UNPIVOT( FOR IN( ) ) AS ;
Anvendt på vores opgave bruger du følgende forespørgsel:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Denne forespørgsel genererer følgende output:
bestilte ordreår val------- ---------- ----------1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 3020170 3020170 3020170 603.602 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00 ...
Når du ser på kildedataene og forespørgselsresultatet, bemærker du, hvad der mangler?
Designet af UNPIVOT-operatoren involverer en implicit eliminering af resultatrækker, der har en NULL i værdikolonnen - val i vores tilfælde. Når du ser på udførelsesplanen for denne forespørgsel vist i figur 2, kan du se filteroperatoren fjerne rækkerne med NULL'erne i val-kolonnen (Udtr1007 i planen).
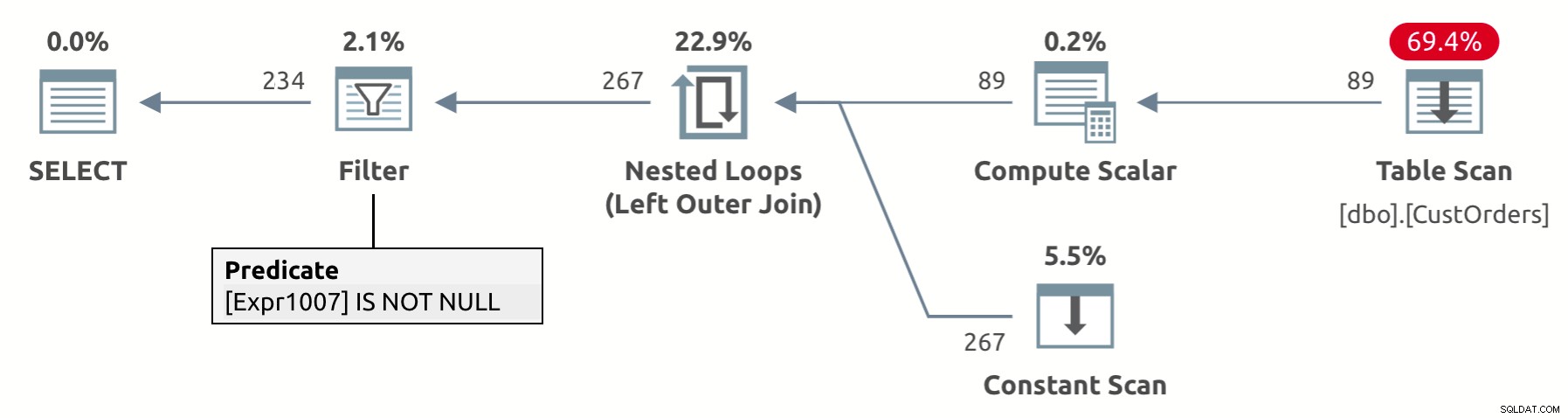 Figur 2:Plan for unpivot-forespørgsel med implicit fjernelse af NULL'er
Figur 2:Plan for unpivot-forespørgsel med implicit fjernelse af NULL'er
Nogle gange er denne adfærd ønskværdig, i hvilket tilfælde du ikke behøver at gøre noget særligt. Problemet er, at nogle gange vil du beholde rækkerne med NULL'erne. Faldgruben er, når du vil beholde NULL'erne, og du ikke engang er klar over, at UNPIVOT-operatøren er designet til at fjerne dem.
Det, der kunne være godt, er, hvis UNPIVOT-operatøren havde en valgfri klausul, der tillod dig at angive, om du vil fjerne eller beholde NULL'er, hvor førstnævnte er standard for bagudkompatibilitet. Her er et eksempel på, hvordan denne syntaks kan se ud:
VÆLG, , FRA UNPIVOT( FOR IN( ) [FJERN NULLER | BEHOLD NULLER] ) SOM ;
Hvis du ville beholde NULL'er, ville du baseret på denne syntaks bruge følgende forespørgsel:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;
Du kan finde et feedbackelement med et forslag til at forbedre UNPIVOT-operatørens syntaks på denne måde her.
I mellemtiden, hvis du vil beholde rækkerne med NULL'erne, skal du finde på en løsning. Hvis du insisterer på at bruge UNPIVOT-operatøren, skal du anvende to trin. I det første trin definerer du et tabeludtryk baseret på en forespørgsel, der bruger ISNULL- eller COALESCE-funktionen til at erstatte NULL'er i alle ikke-pivoterede kolonner med en værdi, der normalt ikke kan vises i dataene, f.eks. -1 i vores tilfælde. I det andet trin bruger du NULLIF-funktionen i den ydre forespørgsel mod værdiskolonnen for at erstatte -1 tilbage med en NULL. Her er den komplette løsningskode:
WITH C AS( SELECT custid, ISNULL([2017], -1.0) AS [2017], ISNULL([2018], -1.0) AS [2018], ISNULL([2019], -1.0) AS [2019 ] FROM dbo.CustOrders)SELECT custid, orderyear, NULLIF(val, -1.0) AS valFROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Her er outputtet af denne forespørgsel, der viser, at rækker med NULL'er i valkolonnen bevares:
custid orderyear val------- ---------- ----------1 2017 NULL1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.1703 360.403 390.503 402 8250. 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2017 NULL6 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00Denne tilgang er akavet, især når du har et stort antal kolonner, der skal frigøres.
En alternativ løsning bruger en kombination af APPLY-operatoren og VALUES-udtrykket. Du konstruerer en række for hver ikke-pivoterede kolonne, hvor en kolonne repræsenterer kolonnen med målnavne (ordreår i vores tilfælde), og en anden repræsenterer kolonnen med målværdier (værdi i vores tilfælde). Du angiver det konstante år for kolonnen navne og den relevante korrelerede kildekolonne for kolonnen værdier. Her er den komplette løsningskode:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val);Det gode her er, at medmindre du er interesseret i at fjerne rækkerne med NULL'erne i valkolonnen, behøver du ikke at gøre noget særligt. Der er ikke noget implicit trin her, der fjerner rækkerne med NULLS. Desuden, da val-kolonnen alias er oprettet som en del af FROM-sætningen, er den tilgængelig for WHERE-sætningen. Så hvis du er interesseret i at fjerne NULL'erne, kan du være eksplicit om det i WHERE-sætningen ved direkte at interagere med værdikolonnens alias, som sådan:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) SOM A(ordre year, val)WHERE val IS IKKE NULL;Pointen er, at denne syntaks giver dig kontrol over, om du vil beholde eller fjerne NULL'er. Det er mere fleksibelt end UNPIVOT-operatøren på en anden måde, så du kan håndtere flere ikke-pivoterede mål, såsom både værdi og antal. Mit fokus i denne artikel var dog faldgruben, der involverede NULL'er, så jeg kom ikke ind på dette aspekt.
Konklusion
Designet af PIVOT- og UNPIVOT-operatørerne fører nogle gange til fejl og faldgruber i din kode. PIVOT-operatørens syntaks tillader dig ikke eksplicit at angive grupperingselementet. Hvis du ikke er klar over dette, kan du ende med uønskede grupperingselementer. Som en bedste praksis anbefales det, at du bruger et tabeludtryk som input til PIVOT-operatoren, og dette er grunden til eksplicit at kontrollere, hvad der er grupperingselementet.
UNPIVOT-operatorens syntaks lader dig ikke kontrollere, om rækker med NULL skal fjernes eller beholdes i resultatværdikolonnen. Som en løsning bruger du enten en akavet løsning med funktionerne ISNULL og NULLIF eller en løsning baseret på APPLY-operatoren og VALUES-sætningen.
Jeg nævnte også to feedbackpunkter med forslag til forbedring af PIVOT- og UNPIVOT-operatørerne med mere eksplicitte muligheder for at kontrollere operatørens adfærd og dens elementer.