Et af de mest almindelige udtryk, der kommer op i diskussioner om justering af SQL Server-ydelse er ventestatistikker . Dette går langt tilbage, selv før dette Microsoft-dokument fra 2006, "SQL Server 2005 Venter og Køer."
Venter er absolut ikke alt, og denne metode er ikke den eneste måde at tune en instans på, pyt med en individuel forespørgsel. Faktisk er ventetider ofte ubrugelige, når alt hvad du har er den forespørgsel, der led dem, og ingen omgivende kontekst, især længe efter kendsgerningen. Dette er fordi, ret ofte, det, en forespørgsel venter på, ikke er den forespørgsels skyld . Som noget andet er der undtagelser, men hvis du kun vælger et værktøj eller script, fordi det tilbyder denne meget specifikke funktionalitet, tror jeg, du gør dig selv en bjørnetjeneste. Jeg plejer at følge et råd, som Paul Randal gav mig for noget tid siden:
...generelt anbefaler jeg, at man starter med ventetider for hele forekomster. Jeg ville aldrig starte fejlfinding ved at se på individuelle forespørgsler.
Nogle gange, ja, vil du måske grave dybere ned i en individuel forespørgsel og se, hvad den venter på; faktisk tilføjede Microsoft for nylig ventestatistikker på forespørgselsniveau for at showplan for at hjælpe med denne analyse. Men disse tal vil typisk ikke hjælpe dig med at justere ydelsen af din instans som helhed, medmindre de hjælper med at påpege noget, der tilfældigvis også påvirker hele din arbejdsbyrde. Hvis du ser en forespørgsel fra i går, der kørte i 5 minutter, og bemærker, at dens ventetype var LCK_M_S , hvad vil du gøre ved det nu? Hvordan vil du spore, hvad der faktisk blokerede forespørgslen og forårsagede den ventetype? Det kan være forårsaget af en transaktion, der ikke forpligtede sig af en anden grund, men det kan du ikke se, hvis du ikke kan se hele systemets tilstand og kun fokuserer på individuelle forespørgsler og de ventetider, de har oplevet.
Jason Hall (@SQLSaurus) nævnte noget i forbifarten, som også var interessant for mig. Han sagde, at hvis ventestatistikker på forespørgselsniveau var en så vigtig del af tuningindsatsen, ville denne metode være blevet indbygget i Query Store fra starten. Det er blevet tilføjet for nylig (i SQL Server 2017). Men du får stadig ikke ventestatistikker pr. udførelse; du får gennemsnit over tid, som forespørgselsstatistikken og procedurestatistikken, du ser i DMV'er. Så pludselige uregelmæssigheder kan være tilsyneladende baseret på andre metrics, der fanges pr. forespørgselsudførelse, men ikke baseret på gennemsnit af ventetider, der er trukket over alle henrettelser. Du kan tilpasse rækkevidden, hvor ventetiden samles, men på travle systemer er dette muligvis stadig ikke detaljeret nok til at gøre, hvad du tror, det vil gøre for dig.
Pointen med dette indlæg er at diskutere nogle af de mere almindelige ventetyper, vi ser i vores kundebase, og hvilken slags handlinger du kan (og ikke bør) tage, når de sker. Vi har en database med anonyme ventestatistikker, som vi har indsamlet fra vores Cloud Sync-kunder i et stykke tid, og siden maj 2017 har vi vist alle, hvordan disse ser ud på SQLskills Waits Library.
Paul fortæller om årsagen bag biblioteket og også om vores integration med denne gratis tjeneste. Grundlæggende slår du op på en ventetype, du oplever eller er nysgerrig efter, og han forklarer, hvad det betyder, og hvad du kan gøre ved det. Vi supplerer denne kvalitative info med et diagram, der viser, hvor udbredt den nuværende ventetid er blandt vores brugerbase, sammenlignet med alle de andre ventetyper, vi ser, så du hurtigt kan se, om du har at gøre med en almindelig ventetype eller noget lidt mere eksotisk. (Husk, at SQL Sentry ikke inkluderer godartede, baggrunds- og køventer, der svarer til støj, og at de fleste af scripts derude filtreres fra, såsom WAITFOR eller LAZYWRITER_SLEEP – disse er bare ikke kilder til ydeevneproblemer.)
Her er et eksempeldiagram for CXPACKET , den mest almindelige ventetype derude:
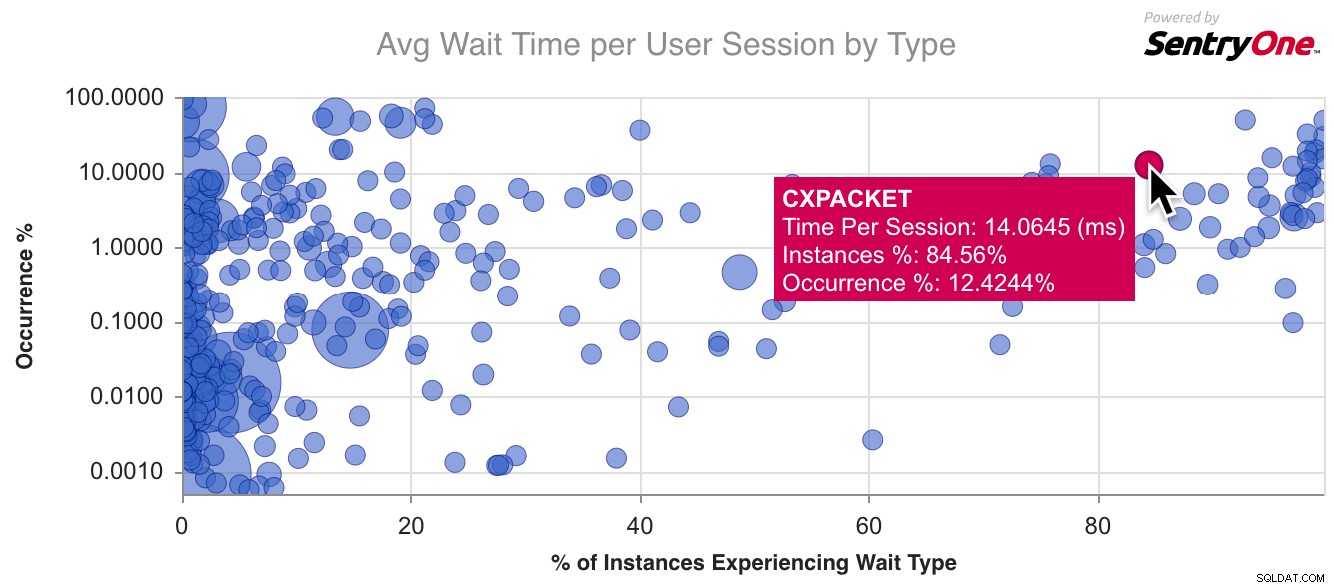
Jeg begyndte at gå lidt længere end dette, kortlagde nogle af de mere almindelige ventetyper og noterede nogle af de egenskaber, de delte. Oversat til spørgsmål, en tuner kan have om en ventetype, de oplever:
- Kan ventetypen løses på forespørgselsniveau?
- Er det sandsynligt, at kernesymptomet på ventetiden påvirker andre forespørgsler?
- Er det sandsynligt, at du får brug for flere oplysninger uden for konteksten af en enkelt forespørgsel og de ventetyper, den oplevede for at "løse" problemet?
Da jeg satte mig for at skrive dette indlæg, var mit mål bare at gruppere de mest almindelige ventetyper sammen og derefter begynde at skrive noter om dem i forbindelse med ovenstående spørgsmål. Jason trak de mest almindelige fra biblioteket, og så tegnede jeg noget kyllingeskrab på en tavle, som jeg senere fik ryddet lidt op på. Denne indledende forskning førte til en tale, som Jason holdt på det seneste TechOutbound SQL Cruise i Alaska. Jeg er lidt flov over, at han holdt en snak flere måneder før, jeg kunne afslutte dette indlæg, så lad os bare komme videre med det. Her er de største ventetider, vi ser (som stort set matcher Pauls undersøgelse fra 2014), mine svar på ovenstående spørgsmål og nogle kommentarer til hver:
For at interagere med linkene i tabellen nedenfor, besøg venligst denne side på en bredere skærm.
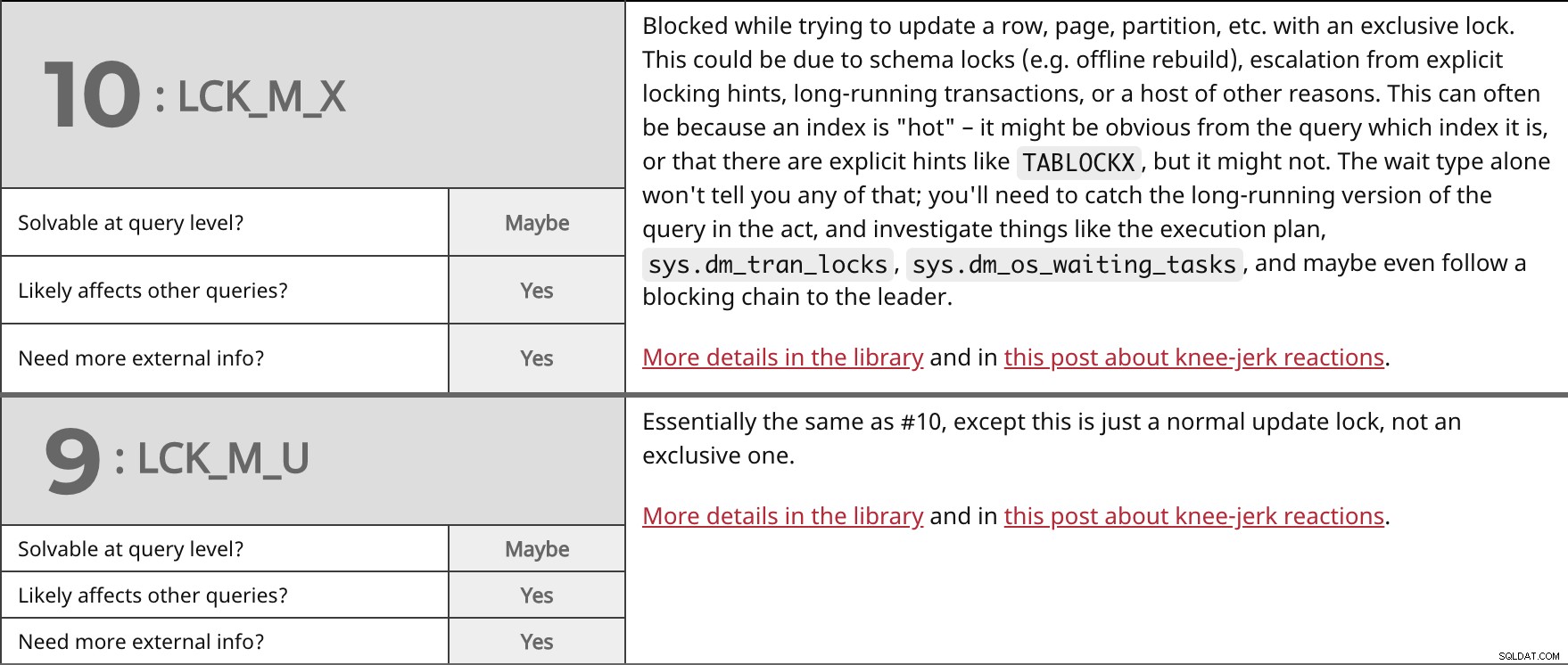
Blokeret under forsøg på at opdatere en række, side, partition osv. med en eksklusiv lås. Dette kan skyldes skemalåse (f.eks. offline genopbygning), eskalering fra eksplicitte låsetip, langvarige transaktioner eller en lang række andre årsager. Dette kan ofte skyldes, at et indeks er "hot" – det kan være tydeligt fra forespørgslen, hvilket indeks det er, eller at der er eksplicitte hints som TABLOCKX , men det er det måske ikke. Ventetypen alene vil ikke fortælle dig noget af det; du bliver nødt til at fange den langvarige version af forespørgslen i akt og undersøge ting som f.eks. eksekveringsplanen, sys.dm_tran_locks , sys.dm_os_waiting_tasks , og måske endda følge en blokerende kæde til lederen. Flere detaljer på biblioteket og i dette indlæg om knæfald. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Ja | ||
| Har du brug for mere ekstern information? | Ja | |
|
I bund og grund det samme som #10, bortset fra at dette kun er en normal opdateringslås, ikke en eksklusiv. Flere detaljer på biblioteket og i dette indlæg om knæfald. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Ja | ||
| Har du brug for mere ekstern information? | Ja | |
|
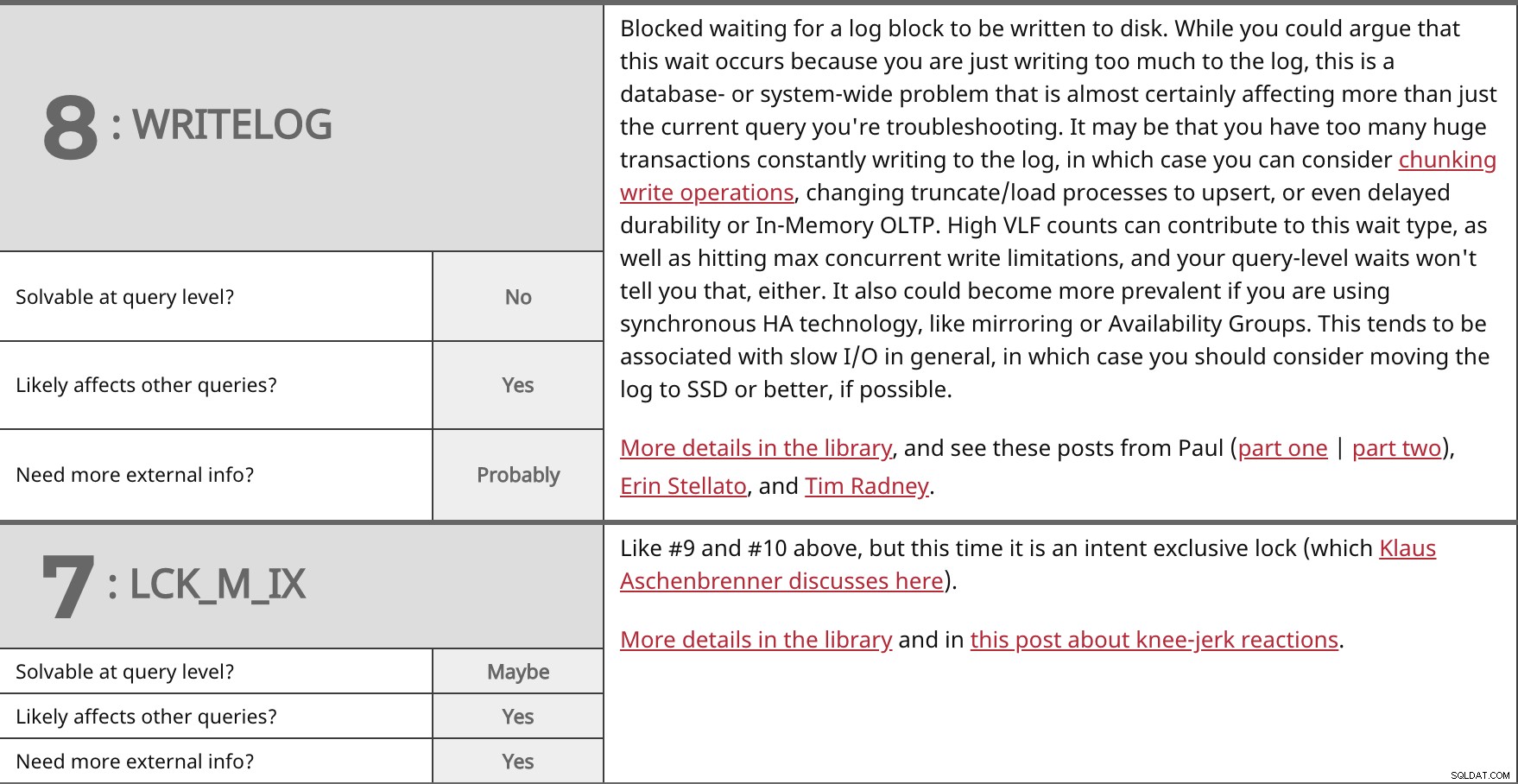
Blokeret venter på, at en logblok bliver skrevet til disken. Selvom du kan argumentere for, at denne ventetid opstår, fordi du bare skriver for meget til loggen, er dette et database- eller systemdækkende problem, der næsten helt sikkert påvirker mere end blot den aktuelle forespørgsel, du fejlfinder. Det kan være, at du har for mange enorme transaktioner, der konstant skriver til loggen, i hvilket tilfælde du kan overveje at dele skriveoperationer, ændre trunkerings-/indlæsningsprocesser for at ophæve, eller endda forsinket holdbarhed eller OLTP i hukommelsen. Høje VLF-tal kan bidrage til denne ventetype, såvel som at ramme maksimale samtidige skrivebegrænsninger, og dine ventetider på forespørgselsniveau fortæller dig det heller ikke. Det kan også blive mere udbredt, hvis du bruger synkron HA-teknologi, såsom spejling eller tilgængelighedsgrupper. Dette har en tendens til at være forbundet med langsom I/O generelt, i hvilket tilfælde du bør overveje at flytte loggen til SSD eller bedre, hvis det er muligt. Flere detaljer i biblioteket, og se disse indlæg fra Paul (del et | del to), Erin Stellato og Tim Radney. | ||
| Løselig på forespørgselsniveau? | Nej | |
| Ja | ||
| Har du brug for mere ekstern information? | Sandsynligvis | |
|
Som #9 og #10 ovenfor, men denne gang er det en hensigtseksklusiv lås (som Klaus Aschenbrenner diskuterer her). Flere detaljer på biblioteket og i dette indlæg om knæfald. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Ja | ||
| Har du brug for mere ekstern information? | Ja | |
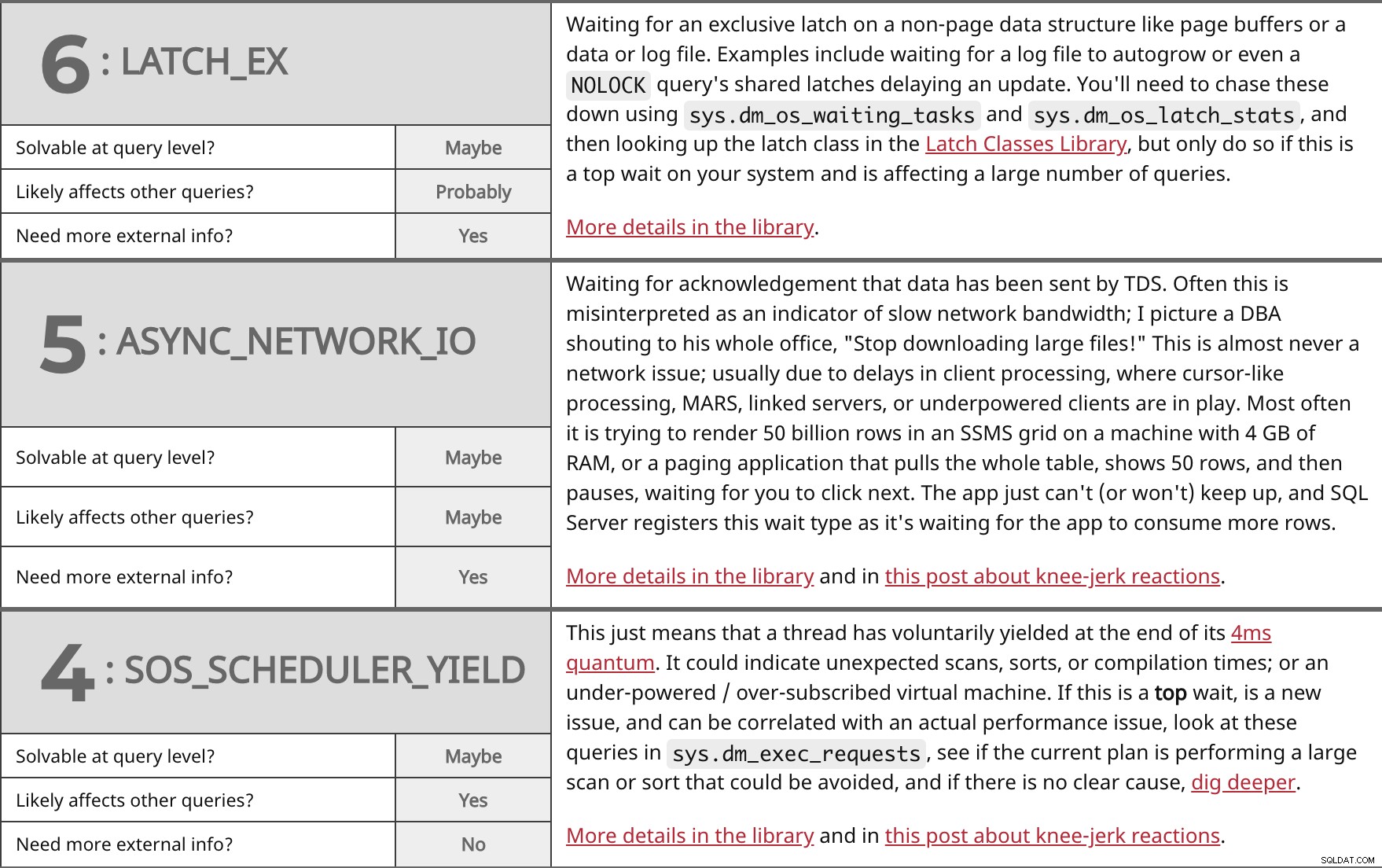
Venter på en eksklusiv lås på en ikke-sidedatastruktur som sidebuffere eller en data- eller logfil. Eksempler inkluderer at vente på, at en logfil automatisk vokser eller endda en NOLOCK forespørgsels delte låse, der forsinker en opdatering. Du bliver nødt til at jage disse ned ved hjælp af sys.dm_os_waiting_tasks og sys.dm_os_latch_stats , og slå derefter låseklassen op i Latch Classes-biblioteket, men gør det kun, hvis dette er en top ventetid på dit system og påvirker et stort antal forespørgsler. Flere detaljer i biblioteket. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Sandsynligvis | ||
| Har du brug for mere ekstern information? | Ja | |
|
Venter på bekræftelse af, at data er blevet sendt af TDS. Ofte misfortolkes dette som en indikator for langsom netværksbåndbredde; Jeg ser for mig en DBA, der råber til hele sit kontor:"Stop med at downloade store filer!" Dette er næsten aldrig et netværksproblem; normalt på grund af forsinkelser i klientbehandling, hvor markørlignende behandling, MARS, linkede servere eller understrømsklienter er i spil. Oftest forsøger det at gengive 50 milliarder rækker i et SSMS-gitter på en maskine med 4 GB RAM, eller en personsøgningsapplikation, der trækker hele tabellen, viser 50 rækker og derefter holder pause og venter på, at du klikker på næste. Appen kan bare ikke (eller vil) ikke følge med, og SQL Server registrerer denne ventetype, da den venter på, at appen bruger flere rækker. Flere detaljer på biblioteket og i dette indlæg om knæfald. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Måske | ||
| Har du brug for mere ekstern information? | Ja | |
Dette betyder blot, at en tråd frivilligt har givet efter i slutningen af dens 4ms kvante. Det kunne indikere uventede scanninger, sorteringer eller kompileringstider; eller en virtuel maskine med understrøm/overtilmeldt. Hvis dette er en top vent, er et nyt problem og kan korreleres med et faktisk ydelsesproblem, se på disse forespørgsler i sys.dm_exec_requests , se, om den nuværende plan udfører en stor scanning eller sortering, som kunne undgås, og hvis der ikke er nogen klar årsag, grav dybere. Flere detaljer på biblioteket og i dette indlæg om knæfald. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Ja | ||
| Har du brug for mere ekstern information? | Nej | |
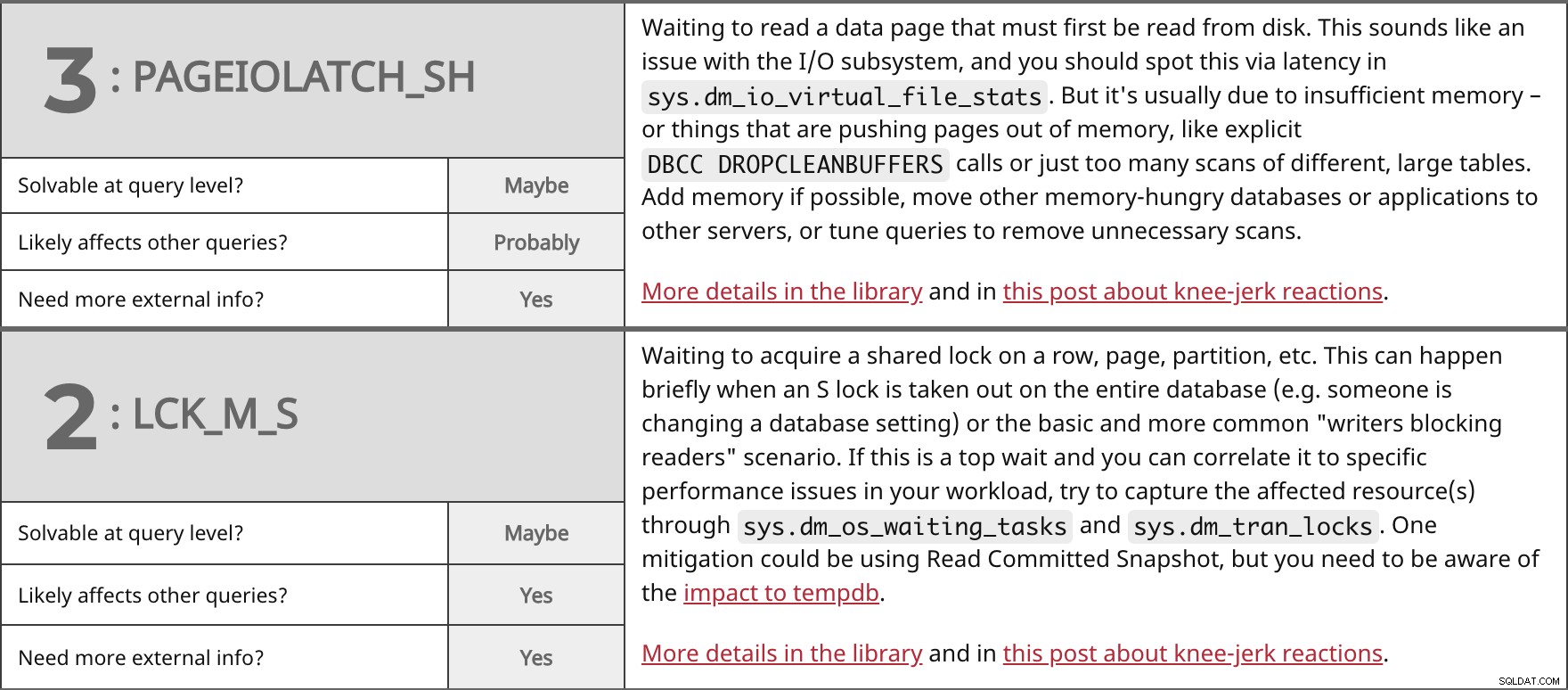
Venter på at læse en dataside, der først skal læses fra disken. Dette lyder som et problem med I/O-undersystemet, og du bør opdage dette via latency i sys.dm_io_virtual_file_stats . Men det er normalt på grund af utilstrækkelig hukommelse – eller ting, der skubber sider ud af hukommelsen, såsom eksplicitte DBCC DROPCLEANBUFFERS opkald eller bare for mange scanninger af forskellige, store borde. Tilføj hukommelse, hvis det er muligt, flyt andre hukommelseskrævende databaser eller applikationer til andre servere, eller juster forespørgsler for at fjerne unødvendige scanninger. Flere detaljer på biblioteket og i dette indlæg om knæfald. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Sandsynligvis | ||
| Har du brug for mere ekstern information? | Ja | |
Venter på at erhverve en delt lås på en række, side, partition osv. Dette kan ske kortvarigt, når en S-lås udtages på hele databasen (f.eks. er der nogen, der skifter en databaseindstilling) eller det grundlæggende og mere almindelige scenarie "forfattere blokerer læsere". Hvis dette er en top ventetid, og du kan relatere det til specifikke ydeevneproblemer i din arbejdsbyrde, så prøv at fange de berørte ressourcer gennem sys.dm_os_waiting_tasks og sys.dm_tran_locks . En afbødning kunne være at bruge Read Committed Snapshot, men du skal være opmærksom på virkningen af tempdb. Flere detaljer på biblioteket og i dette indlæg om knæfald. | ||
| Løselig på forespørgselsniveau? | Måske | |
| Ja | ||
| Har du brug for mere ekstern information? | Ja | |
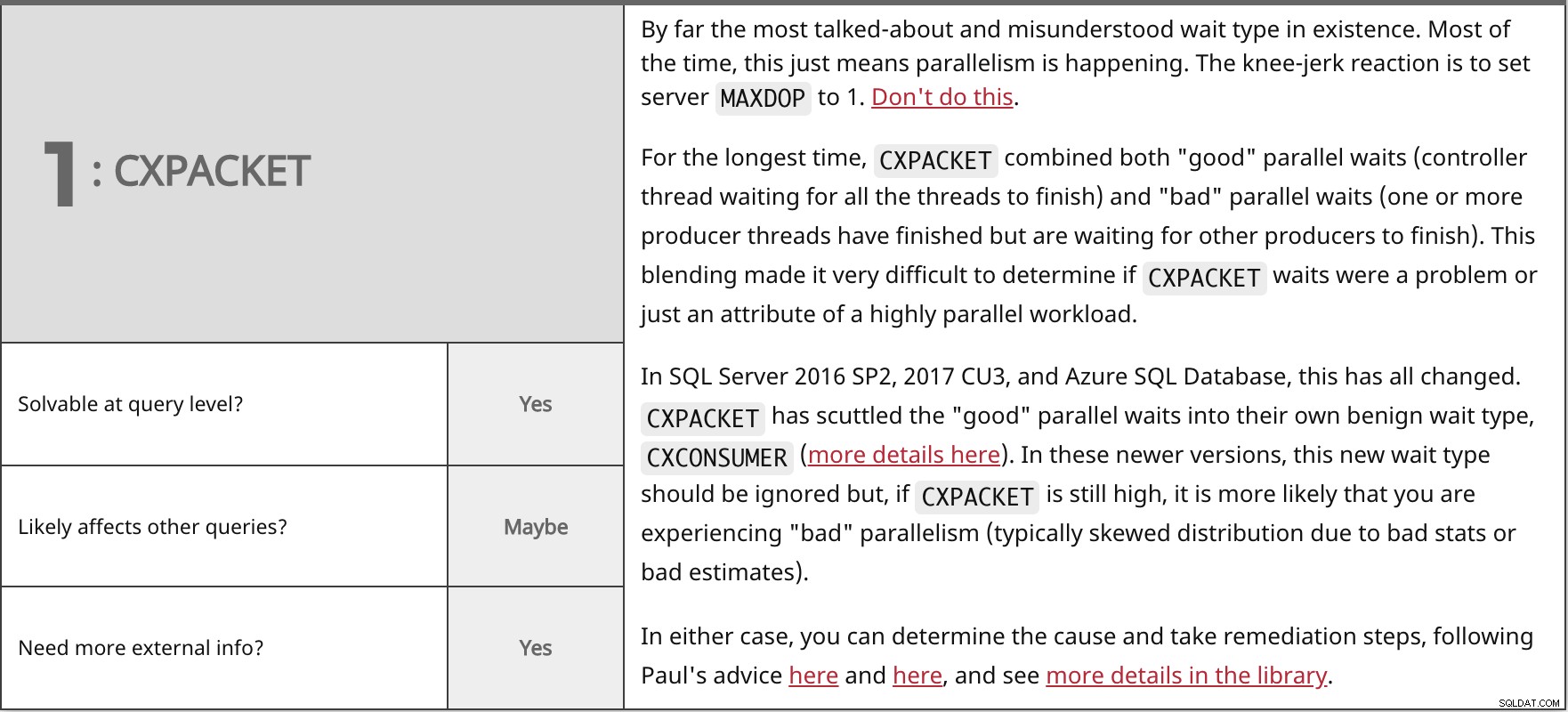
Langt den mest omtalte og misforståede ventetype, der findes. Det meste af tiden betyder dette bare, at der sker parallelisme. Knæfaldsreaktionen er at indstille serveren MAXDOP til 1. Gør ikke dette.
I længst tid,
I SQL Server 2016 SP2, 2017 CU3 og Azure SQL Database er alt dette ændret. I begge tilfælde kan du fastslå årsagen og tage afhjælpningstrin ved at følge Pauls råd her og her, og se flere detaljer i biblioteket. | ||
| Løselig på forespørgselsniveau? | Ja | |
| Måske | ||
| Har du brug for mere ekstern information? | Ja | |
Oversigt
I de fleste af disse tilfælde er det bedre at se på ventetider på forekomstniveau og kun skærpe ind på ventetider på forespørgselsniveau, når du fejlfinder specifikke forespørgsler, der udviser ydeevneproblemer uanset ventetype. Det er ting, der dukker op af andre årsager, som f.eks. lang varighed, høj CPU eller høj I/O, og som ikke kan forklares med simplere ting (som en klynget indeksscanning, da du forventede en søgning).
Selv på instansniveau skal du ikke jage hver vent, der bliver den øverste vent på dit system – du vil ALTID har en top ventetid, og du vil aldrig være i stand til at stoppe med at jagte det ned. Sørg for at ignorere godartede ventetider (Paul fører en liste) og kun bekymre dig om ventetider, som du kan forbinde med et faktisk præstationsproblem, du oplever. Hvis CXPACKET ventetiden er høj, hvad så? Er der andre symptomer bortset fra, at det tal er "højt" eller tilfældigvis står øverst på listen?
Det hele kommer ned til, hvorfor du fejlfinder i første omgang. Klager en enkelt bruger over et enkelt tilfælde af en useriøs forespørgsel? Er din server på knæ? noget midt imellem? I det første tilfælde kan det helt sikkert være nyttigt at vide, hvorfor en forespørgsel er langsom, men det er ret dyrt at spore (pyt med det i det uendelige) alle de ventetider, der er forbundet med hver enkelt forespørgsel, hele dagen, hver dag, med en ulige chance for, at du ønsker at vende tilbage og gennemgå dem senere. Hvis det er et gennemgående problem isoleret til den forespørgsel, bør du være i stand til at bestemme, hvad der gør forespørgslen langsom ved at køre den igen og indsamle eksekveringsplanen, kompileringstiden og andre runtime-metrics. Hvis det var en engangsting, der skete sidste tirsdag, uanset om du har ventetid på den enkelte forekomst af forespørgslen eller ej, kan du muligvis ikke løse problemet uden mere kontekst. Måske var der blokering, men du ved ikke med hvad, eller måske var der en I/O-spids, men du bliver nødt til at spore problemet separat. Ventetypen i sig selv giver normalt bare ikke nok information, bortset fra i bedste fald en henvisning til noget andet.
Selvfølgelig skal jeg også tjene mit hold her. Vores flagskibsprodukt, SQL Sentry, har en holistisk tilgang til overvågning. Vi indsamler ventestatistikker for hele instansen, kategoriserer dem for dig og tegner dem på vores dashboard:
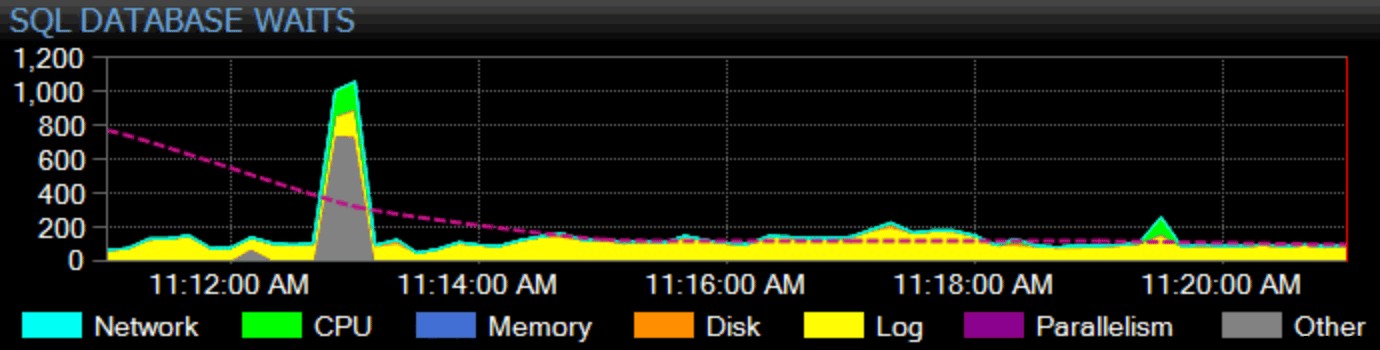
Du kan tilpasse, hvordan enhver individuel ventetid kategoriseres, og om den pågældende kategori overhovedet vises på dashboardet. Du kan sammenligne den aktuelle ventestatistik med indbyggede eller tilpassede basislinjer og endda opsætte advarsler eller handlinger, når de overstiger en defineret afvigelse fra basislinjen. Og måske vigtigst af alt, kan du se på et datapunkt fra fortiden og synkronisere hele dashboardet til det tidspunkt, så du kan fange hele den omgivende kontekst og enhver anden situation, der kan have påvirket problemet. Når du finder mere detaljerede ting at fokusere på, såsom blokering, høj disklatens eller forespørgsler med høj I/O eller lang varighed, kan du bore i disse metrics og komme til roden af problemet ret hurtigt.
For mere information om både generelle ventestatistikker og vores løsning specifikt, kan du se Kevin Klines hvidbog, Troubleshooting SQL Server Wait Stats, og du kan downloade et todelt webinar præsenteret af Paul Randal, Andy Yun (@SQLBek), og Andy Mallon (@AMtwo):
- Del 1:Fejlfinding af ydeevne ved hjælp af ventestatistikker
- Del 2:Hurtig analyse af ventestatistikker med SentryOne
Og hvis du vil give SentryOne-platformen et spin, kan du komme i gang her med et tidsbegrænset tilbud:
Download en 15-dages gratis prøveperiode