Gæsteforfatter:Michael J Swart (@MJSwart)
Jeg bruger meget tid på at omsætte softwarekrav til skemaer og forespørgsler. Disse krav er nogle gange nemme at implementere, men er ofte vanskelige. Jeg vil gerne tale om UI-designvalg, der fører til dataadgangsmønstre, som er besværlige at implementere ved hjælp af SQL Server.
Sortér efter kolonne
Sort-By-Column er så velkendt et mønster, at vi kan tage det for givet. Hver gang vi interagerer med software, der viser en tabel, kan vi forvente, at kolonnerne kan sorteres på denne måde:
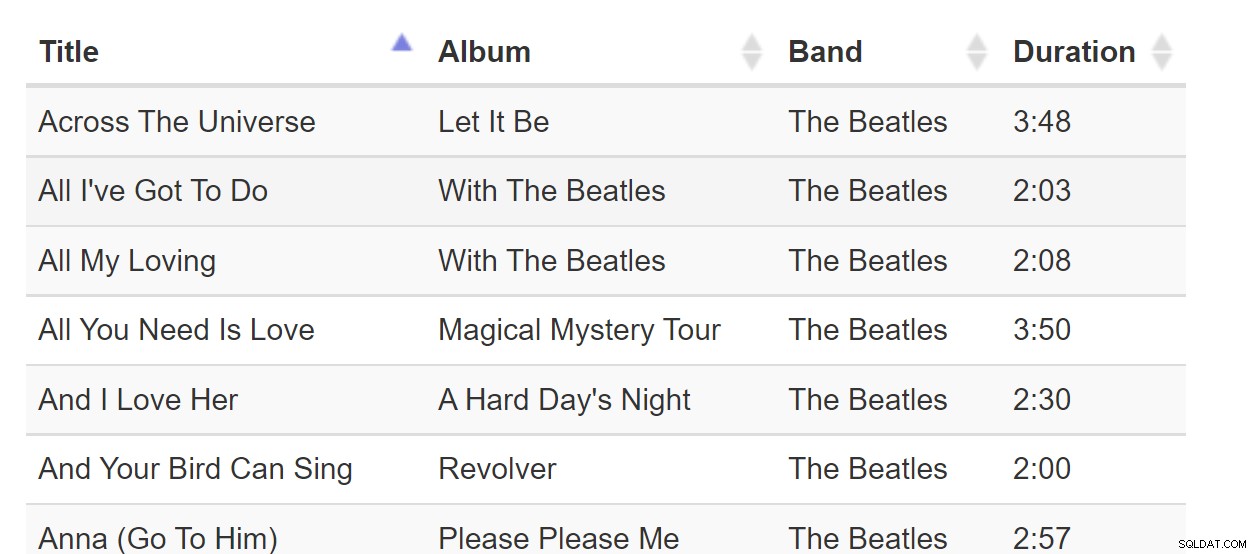
Sort-By-Colunn er et godt mønster, når alle data kan passe i browseren. Men hvis datasættet er milliarder af rækker stort, kan dette blive akavet, selvom websiden kun kræver én side med data. Overvej denne tabel med sange:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); Og overvej disse fire forespørgsler sorteret efter hver kolonne:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
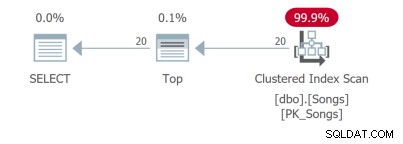
Selv for en forespørgsel, der er så enkel, er der forskellige forespørgselsplaner. De første to forespørgsler bruger dækkende indekser:
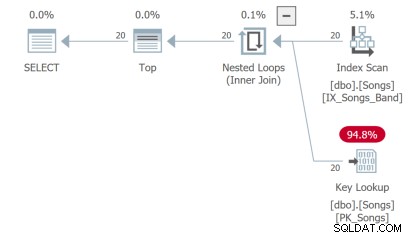
Den tredje forespørgsel skal lave et nøgleopslag, som ikke er ideelt:
Men det værste er den fjerde forespørgsel, som skal scanne hele tabellen og udføre en sortering for at returnere de første 20 rækker:
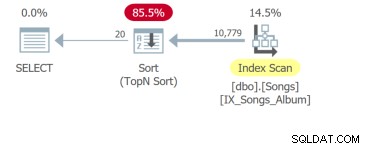
Pointen er, at selvom den eneste forskel er ORDER BY-klausulen, skal disse forespørgsler analyseres separat. Den grundlæggende enhed for SQL-tuning er forespørgslen. Så hvis du viser mig UI-krav med ti sorterbare kolonner, viser jeg dig ti forespørgsler, der skal analyseres.
Hvornår bliver det akavet?
Sort-By-Column-funktionen er et fantastisk UI-mønster, men det kan blive akavet, hvis dataene kommer fra en enorm voksende tabel med mange, mange kolonner. Det kan være fristende at oprette dækkende indekser på hver kolonne, men det har andre afvejninger. Columnstore-indekser kan hjælpe under nogle omstændigheder, men det introducerer endnu et niveau af akavet. Der er ikke altid et let alternativ.
Pagede resultater
Brug af side-resultater er en god måde at ikke overvælde brugeren med for meget information på én gang. Det er også en god måde at ikke overvælde databaseserverne ... normalt.
Overvej dette design:

Dataene bag dette eksempel kræver optælling og behandling af hele datasættet for at rapportere antallet af resultater. Forespørgslen til dette eksempel kan bruge syntaks som denne:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Det er praktisk syntaks, og forespørgslen producerer kun 25 rækker. Men bare fordi resultatsættet er lille, betyder det ikke nødvendigvis, at det er billigt. Ligesom vi så med Sort-By-Column-mønsteret, er en TOP-operatør kun billig, hvis den ikke behøver at sortere en masse data først.
Asynkrone sideanmodninger
Når en bruger navigerer fra en side med resultater til den næste, kan de involverede webanmodninger adskilles med sekunder eller minutter. Dette fører til problemer, der ligner de faldgruber, der ses, når du bruger NOLOCK. For eksempel:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Når en række tilføjes mellem de to anmodninger, kan brugeren se den samme række to gange. Og hvis en række fjernes, kan brugeren gå glip af en række, når de navigerer på siderne. Dette Paged-Results-mønster svarer til "Giv mig rækker 26-50". Når det rigtige spørgsmål skulle være "Giv mig de næste 25 rækker". Forskellen er subtil.
Bedre mønstre
Med Paged-Results kan "OFFSET @N ROWS" tage længere og længere tid, efterhånden som @N vokser. Overvej i stedet Load-More-knapper eller Infinite-Scrolling. Med Load-More-sidesøgning er der i det mindste en chance for at gøre effektiv brug af et indeks. Forespørgslen ville se nogenlunde sådan ud:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Det lider stadig af nogle af faldgruberne ved asynkrone sideanmodninger, men på grund af bogmærket vil brugeren fortsætte, hvor de slap.
Søger efter tekst efter understreng
Søgning er overalt på internettet. Men hvilken løsning skal bruges på bagenden? Jeg vil advare mod at søge efter en understreng ved hjælp af SQL Servers LIKE-filter med jokertegn som dette:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Det kan føre til akavede resultater som dette:
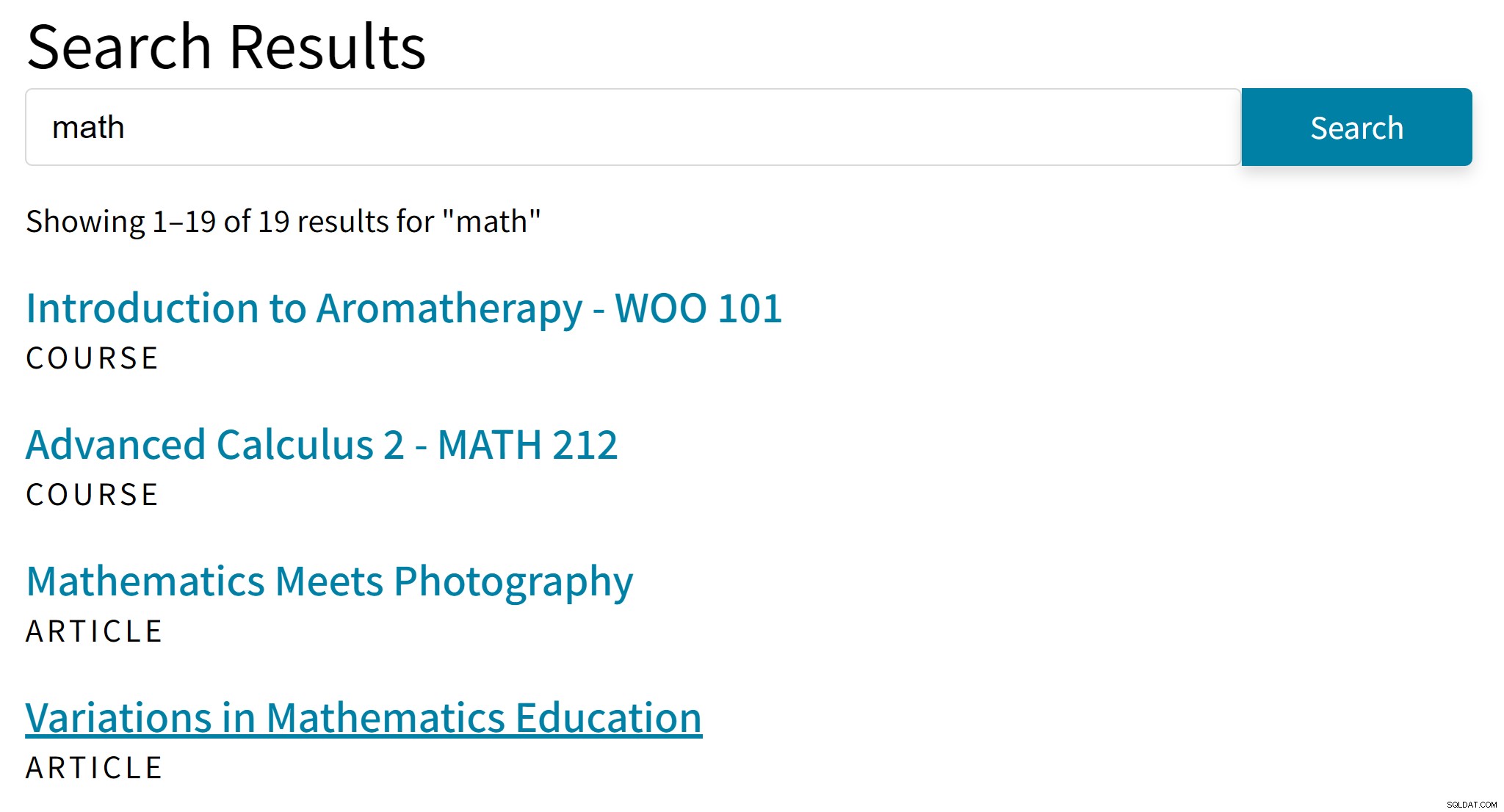
"Aromaterapi" er sandsynligvis ikke et godt hit for søgeordet "matematik". I mellemtiden mangler søgeresultaterne artikler, der kun nævner algebra eller trigonometri.
Det kan også være meget svært at udføre effektivt ved hjælp af SQL Server. Der er ikke noget ligetil indeks, der understøtter denne form for søgning. Paul White gav en vanskelig løsning med Trigram Wildcard String Search i SQL Server. Der er også vanskeligheder, der kan opstå med kollationer og Unicode. Det kan blive en dyr løsning for en knap så god brugeroplevelse.
Hvad skal du bruge i stedet
SQL Servers fuldtekstsøgning ser ud til at kunne hjælpe, men jeg har personligt aldrig brugt det. I praksis har jeg kun set succes i løsninger uden for SQL Server (f.eks. Elasticsearch).
Konklusion
Efter min erfaring har jeg fundet ud af, at softwaredesignere ofte er meget modtagelige for feedback om, at deres design nogle gange vil være besværligt at implementere. Når de ikke er det, har jeg fundet det nyttigt at fremhæve faldgruberne, omkostningerne og leveringstiden. Den slags feedback er nødvendig for at hjælpe med at bygge vedligeholdelsesvenlige, skalerbare løsninger.
Om forfatteren
 Michael J Swart er en passioneret databaseprofessionel og blogger, der fokuserer på databaseudvikling og softwarearkitektur. Han nyder at tale om alt data relateret og bidrage til samfundsprojekter. Michael blogger som "Database Whisperer" på michaeljswart.com.
Michael J Swart er en passioneret databaseprofessionel og blogger, der fokuserer på databaseudvikling og softwarearkitektur. Han nyder at tale om alt data relateret og bidrage til samfundsprojekter. Michael blogger som "Database Whisperer" på michaeljswart.com.