
Til denne måneds T-SQL-tirsdag bad Steve Jones (@way0utwest) os om at tale om vores bedste eller værste triggeroplevelser. Selvom det er rigtigt, at triggere ofte er ilde set og endda frygtet, har de flere gyldige use cases, herunder:
- Revision (før 2016 SP1, hvor denne funktion blev gratis i alle udgaver)
- Håndhævelse af forretningsregler og dataintegritet, når de ikke nemt kan implementeres i begrænsninger, og du ikke ønsker, at de skal være afhængige af applikationskoden eller selve DML-forespørgslerne
- Vedligeholdelse af historiske versioner af data (før ændringsdatafangst, ændringssporing og tidstabeller)
- Kø-advarsler eller asynkron behandling som svar på en specifik ændring
- Tillader ændringer af visninger (via I STEDET FOR triggere)
Det er ikke en udtømmende liste, bare en hurtig opsummering af et par scenarier, jeg har oplevet, hvor triggere var det rigtige svar på det tidspunkt.
Når triggere er nødvendige, kan jeg altid godt lide at udforske brugen af I STEDET FOR triggere frem for EFTER-triggere. Ja, de er lidt mere forhåndsarbejde*, men de har nogle ret vigtige fordele. I det mindste i teorien virker udsigten til at forhindre en handling (og dens logkonsekvenser) i at ske meget mere effektiv end at lade det hele ske og derefter fortryde det.
*Jeg siger dette, fordi du skal kode DML-sætningen igen inden for triggeren; det er derfor, de ikke kaldes FØR triggere. Sondringen er vigtig her, da nogle systemer implementerer ægte FØR triggere, som blot kører først. I SQL Server annullerer en INSTEAD OF-trigger effektivt den sætning, der fik den til at udløses.
Lad os foregive, at vi har en simpel tabel til at gemme kontonavne. I dette eksempel opretter vi to tabeller, så vi kan sammenligne to forskellige udløsere og deres indvirkning på forespørgselsvarighed og logbrug. Konceptet er, at vi har en forretningsregel:kontonavnet er ikke til stede i en anden tabel, som repræsenterer "dårlige" navne, og udløseren bruges til at håndhæve denne regel. Her er databasen:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO Og tabellerne:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
Og endelig triggerne. For nemheds skyld beskæftiger vi os kun med indstik, og i både efter- og i stedet for tilfælde vil vi bare afbryde hele batchen, hvis et enkelt navn overtræder vores regel:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO For nu at teste ydeevnen vil vi bare prøve at indsætte 100.000 navne i hver tabel med en forudsigelig fejlrate på 10 %. Med andre ord, 90.000 er okay navne, de andre 10.000 fejler testen og får triggeren til enten at rulle tilbage eller ikke indsættes afhængigt af batchen.
Først skal vi rydde op før hver batch:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Før vi starter kødet i hver batch, tæller vi rækkerne i transaktionsloggen og måler størrelsen og ledig plads. Derefter går vi gennem en markør for at behandle de 100.000 rækker i tilfældig rækkefølge og forsøger at indsætte hvert navn i den relevante tabel. Når vi er færdige, måler vi rækkeantallet og størrelsen af loggen igen og tjekker varigheden.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Resultater (gennemsnit over 5 kørsler af hver batch):
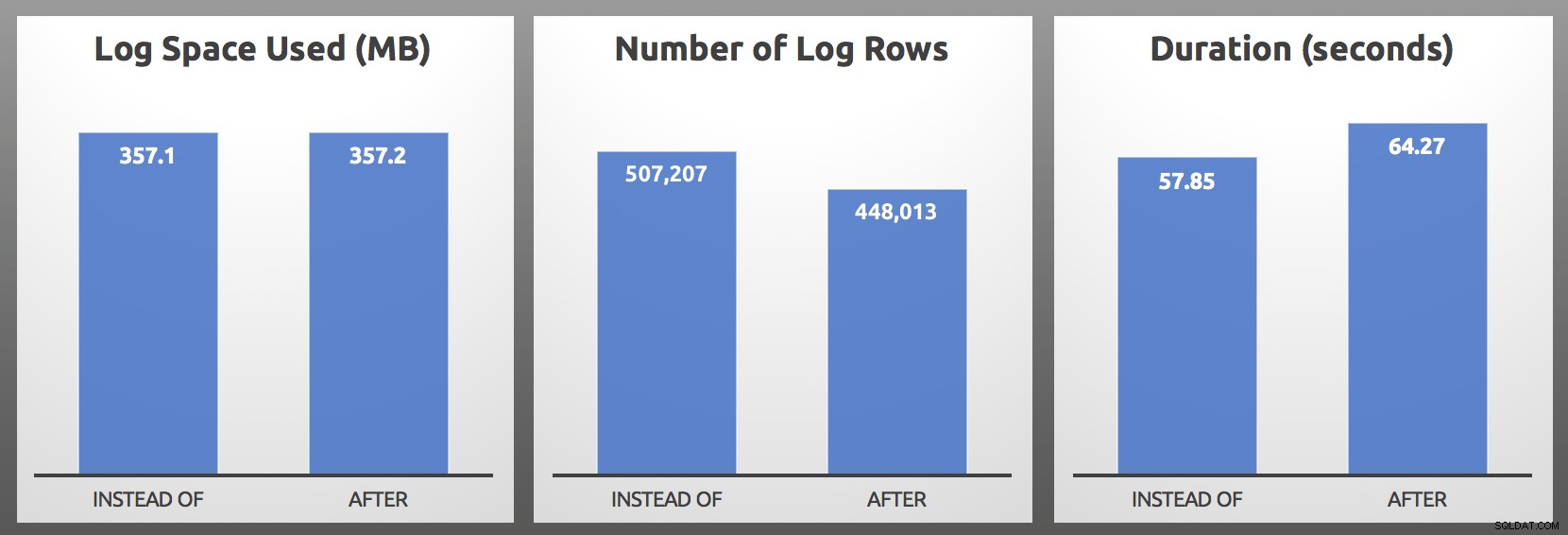 EFTER vs. I STEDET FOR :Resultater
EFTER vs. I STEDET FOR :Resultater
I mine test var logbruget næsten identisk i størrelse, med over 10 % flere logrækker genereret af ISTEAD FOR udløseren. Jeg gravede lidt i slutningen af hver batch:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Og her var et typisk resultat (jeg fremhævede de store deltaer):
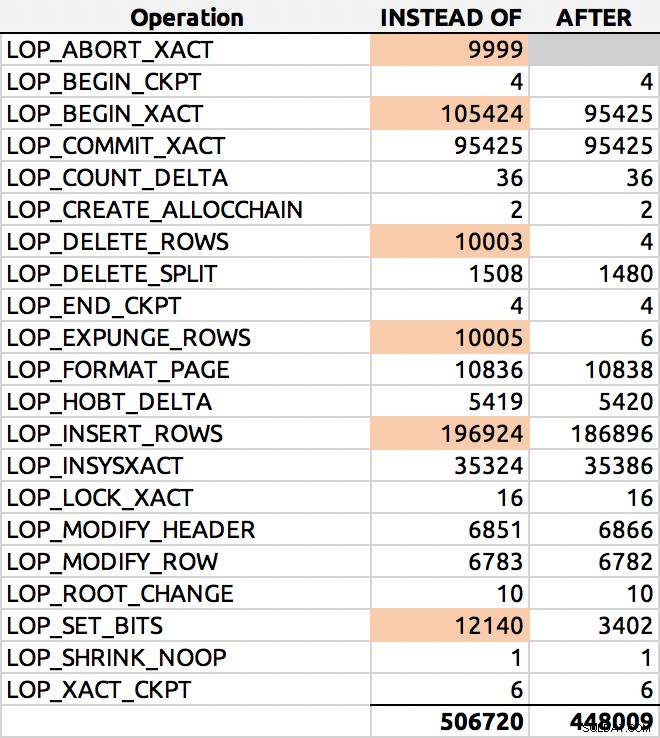 Logrækkefordeling
Logrækkefordeling
Det vil jeg grave dybere i en anden gang.
Men når du kommer helt i mål...
…den vigtigste metrik vil næsten altid være varighed , og i mit tilfælde fungerede ISTED FOR triggeren mindst 5 sekunder hurtigere i hver enkelt head-to-head test. Hvis det hele lyder bekendt, ja, jeg har talt om det før, men dengang så jeg ikke de samme symptomer med logrækkerne.
Bemærk, at dette muligvis ikke er dit nøjagtige skema eller arbejdsbyrde, du kan have meget forskellig hardware, din samtidighed kan være højere, og din fejlrate kan være meget højere (eller lavere). Mine tests blev udført på en isoleret maskine med masser af hukommelse og meget hurtige PCIe SSD'er. Hvis din log er på et langsommere drev, så kan forskellene i logbrug opveje de andre målinger og ændre varigheden betydeligt. Alle disse faktorer (og flere!) kan påvirke dine resultater, så du bør teste i dit miljø.
Pointen er dog, at I STEDET FOR triggere kan passe bedre. Hvis nu bare vi kunne få I STEDET FOR DDL-triggere...