Gaps and Islands-opgaver er klassiske forespørgselsudfordringer, hvor du skal identificere rækker af manglende værdier og rækker af eksisterende værdier i en sekvens. Sekvensen er ofte baseret på nogle dato- eller dato- og klokkeslætsværdier, der normalt skal vises med jævne mellemrum, men nogle poster mangler. Hulopgaven leder efter de manglende perioder, og øopgaven leder efter de eksisterende perioder. Jeg dækkede mange løsninger på huller og ø-opgaver i mine bøger og artikler tidligere. For nylig blev jeg præsenteret for en ny speciel ø-udfordring af min ven, Adam Machanic, og at løse den krævede lidt kreativitet. I denne artikel præsenterer jeg udfordringen og den løsning, jeg fandt på.
Udfordringen
I din database holder du styr på tjenester, som din virksomhed understøtter, i en tabel kaldet CompanyServices, og hver tjeneste rapporterer normalt cirka én gang i minuttet, at den er online i en tabel kaldet EventLog. Følgende kode opretter disse tabeller og udfylder dem med små sæt eksempeldata:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
EventLog-tabellen er i øjeblikket udfyldt med følgende data:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Den særlige ø-opgave er at identificere tilgængelighedsperioderne (serviceret, starttidspunkt, sluttidspunkt). En fangst er, at der ikke er nogen sikkerhed for, at en tjeneste vil rapportere, at den er online præcis hvert minut; du formodes at tolerere et interval på op til f.eks. 66 sekunder fra den forrige logindtastning og stadig betragte det som en del af den samme tilgængelighedsperiode (ø). Efter 66 sekunder starter den nye logpost en ny tilgængelighedsperiode. Så for input-eksempeldataene ovenfor formodes din løsning at returnere følgende resultatsæt (ikke nødvendigvis i denne rækkefølge):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Bemærk for eksempel, hvordan logindtastning 5 starter en ny ø, da intervallet fra den forrige logindtastning er 120 sekunder (> 66), hvorimod logindtastning 6 ikke starter en ny ø, da intervallet fra den forrige post er 62 sekunder ( <=66). En anden fangst er, at Adam ønskede, at løsningen skulle være kompatibel med præ-SQL Server 2012-miljøer, hvilket gør det til en meget sværere udfordring, da du ikke kan bruge aggregerede vinduesfunktioner med en ramme til at beregne løbende totaler og offset-vinduefunktioner som LAG og LEAD. Som sædvanlig foreslår jeg, at du prøver at løse udfordringen selv, før du ser på mine løsninger. Brug de små sæt eksempeldata til at kontrollere gyldigheden af dine løsninger. Brug følgende kode til at udfylde dine tabeller med store sæt af eksempeldata (500 tjenester, ~10 millioner logposter til at teste ydeevnen af dine løsninger):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; De output, som jeg vil levere til trinene i mine løsninger, vil antage de små sæt af eksempeldata, og de præstationstal, som jeg vil levere, vil antage de store sæt.
Alle de løsninger, som jeg vil præsentere, drager fordel af følgende indeks:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Held og lykke!
Løsning 1 til SQL Server 2012+
Før jeg dækker en løsning, der er kompatibel med præ-SQL Server 2012-miljøer, vil jeg dække en, der kræver et minimum af SQL Server 2012. Jeg vil kalde det Løsning 1.
Det første trin i løsningen er at beregne et flag kaldet isstart, der er 0, hvis begivenheden ikke starter en ny ø, og 1 ellers. Dette kan opnås ved at bruge LAG-funktionen til at få log-tiden for den forrige hændelse og kontrollere, om tidsforskellen i sekunder mellem de foregående og aktuelle hændelser er mindre end eller lig med det tilladte mellemrum. Her er koden, der implementerer dette trin:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Denne kode genererer følgende output:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Dernæst producerer en simpel løbende total af isstart-flaget en ø-id (jeg kalder det grp). Her er koden, der implementerer dette trin:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Denne kode genererer følgende output:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Til sidst grupperer du rækkerne efter service-id og ø-id og returnerer minimum og maksimum logtid som starttidspunkt og sluttidspunkt for hver ø. Her er den komplette løsning:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Denne løsning tog 41 sekunder at fuldføre på mit system og producerede planen vist i figur 1.
 Figur 1:Plan for løsning 1
Figur 1:Plan for løsning 1
Som du kan se, er begge vinduesfunktioner beregnet ud fra indeksrækkefølge, uden behov for eksplicit sortering.
Hvis du bruger SQL Server 2016 eller nyere, kan du bruge det trick, jeg dækker her, til at aktivere batch-tilstanden Window Aggregate-operator ved at oprette et tomt filtreret kolonnelagerindeks, som sådan:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Den samme løsning tager nu kun 5 sekunder at fuldføre på mit system, hvilket producerer planen vist i figur 2.
 Figur 2:Planlæg løsning 1 ved hjælp af batch-tilstand Window Aggregate-operator
Figur 2:Planlæg løsning 1 ved hjælp af batch-tilstand Window Aggregate-operator
Det hele er fantastisk, men som nævnt ledte Adam efter en løsning, der kan køre på miljøer før 2012.
Før du fortsætter, skal du sørge for at slette kolonnelagerindekset til oprydning:
DROP INDEX idx_cs ON dbo.EventLog;
Løsning 2 til præ-SQL Server 2012-miljøer
Desværre havde vi før SQL Server 2012 ikke understøttelse af offset-vinduefunktioner som LAG, og vi havde heller ikke understøttelse til at beregne kørende totaler med vinduesaggregerede funktioner med en ramme. Det betyder, at du bliver nødt til at arbejde meget hårdere for at finde en fornuftig løsning.
Det trick, jeg brugte, er at omdanne hver logindtastning til et kunstigt interval, hvis starttidspunkt er postens logtid, og hvis sluttidspunkt er postens logtid plus det tilladte mellemrum. Du kan derefter behandle opgaven som en klassisk intervalpakkeopgave.
Det første trin i løsningen beregner de kunstige intervalafgrænsninger og rækkenumre, der markerer positionerne for hver af begivenhedstyperne (counteach). Her er koden, der implementerer dette trin:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Denne kode genererer følgende output:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Det næste trin er at udskifte intervallerne til en kronologisk sekvens af start- og sluthændelser, identificeret som hændelsestyperne henholdsvis 's' og 'e'. Bemærk, at valget af bogstaverne s og e er vigtigt ('s' > 'e' ). Dette trin beregner rækkenumre, der markerer den korrekte kronologiske rækkefølge af begge begivenhedstyper, som nu er sammenflettet (tæller begge). Hvis et interval slutter præcis, hvor et andet starter, pakker du dem sammen ved at placere startbegivenheden før slutbegivenheden. Her er koden, der implementerer dette trin:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Denne kode genererer følgende output:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Som nævnt markerer counteach begivenhedens position blandt kun begivenheder af samme art, og countbegge markerer begivenhedens position blandt de kombinerede, interleaved begivenheder af begge slags.
Magien håndteres derefter af det næste trin - udregning af antallet af aktive intervaller efter hver begivenhed baseret på counteach og countboth. Antallet af aktive intervaller er antallet af startbegivenheder, der er sket indtil videre minus antallet af slutbegivenheder, der er sket indtil videre. For startbegivenheder fortæller counteach dig, hvor mange startbegivenheder der er sket indtil videre, og du kan finde ud af hvor mange der er endt indtil videre ved at trække counteach fra countbegge. Så det komplette udtryk, der fortæller dig, hvor mange intervaller der er aktive, er så:
counteach - (countboth - counteach)
For sluthændelser fortæller counteach dig, hvor mange sluthændelser der er sket indtil videre, og du kan finde ud af hvor mange der er startet indtil videre ved at trække counteach fra countbegge. Så det komplette udtryk, der fortæller dig, hvor mange intervaller der er aktive, er så:
(countboth - counteach) - counteach
Ved at bruge følgende CASE-udtryk beregner du den tælleaktive kolonne baseret på hændelsestypen:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END I samme trin filtrerer du kun hændelser, der repræsenterer start og slutning af pakkede intervaller. Starter af pakkede intervaller har en type 's' og en tæller 1. Slutter af pakkede intervaller har en type 'e' og en tæller 0.
Efter filtrering står du tilbage med par af start-slut-begivenheder med pakkede intervaller, men hvert par er opdelt i to rækker - en til startbegivenheden og en anden til slutbegivenheden. Derfor beregner det samme trin paridentifikation ved at bruge rækkenumre med formlen (rækkenummer – 1) / 2 + 1.
Her er koden, der implementerer dette trin:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Denne kode genererer følgende output:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Det sidste trin pivoterer hændelsesparrene til en række pr. interval og trækker det tilladte mellemrum fra sluttidspunktet for at genskabe det korrekte hændelsestidspunkt. Her er den komplette løsnings kode:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Denne løsning tog 43 sekunder at fuldføre på mit system og genererede planen vist i figur 3.
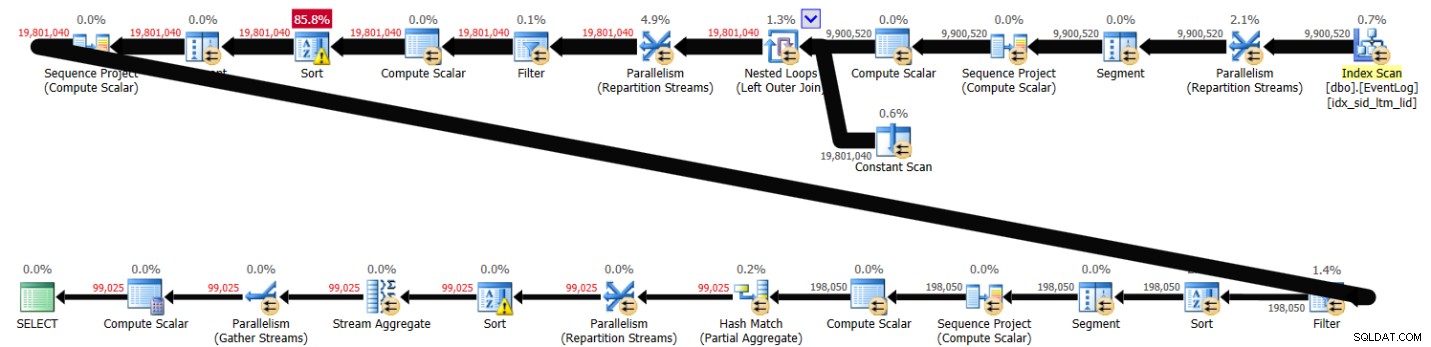 Figur 3:Plan for løsning 2
Figur 3:Plan for løsning 2
Som du kan se, beregnes den første rækkenummer ud fra indeksrækkefølge, men de næste to involverer eksplicit sortering. Alligevel er ydeevnen ikke så dårlig i betragtning af, at der er omkring 10.000.000 rækker involveret.
Selvom pointen med denne løsning er at bruge et præ-SQL Server 2012 miljø, for sjov, testede jeg dens ydeevne efter at have oprettet et filtreret kolonnelagerindeks for at se, hvordan det klarer sig med batchbehandling aktiveret:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Med batchbehandling aktiveret tog denne løsning 29 sekunder at afslutte på mit system, hvilket producerede planen vist i figur 4.
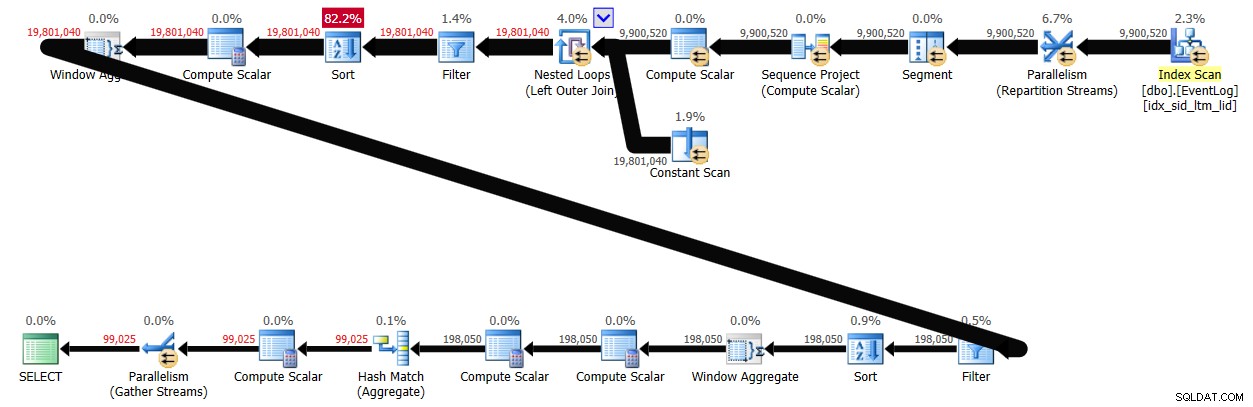
Konklusion
Det er naturligt, at jo mere begrænset dit miljø er, jo mere udfordrende bliver det at løse forespørgselsopgaver. Adams særlige Islands-udfordring er meget nemmere at løse på nyere versioner af SQL Server end på ældre. Men så tvinger du dig selv til at bruge mere kreative teknikker. Så som en øvelse, for at forbedre dine forespørgselsevner, kan du tackle udfordringer, som du allerede er bekendt med, men med vilje pålægge visse begrænsninger. Du ved aldrig, hvilke slags interessante ideer du kan falde i!