Du tror måske, at databasevedligeholdelse ikke er noget for dig. Men hvis du designer dine modeller proaktivt, får du databaser, der gør livet lettere for dem, der skal vedligeholde dem.
Et godt databasedesign kræver proaktivitet, en velanset kvalitet i ethvert arbejdsmiljø. Hvis du ikke er bekendt med udtrykket, er proaktivitet evnen til at forudse problemer og have løsninger klar, når problemer opstår – eller endnu bedre, planlægge og handle, så problemerne ikke opstår i første omgang.
Arbejdsgivere forstår, at deres ansattes eller entreprenørers proaktivitet er lig med omkostningsbesparelser. Det er derfor, de værdsætter det, og hvorfor de opfordrer folk til at praktisere det.
I din rolle som datamodeller er den bedste måde at demonstrere proaktivitet på at designe modeller, der forudser og undgår problemer, der rutinemæssigt plager databasevedligeholdelse. Eller, i det mindste, som væsentligt forenkler løsningen på disse problemer.
Selvom du ikke er ansvarlig for databasevedligeholdelse, høster modellering til nem databasevedligeholdelse mange fordele. For eksempel forhindrer det dig i at blive ringet op til enhver tid for at løse datanødsituationer, der tager værdifuld tid væk, du kunne bruge på de design- eller modelleringsopgaver, du nyder så meget!
Gør livet lettere for IT-folkene
Når vi designer vores databaser, skal vi tænke ud over leveringen af en DER og genereringen af opdateringsscripts. Når først en database går i produktion, skal vedligeholdelsesingeniører håndtere alle mulige potentielle problemer, og en del af vores opgave som databasemodeller er at minimere chancerne for, at disse problemer opstår.
Lad os starte med at se på, hvad det vil sige at skabe et godt databasedesign, og hvordan denne aktivitet relaterer sig til almindelige databasevedligeholdelsesopgaver.
Hvad er datamodellering?
Datamodellering er opgaven med at skabe en abstrakt, normalt grafisk, repræsentation af et informationslager. Målet med datamodellering er at afsløre egenskaberne for og relationerne mellem de enheder, hvis data er lagret i depotet.
Datamodeller er bygget op omkring behovene for et forretningsproblem. Regler og krav er defineret på forhånd gennem input fra forretningseksperter, så de kan inkorporeres i designet af et nyt datalager eller tilpasses i iterationen af et eksisterende.
Ideelt set er datamodeller levende dokumenter, der udvikler sig med skiftende forretningsbehov. De spiller en vigtig rolle i at understøtte forretningsbeslutninger og i planlægning af systemarkitektur og strategi. Datamodellerne skal holdes synkroniseret med de databaser, de repræsenterer, så de er nyttige i forbindelse med vedligeholdelsesrutinerne for disse databaser.
Almindelige udfordringer med databasevedligeholdelse
Vedligeholdelse af en database kræver konstant overvågning, automatiseret eller på anden måde, for at sikre, at den ikke mister sine dyder. Best practices for databasevedligeholdelse sikrer, at databaser altid beholder deres:
- Informationens integritet og kvalitet
- Ydeevne
- Tilgængelighed
- Skalerbarhed
- Tilpasning til ændringer
- Sporbarhed
- Sikkerhed
Mange datamodelleringstip er tilgængelige for at hjælpe dig med at skabe et godt databasedesign hver gang. Dem, der diskuteres nedenfor, har specifikt til formål at sikre eller lette vedligeholdelsen af de ovennævnte databasekvaliteter.
Integritet og informationskvalitet
Et grundlæggende mål for bedste praksis for databasevedligeholdelse er at sikre, at oplysningerne i databasen bevarer sin integritet. Dette er afgørende for, at brugerne bevarer deres tillid til informationen.
Der er to typer integritet:fysisk integritet og logisk integritet .
Fysisk integritet
Vedligeholdelse af den fysiske integritet af en database sker ved at beskytte informationen mod eksterne faktorer såsom hardware eller strømsvigt. Den mest almindelige og bredt accepterede tilgang er gennem en passende sikkerhedskopieringsstrategi, der tillader gendannelse af en database inden for rimelig tid, hvis en katastrofe ødelægger den.
For DBA'er og serveradministratorer, der administrerer databaselagring, er det nyttigt at vide, om databaser kan opdeles i sektioner med forskellige opdateringsfrekvenser. Dette giver dem mulighed for at optimere lagerbrug og backup-planer.
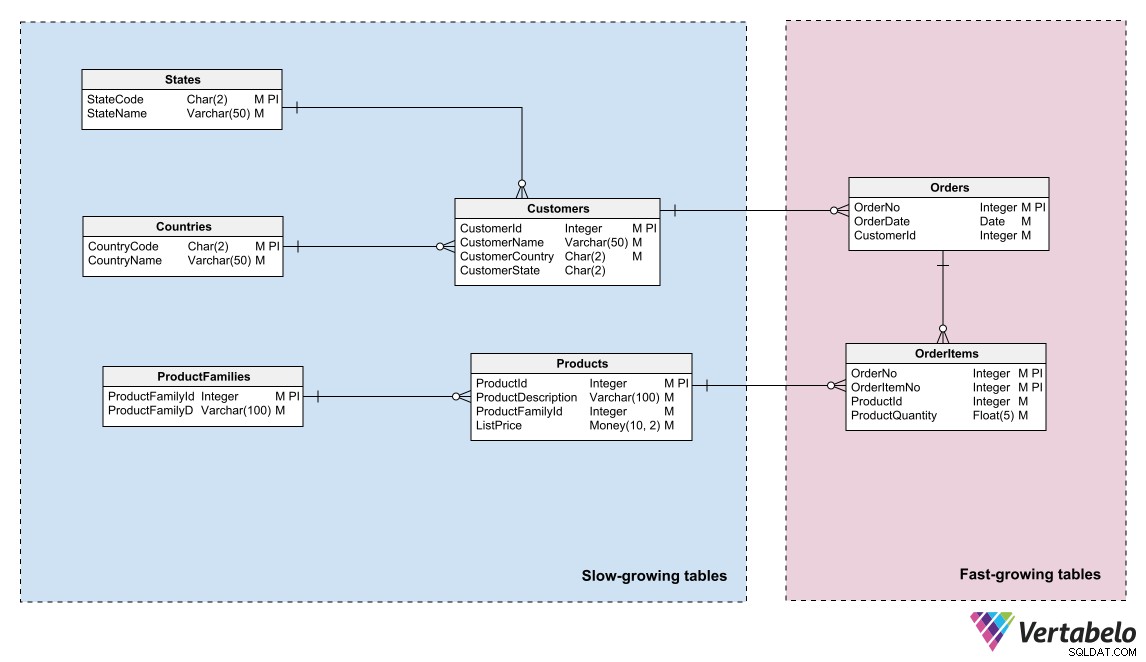
Datamodeller kan afspejle denne opdeling ved at identificere områder med forskellige data "temperaturer" og ved at gruppere enheder i disse områder. "Temperatur" refererer til den hyppighed, hvormed tabeller modtager ny information. Tabeller, der opdateres meget hyppigt, er de "hotteste"; dem, der aldrig eller sjældent opdateres, er de "koldeste."
 Datamodel for et e-handelssystem, der skelner mellem varme, varme og kolde data.
Datamodel for et e-handelssystem, der skelner mellem varme, varme og kolde data. En DBA eller systemadministrator kan bruge denne logiske gruppering til at partitionere databasefilerne og oprette forskellige backup-planer for hver partition.
Logisk integritet
Opretholdelse af den logiske integritet af en database er afgørende for pålideligheden og anvendeligheden af den information, den leverer. Hvis en database mangler logisk integritet, afslører de applikationer, der bruger den, uoverensstemmelser i dataene før eller siden. Stillet over for disse uoverensstemmelser har brugerne mistillid til oplysningerne og leder simpelthen efter mere pålidelige datakilder.
Blandt databasevedligeholdelsesopgaverne er opretholdelse af informationens logiske integritet en udvidelse af databasemodelleringsopgaven, kun at den begynder efter databasen er sat i produktion og fortsætter gennem hele dens levetid. Den mest kritiske del af dette vedligeholdelsesområde er tilpasning til ændringer.
Skiftstyring
Ændringer i forretningsregler eller krav er en konstant trussel mod databasers logiske integritet. Du kan føle dig glad for den datamodel, du har bygget, velvidende, at den er perfekt tilpasset virksomheden, at den svarer med de rigtige oplysninger på enhver forespørgsel, og at den udelader enhver indsættelse, opdatering eller sletning af uregelmæssigheder. Nyd dette øjeblik af tilfredshed, for det er kortvarigt!
Vedligeholdelse af en database indebærer, at man står over for behovet for at foretage ændringer i modellen dagligt. Det tvinger dig til at tilføje nye objekter eller ændre de eksisterende, ændre kardinaliteten af relationerne, omdefinere primærnøgler, ændre datatyper og gøre andre ting, der får os til at ryste.
Ændringer sker hele tiden. Det kan være, at et eller andet krav blev forklaret forkert fra begyndelsen, nye krav er dukket op, eller at du utilsigtet har introduceret en eller anden fejl i din model (vi datamodellere er trods alt kun mennesker).
Dine modeller skal være nemme at modificere, når der opstår behov for ændringer. Det er afgørende at bruge et databasedesignværktøj til modellering, der giver dig mulighed for at versionere dine modeller, generere scripts til at migrere en database fra en version til en anden og korrekt dokumentere enhver designbeslutning.
Uden disse værktøjer skaber hver ændring, du foretager i dit design, integritetsrisici, der kommer frem på de mest uhensigtsmæssige tidspunkter. Vertabelo giver dig al denne funktionalitet og sørger for at vedligeholde versionshistorikken for en model, uden at du overhovedet behøver at tænke over det.
Den automatiske versionering indbygget i Vertabelo er en enorm hjælp til at vedligeholde ændringer af en datamodel.
Ændringsstyring og versionskontrol er også afgørende faktorer for indlejring af datamodelleringsaktiviteter i softwareudviklingens livscyklus.
Refaktorering
Når du anvender ændringer til en database i brug, skal du være 100 % sikker på, at ingen information går tabt, og at dens integritet er upåvirket som følge af ændringerne. For at gøre dette kan du bruge refactoring-teknikker. De anvendes normalt, når du vil forbedre et design uden at påvirke dets semantik, men de kan også bruges til at rette designfejl eller tilpasse en model til nye krav.
Der er et stort antal refactoring-teknikker. De bruges normalt til at give nyt liv til gamle databaser, og der er lærebogsprocedurer, der sikrer, at ændringerne ikke skader den eksisterende information. Der er skrevet hele bøger om det; Jeg anbefaler, at du læser dem.
Men for at opsummere kan vi gruppere refactoring-teknikker i følgende kategorier:
- Datakvalitet: At lave ændringer, der sikrer datakonsistens og sammenhæng. Eksempler inkluderer tilføjelse af en opslagstabel og migrering til den af data, der gentages i en anden tabel, og tilføjelse af en begrænsning på en kolonne.
- Strukturelt: Ændringer i tabelstrukturer, der ikke ændrer modellens semantik. Eksempler inkluderer at kombinere to kolonner til én, tilføje en erstatningsnøgle og opdele en kolonne i to.
- Referentiel integritet: Anvendelse af ændringer for at sikre, at der findes en referencerække i en relateret tabel, eller at en række uden reference kan slettes. Eksempler omfatter tilføjelse af en fremmednøgle-begrænsning på en kolonne og tilføjelse af en ikke-nul værdi-begrænsning til en tabel.
- Arkitektonisk: Foretage ændringer med det formål at forbedre interaktionen mellem applikationer og databasen. Eksempler inkluderer at oprette et indeks, lave en tabel skrivebeskyttet og indkapsle en eller flere tabeller i en visning.
Teknikker, der ændrer modellens semantik, såvel som dem, der ikke ændrer datamodellen på nogen måde, betragtes ikke som refactoring-teknikker. Disse omfatter indsættelse af rækker i en tabel, tilføjelse af en ny kolonne, oprettelse af en ny tabel eller visning og opdatering af dataene i en tabel.
Opretholdelse af informationskvalitet
Informationskvaliteten i en database er i hvilken grad dataene lever op til organisationens forventninger til nøjagtighed, validitet, fuldstændighed og konsistens. Opretholdelse af datakvalitet gennem hele en databases livscyklus er afgørende for, at dens brugere kan træffe korrekte og informerede beslutninger ved at bruge dataene i den.
Dit ansvar som datamodeller er at sikre, at dine modeller holder deres informationskvalitet på det højest mulige niveau. For at gøre dette:
- Designet skal følge mindst den 3. normalform, så der ikke forekommer indsættelses-, opdaterings- eller sletningsanomalier. Denne betragtning gælder hovedsageligt for databaser til transaktionsbrug, hvor data tilføjes, opdateres og slettes regelmæssigt. Det gælder strengt taget ikke i databaser til analytisk brug (dvs. datavarehuse), da dataopdatering og sletning sjældent eller nogensinde udføres.
- Datatyperne for hvert felt i hver tabel skal passe til den attribut, de repræsenterer i den logiske model. Dette går ud over at definere, om et felt er af en numerisk, dato- eller alfanumerisk datatype. Det er også vigtigt at definere området og præcisionen af værdier, der understøttes af hvert felt, korrekt. Et eksempel:en attribut af typen Dato implementeret i en database som et Dato/Tid-felt kan forårsage problemer i forespørgsler, da en værdi, der er gemt med dens anden tidsdel end nul, kan falde uden for omfanget af en forespørgsel, der bruger et datointerval.
- De dimensioner og fakta, der definerer strukturen af et datavarehus, skal stemme overens med virksomhedens behov. Når man designer et datavarehus, skal modellens dimensioner og fakta defineres korrekt fra begyndelsen. At foretage ændringer, når databasen er operationel, medfører en meget høj vedligeholdelsesomkostning.
Håndtering af vækst
En anden stor udfordring i at vedligeholde en database er at forhindre dens vækst i at nå grænsen for lagerkapacitet uventet. For at hjælpe med håndtering af lagerplads kan du anvende det samme princip, som bruges i sikkerhedskopieringsprocedurer:grupper tabellerne i din model efter den hastighed, hvormed de vokser.
En opdeling i to områder er normalt tilstrækkelig. Placer tabellerne med hyppige rækketilføjelser i et område, dem, hvor der sjældent indsættes rækker i et andet. At have modellen opdelt på denne måde giver lageradministratorer mulighed for at opdele databasefilerne i henhold til vækstraten for hvert område. De kan fordele partitionerne mellem forskellige lagermedier med forskellige kapaciteter eller vækstmuligheder.
En gruppering af tabeller efter deres væksthastighed hjælper med at bestemme lagerkravene og styre væksten.
Logføring
Vi opretter en datamodel, der forventer, at den giver informationen, som den er på tidspunktet for forespørgslen. Vi har dog en tendens til at overse behovet for en database til at huske alt, hvad der er sket i fortiden, medmindre brugerne specifikt kræver det.
En del af vedligeholdelsen af en database er at vide hvordan, hvornår, hvorfor og af hvem et bestemt stykke data blev ændret. Det kan være for ting som at finde ud af, hvornår en produktpris ændrede sig eller gennemgå ændringer i journalen for en patient på et hospital. Logning kan endda bruges til at rette bruger- eller applikationsfejl, da det giver dig mulighed for at rulle informationstilstanden tilbage til et punkt i fortiden uden at skulle ty til komplicerede procedurer for gendannelse af sikkerhedskopier.
Igen, selvom brugerne ikke har brug for det eksplicit, er overvejelse af behovet for proaktiv logning et meget værdifuldt middel til at lette databasevedligeholdelse og demonstrere din evne til at forudse problemer. At have logdata giver mulighed for øjeblikkelige svar, når nogen har brug for at gennemgå historiske oplysninger.
Der er forskellige strategier for en databasemodel til at understøtte logning, som alle tilføjer kompleksitet til modellen. En tilgang kaldes in-place logning, som tilføjer kolonner til hver tabel for at registrere versionsoplysninger. Dette er en simpel mulighed, der ikke involverer oprettelse af separate skemaer eller logningsspecifikke tabeller. Det påvirker dog modeldesignet, fordi de oprindelige primærnøgler i tabellerne ikke længere er gyldige som primærnøgler – deres værdier gentages i rækker, der repræsenterer forskellige versioner af de samme data.
En anden mulighed for at beholde logoplysninger er at bruge skyggetabeller. Skyggetabeller er replikaer af modeltabellerne med tilføjelse af kolonner for at registrere logspordata. Denne strategi kræver ikke ændring af tabellerne i den originale model, men du skal huske at opdatere de tilsvarende skyggetabeller, når du ændrer din datamodel.
Endnu en strategi er at anvende et underskema af generiske tabeller, der registrerer hver indsættelse, sletning eller ændring af enhver anden tabel.
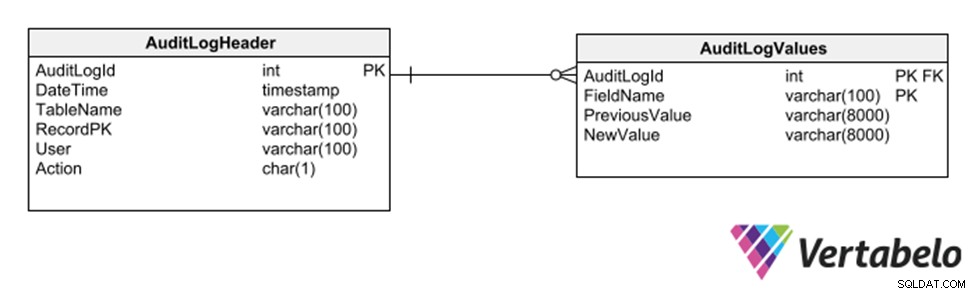
Generiske tabeller til at holde et revisionsspor for en database.
Denne strategi har den fordel, at den ikke kræver modifikationer af modellen for registrering af et revisionsspor. Men fordi den bruger generiske kolonner af varchar-typen, begrænser den de typer data, der kan registreres i log-sporet.
Ydeevnevedligeholdelse og indeksoprettelse
Praktisk talt enhver database har god ydeevne, når den lige er begyndt at blive brugt, og dens tabeller kun indeholder nogle få rækker. Men så snart applikationer begynder at udfylde den med data, kan ydeevnen forringes meget hurtigt, hvis der ikke tages forholdsregler ved design af modellen. Når dette sker, ringer DBA'er og systemadministratorer til dig for at hjælpe dem med at løse ydeevneproblemer.
Den automatiske oprettelse/forslag af indekser på produktionsdatabaser er et nyttigt værktøj til at løse ydeevneproblemer "i øjeblikkets hede." Databasemotorer kan analysere databaseaktiviteter for at se, hvilke operationer der tager længst tid, og hvor der er muligheder for at fremskynde ved at oprette indekser.
Det er dog meget bedre at være proaktiv og forudse situationen ved at definere indekser som en del af datamodellen. Dette reducerer i høj grad vedligeholdelsesindsatsen for at forbedre databasens ydeevne. Hvis du ikke er bekendt med fordelene ved databaseindekser, foreslår jeg, at du læser alt om indekser, begyndende med det helt grundlæggende.
Der er praktiske regler, der giver tilstrækkelig vejledning til at skabe de vigtigste indekser til effektive forespørgsler. Den første er at generere indekser for den primære nøgle i hver tabel. Næsten alle RDBMS genererer automatisk et indeks for hver primær nøgle, så du kan glemme denne regel.
En anden regel er at generere indekser for alternative nøgler til en tabel, især i tabeller, for hvilke der er oprettet en surrogatnøgle. Hvis en tabel har en naturlig nøgle, der ikke bruges som en primær nøgle, vil forespørgsler om at forbinde den tabel med andre sandsynligvis gøre det med den naturlige nøgle, ikke surrogaten. Disse forespørgsler fungerer ikke godt, medmindre du opretter et indeks på den naturlige nøgle.
Den næste tommelfingerregel for indekser er at generere dem for alle felter, der er fremmednøgler. Disse felter er gode kandidater til at etablere sammenføjninger med andre tabeller. Hvis de er inkluderet i indekser, bruges de af forespørgselsparsere til at fremskynde eksekveringen og forbedre databasens ydeevne.
Endelig er det en god idé at bruge et profileringsværktøj på en iscenesættelse eller QA-database under præstationstests for at opdage eventuelle indeksoprettelsesmuligheder, der ikke er indlysende. At inkorporere de indekser, der foreslås af profileringsværktøjerne, i datamodellen er yderst hjælpsom til at opnå og vedligeholde databasens ydeevne, når den først er i produktion.
Sikkerhed
I din rolle som datamodeller kan du hjælpe med at vedligeholde databasesikkerheden ved at skabe en solid og sikker base, hvor du kan gemme data til brugergodkendelse. Husk, at disse oplysninger er meget følsomme og må ikke udsættes for cyberangreb.
For at dit design skal forenkle vedligeholdelsen af databasesikkerheden, skal du følge den bedste praksis for lagring af godkendelsesdata, hvoraf den vigtigste er ikke at gemme adgangskoder i databasen, selv i krypteret form. Hvis du kun gemmer dens hash i stedet for adgangskoden for hver bruger, kan en applikation godkende et brugerlogin uden at skabe nogen risiko for adgangskodeeksponering.
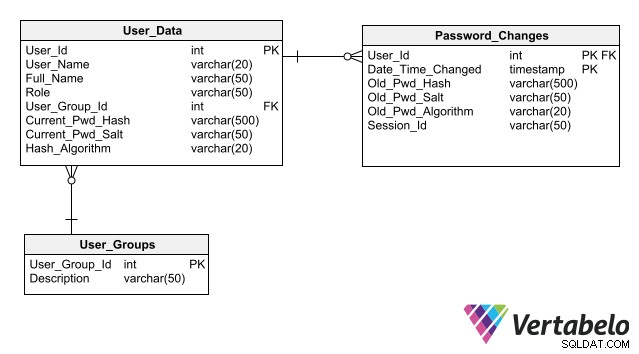
Et komplet skema til brugergodkendelse, der inkluderer kolonner til lagring af hashes til adgangskode.
Vision for fremtiden
Så opret dine modeller for nem databasevedligeholdelse med gode databasedesigns ved at tage hensyn til tipsene ovenfor. Med mere vedligeholdelige datamodeller ser dit arbejde bedre ud, og du opnår påskønnelse af DBA'er, vedligeholdelsesingeniører og systemadministratorer.
Du investerer også i ro i sindet. Oprettelse af let vedligeholdelige databaser betyder, at du kan bruge din arbejdstid på at designe nye datamodeller i stedet for at løbe rundt med at patche databaser, der ikke leverer korrekte oplysninger til tiden.