Vi har for nylig lanceret et nyt supportwebsted, hvor du kan stille spørgsmål, indsende produktfeedback eller funktionsanmodninger eller åbne supportbilletter. En del af målet var at centralisere alle de steder, hvor vi tilbød hjælp til lokalsamfundet. Dette omfattede SQLPerformance.com Q&A-webstedet, hvor Paul White, Hugo Kornelis og mange andre har hjulpet med at løse dine mest komplicerede spørgsmål til justering af forespørgsler og udførelsesplan, helt tilbage til februar 2013. Jeg fortæller dig med blandede følelser, at Spørgsmål og svar-websted er blevet lukket.
Der er dog en opside. Du kan nu stille de svære spørgsmål på det nye supportforum. Hvis du leder efter det gamle indhold, så er det der stadig, men det ser lidt anderledes ud. Af en række forskellige årsager, som jeg ikke vil komme ind på i dag, besluttede vi, da vi besluttede at lukke det originale Q&A-websted, i sidste ende at være vært for alt eksisterende indhold på et skrivebeskyttet WordPress-websted i stedet for at migrere det til bagenden af den nye side.
Dette indlæg handler ikke om årsagerne bag denne beslutning.
Jeg havde det virkelig dårligt med, hvor hurtigt svarsiden skulle komme offline, DNS'en skiftede, og indholdet migrerede. Da et advarselsbanner blev implementeret på webstedet, men AnswerHub faktisk ikke gjorde det synligt, var dette et chok for mange brugere. Så jeg ville sikre mig, at jeg beholdt så meget af indholdet, som jeg kunne, og jeg ønskede, at det skulle være rigtigt. Dette indlæg er her, fordi jeg tænkte, at det ville være interessant at tale om selve processen, hvor mange forskellige stykker teknologi, der var involveret i at trække det frem, og at vise resultatet frem. Jeg forventer ikke, at nogen af jer vil drage fordel af denne ende-til-ende, da dette er en relativt obskur migrationsvej, men mere som et eksempel på at binde en masse teknologier sammen for at udføre en opgave. Det tjener også som en god påmindelse til mig selv om, at mange ting ikke ender med at være så nemme, som de lyder, før du starter.
TL;DR er dette:Jeg brugte en masse tid og kræfter på at få det arkiverede indhold til at se godt ud, selvom jeg stadig forsøger at gendanne de sidste par indlæg, der kom ind mod slutningen. Jeg brugte disse teknologier:
- Perl
- SQL-server
- PowerShell
- Transmit (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Deraf titlen. Hvis du vil have en stor del af de blodige detaljer, er de her. Hvis du har spørgsmål eller feedback, bedes du kontakte os eller kommentere nedenfor.
AnswerHub leverede en 665 MB dumpfil fra MySQL-databasen, der var vært for Q&A-indholdet. Hver editor, jeg prøvede, blev kvalt i den, så jeg var først nødt til at dele den op i en fil pr. tabel ved hjælp af dette praktiske Perl-script fra Jared Cheney. De tabeller, jeg havde brug for, hed network11_nodes (spørgsmål, svar og kommentarer), network11_authoritables (brugere) og network11_managed_files (alle vedhæftede filer, inklusive planuploads):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Nu var de ikke ekstremt hurtige at indlæse i SSMS, men der kunne jeg i det mindste bruge Ctrl +H for at ændre (for eksempel) dette:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
Til dette:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Så kunne jeg indlæse dataene i SQL Server, så jeg kunne manipulere dem. Og tro mig, jeg manipulerede det.
Dernæst skulle jeg hente alle de vedhæftede filer. Se, MySQL-dumpfilen, jeg fik fra leverandøren, indeholdt en gazillion INSERT erklæringer, men ingen af de faktiske planfiler, som brugerne havde uploadet - databasen havde kun de relative stier til filerne. Jeg brugte T-SQL til at bygge en række PowerShell-kommandoer, der ville kalde Invoke-WebRequest at hente alle filerne og gemme dem lokalt (mange måder at flå denne kat på, men det var helt let). Fra dette:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Det gav dette sæt kommandoer (sammen med en forhåndskommando til at løse dette TLS-problem); det hele kørte ret hurtigt, men jeg anbefaler ikke denne tilgang til nogen kombination af {massive set of files} og/eller {low bandwidth}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Dette downloadede næsten alle vedhæftede filer, men nogle blev ganske vist savnet på grund af fejl på det gamle websted, da de oprindeligt blev uploadet. Så på det nye websted kan du lejlighedsvis se en henvisning til en vedhæftet fil, der ikke eksisterer.
Så brugte jeg Panic Transmit 5 til at uploade temp mappe til det nye websted, og nu, når indholdet bliver uploadet, links til /s/temp/1-proc.pesession vil fortsætte med at arbejde.
Dernæst gik jeg videre til SSL. For at anmode om et certifikat på det nye WordPress-websted, var vi nødt til at opdatere DNS for answers.sqlperformance.com til at pege på CNAME over på vores WordPress-vært, WPEngine. Det var en slags kylling og æg her - vi måtte lide lidt nedetid for https-URL'er, som ville mislykkes for intet certifikat på det nye websted. Dette var okay, fordi certifikatet på det gamle websted var udløbet, så vi var faktisk ikke værre stillet. Jeg måtte også vente med at gøre dette, indtil jeg havde downloadet alle filerne fra det gamle websted, for når først DNS vendte om, ville der ikke være nogen måde at komme til dem på undtagen gennem en bagdør.
Mens jeg ventede på, at DNS skulle udbrede sig, begyndte jeg at arbejde på logikken for at trække alle spørgsmål, svar og kommentarer til noget, der kan forbruges i WordPress. Ikke alene var tabelskemaerne forskellige fra WordPress, typerne af entiteter er også ret forskellige. Min vision var at kombinere hvert spørgsmål – og eventuelle svar og/eller kommentarer – i et enkelt indlæg.
Den vanskelige del er, at nodetabellen blot indeholder alle de tre indholdstyper i samme tabel, med overordnede og originale ("master") overordnede referencer. Deres front-end-kode bruger sandsynligvis en form for markør til at gå igennem og vise indholdet i en hierarkisk og kronologisk rækkefølge. Jeg ville ikke have den luksus i WordPress, så jeg var nødt til at samle HTML-koden sammen i ét skud. Bare som et eksempel, her er, hvordan dataene så ud:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Jeg kunne ikke bestille efter id, type eller efter forælder, da der nogle gange kom en kommentar senere på et tidligere svar, det første svar ville ikke altid være det accepterede svar, og så videre. Jeg ønskede dette output (hvor ++ repræsenterer et niveau af indrykning):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Jeg begyndte at skrive en rekursiv CTE og
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Resultater:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Geni. Jeg tjekkede et dusin andre og var glad for at gå videre til næste trin. Jeg har takket Andy mange gange, men lad mig gøre det igen:Tak Andy!
Nu hvor jeg kunne returnere hele sættet i den rækkefølge, jeg kunne lide, var jeg nødt til at udføre en vis manipulation af outputtet for at anvende HTML-elementer og klassenavne, der ville lade mig markere spørgsmål, svar, kommentarer og indrykning på en meningsfuld måde. Slutmålet var output, der så sådan ud (og husk, dette er et af de mere simple tilfælde):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Jeg vil ikke træde igennem det latterlige antal gentagelser, jeg skulle igennem for at lande på en pålidelig form for det output for alle 5.000+ elementer (hvilket oversat til næsten 1.000 indlæg, når alt var limet sammen). Oven i det havde jeg brug for at generere disse i form af INSERT erklæringer, som jeg derefter kunne indsætte i phpMyAdmin på WordPress-webstedet, hvilket betød, at jeg skulle overholde deres bizarre syntaksdiagram. Disse udsagn er nødvendige for at inkludere andre yderligere oplysninger, der kræves af WordPress, men som ikke er til stede eller nøjagtige i kildedataene (såsom post_type ). Og den admin-konsol ville time-out givet for mange data, så jeg var nødt til at dele den ud i ~750 inserts ad gangen. Her er den procedure, jeg endte med (dette er egentlig ikke til at lære noget specifikt af, bare en demonstration af, hvor meget manipulation af de importerede data var nødvendig):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO Outputtet fra det er ikke komplet og ikke klar til at fylde i WordPress endnu:
 Eksempeloutput (klik for at forstørre)
Eksempeloutput (klik for at forstørre)
Jeg ville have brug for noget ekstra hjælp fra C# til at omdanne det faktiske indhold (inklusive markdown) til HTML og CSS, som jeg kunne kontrollere bedre, og skrive outputtet (en masse INSERT udsagn, der tilfældigvis inkluderede en masse HTML-kode) til filer på disken, jeg kunne åbne og indsætte i phpMyAdmin. For HTML, almindelig tekst + markdown, der startede sådan her:
VÆLG noget fra dbo.sometable;
[1]:https://andetsteds
Skal blive dette:
Der er et blogindlæg her , der fortæller om det, og også dette indlæg .
VÆLG noget fra dbo.sometable; For at gøre dette, fik jeg hjælp fra MarkdownSharp, et open source-bibliotek, der stammer fra Stack Overflow, der håndterer meget af markdown-til-HTML-konverteringen. Det passede godt til mine behov, men ikke perfekt; Jeg ville stadig skulle udføre yderligere manipulation:
- MarkdownSharp tillader ikke ting som
target=_blank, så jeg skulle selv injicere dem efter behandlingen; - kode (alt med præfiks med fire mellemrum) arver
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Ja, det er en grim flok kode, men det fik mig endelig til det sæt af output, der ikke ville få phpMyAdmin til at brække sig, og som WordPress ville præsentere pænt (nok). Jeg kaldte simpelthen C#-programmet flere gange med de forskellige parameterområder:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Så åbnede jeg hver af filerne, indsatte dem i phpMyAdmin og trykkede på GO:
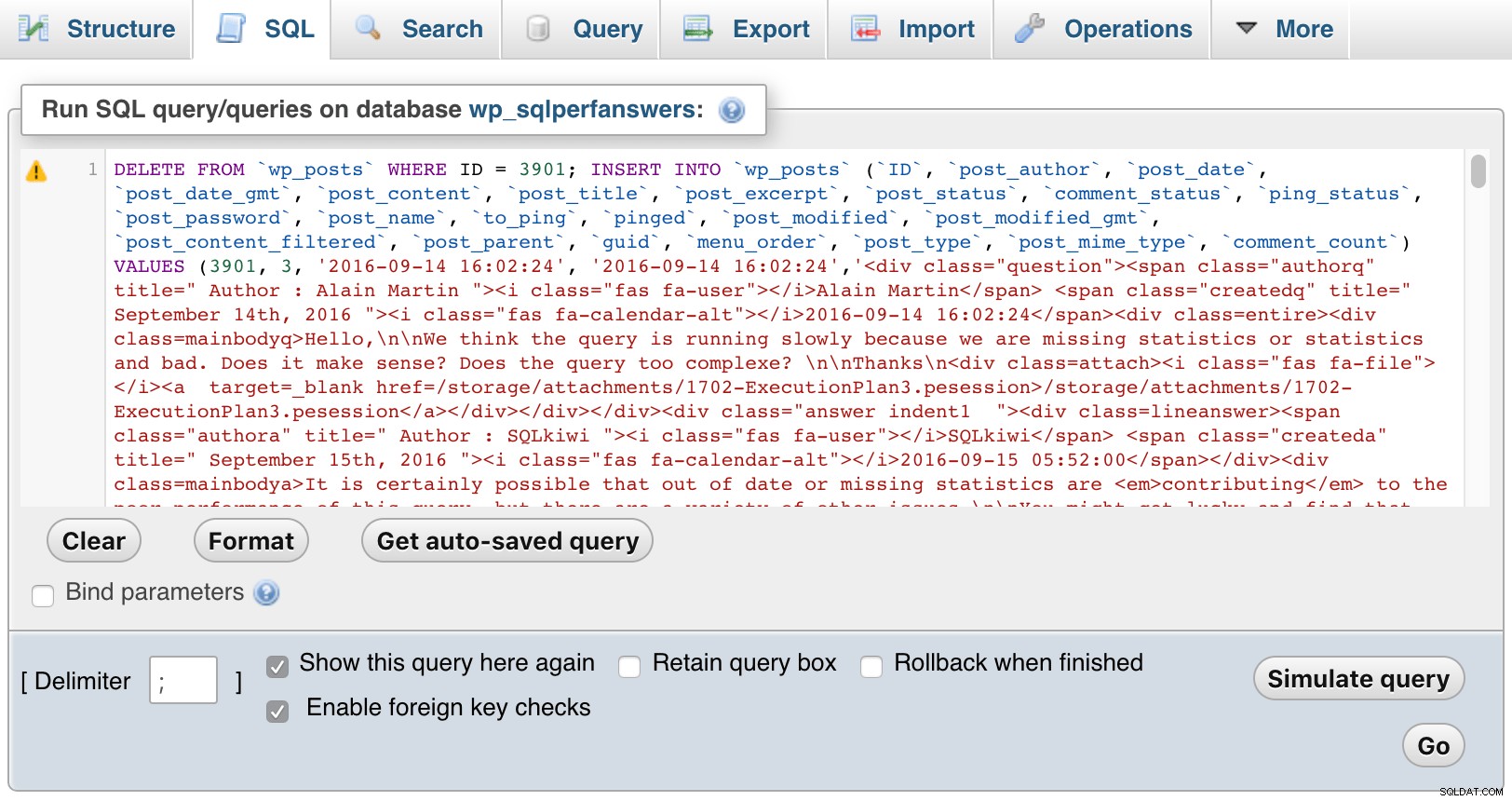 phpMyAdmin (klik for at forstørre)
phpMyAdmin (klik for at forstørre) Selvfølgelig var jeg nødt til at tilføje noget CSS i WordPress for at hjælpe med at skelne mellem spørgsmål, kommentarer og svar, og for også at indrykke kommentarer for at vise svar på både spørgsmål og svar, indlejre kommentarer til at svare på kommentarer, og så videre. Sådan ser et uddrag ud, når du borer igennem til en måneds spørgsmål:
 Spørgsmålsfelt (klik for at forstørre)
Spørgsmålsfelt (klik for at forstørre) Og så et eksempelindlæg, der viser indlejrede billeder, flere vedhæftede filer, indlejrede kommentarer og et svar:
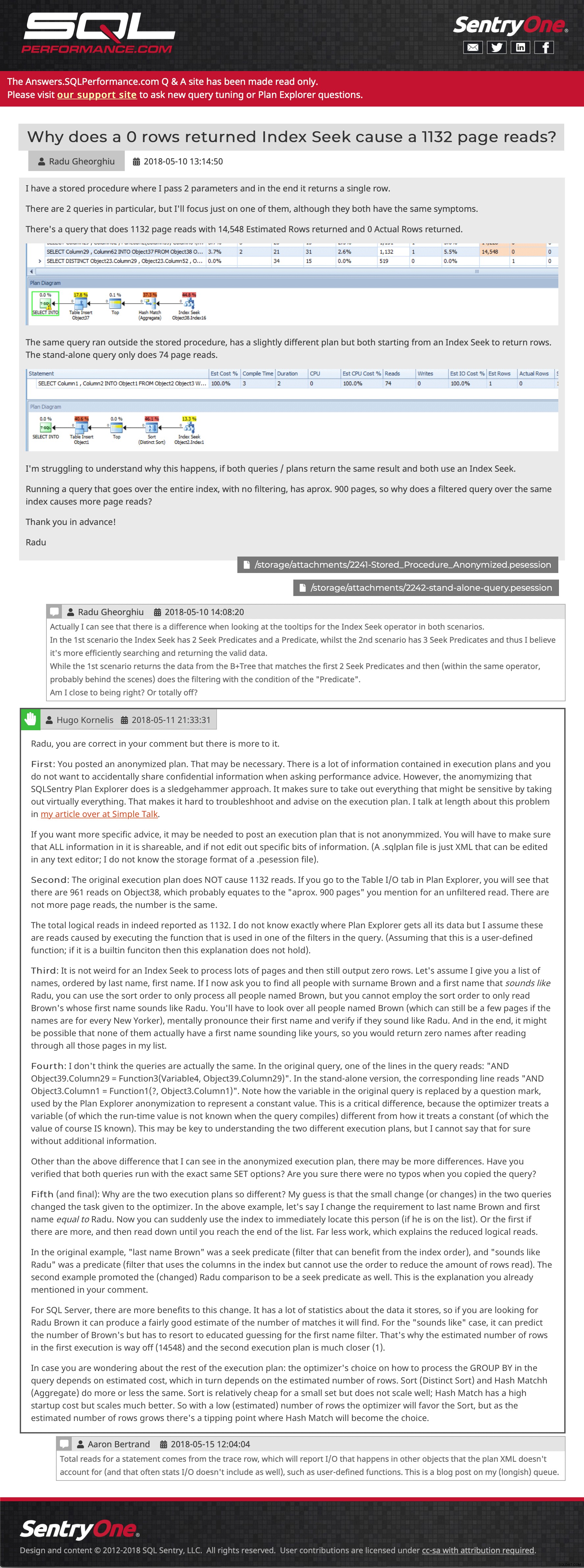 Eksempel på spørgsmål og svar (klik for at gå dertil)
Eksempel på spørgsmål og svar (klik for at gå dertil) Jeg forsøger stadig at gendanne et par indlæg, der blev indsendt til webstedet efter den sidste backup blev taget, men jeg byder dig velkommen til at browse rundt. Fortæl os venligst, hvis du opdager noget, der mangler eller er forkert, eller bare for at fortælle os, at indholdet stadig er nyttigt for dig. Vi håber på at genindføre funktionaliteten for planupload fra Plan Explorer, men det vil kræve noget API-arbejde på det nye supportwebsted, så jeg har ikke en ETA til dig i dag.
- Answers.SQLPerformance.com